 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplex Momentum for Learning in Games
Feb 16, 2021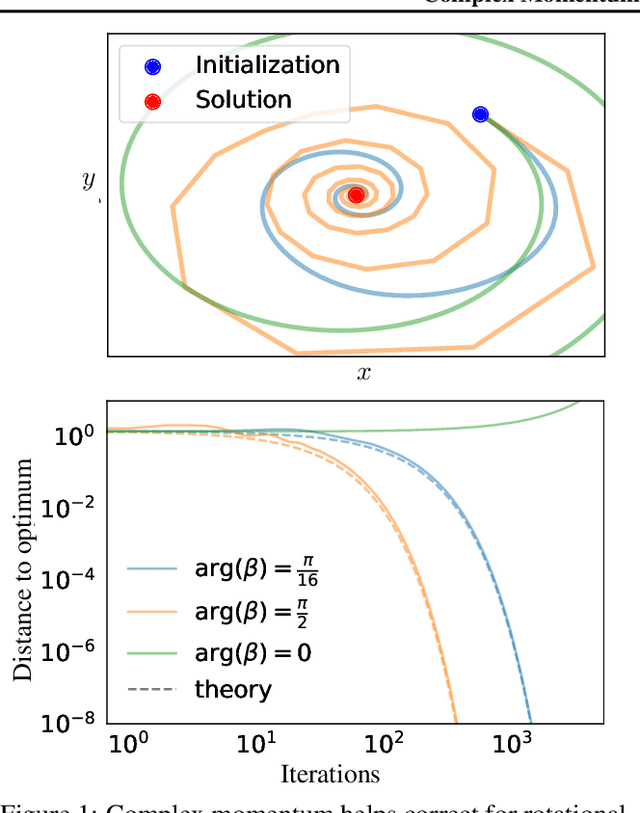

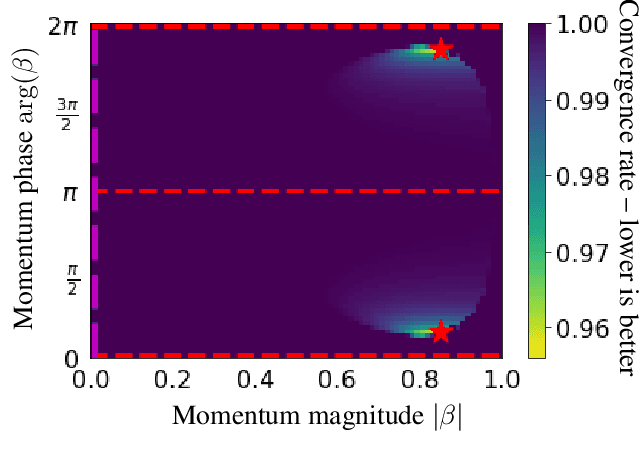

We generalize gradient descent with momentum for learning in differentiable games to have complex-valued momentum. We give theoretical motivation for our method by proving convergence on bilinear zero-sum games for simultaneous and alternating updates. Our method gives real-valued parameter updates, making it a drop-in replacement for standard optimizers. We empirically demonstrate that complex-valued momentum can improve convergence in adversarial games - like generative adversarial networks - by showing we can find better solutions with an almost identical computational cost. We also show a practical generalization to a complex-valued Adam variant, which we use to train BigGAN to better inception scores on CIFAR-10.
Understanding and mitigating exploding inverses in invertible neural networks
Jun 16, 2020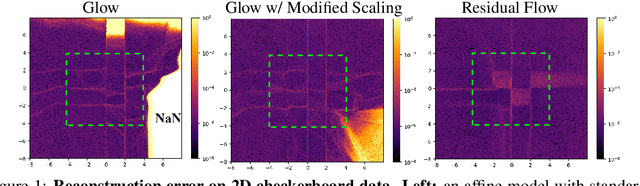
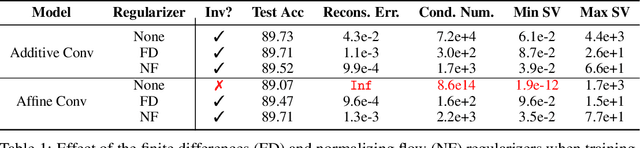

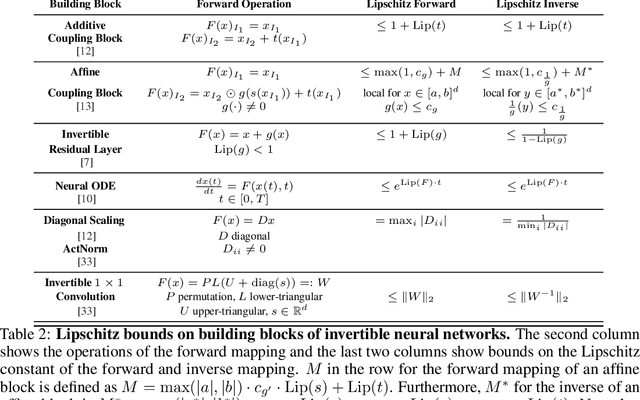
Invertible neural networks (INNs) have been used to design generative models, implement memory-saving gradient computation, and solve inverse problems. In this work, we show that commonly-used INN architectures suffer from exploding inverses and are thus prone to becoming numerically non-invertible. Across a wide range of INN use-cases, we reveal failures including the non-applicability of the change-of-variables formula on in- and out-of-distribution (OOD) data, incorrect gradients for memory-saving backprop, and the inability to sample from normalizing flow models. We further derive bi-Lipschitz properties of atomic building blocks of common architectures. These insights into the stability of INNs then provide ways forward to remedy these failures. For tasks where local invertibility is sufficient, like memory-saving backprop, we propose a flexible and efficient regularizer. For problems where global invertibility is necessary, such as applying normalizing flows on OOD data, we show the importance of designing stable INN building blocks.
Optimizing Millions of Hyperparameters by Implicit Differentiation
Nov 06, 2019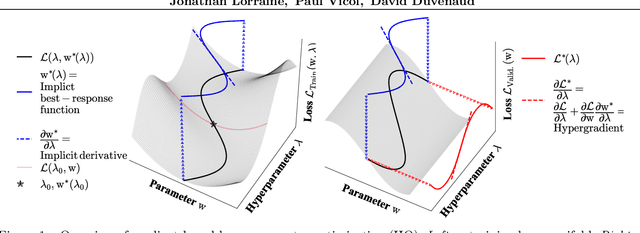
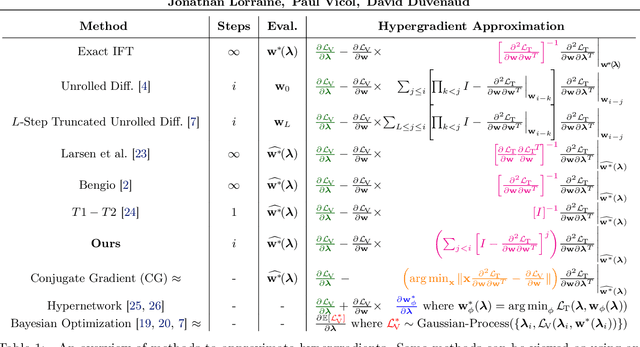
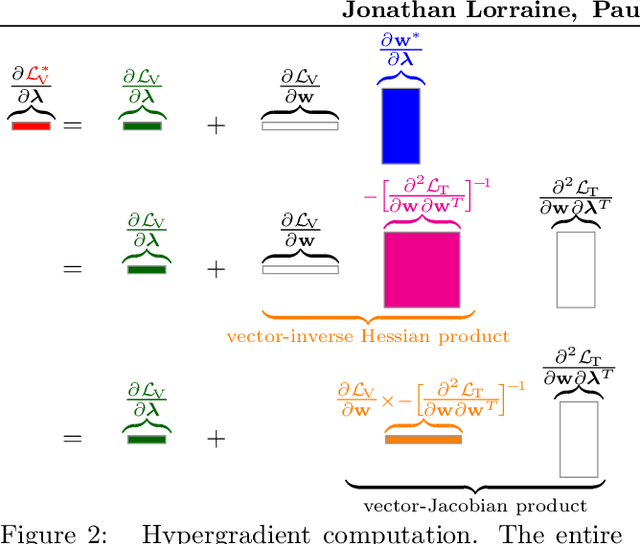
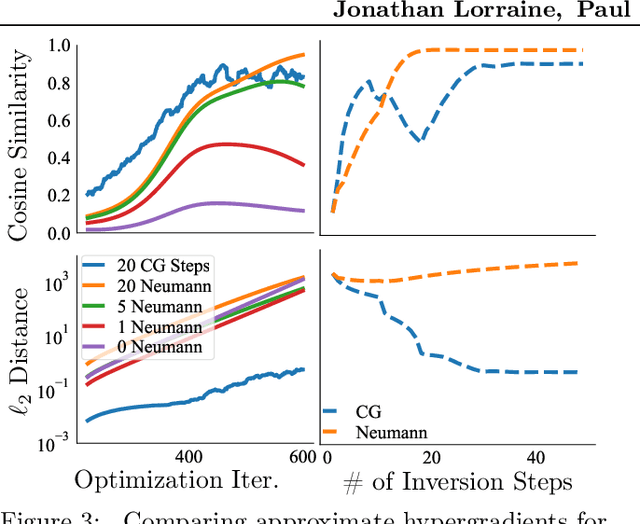
We propose an algorithm for inexpensive gradient-based hyperparameter optimization that combines the implicit function theorem (IFT) with efficient inverse Hessian approximations. We present results about the relationship between the IFT and differentiating through optimization, motivating our algorithm. We use the proposed approach to train modern network architectures with millions of weights and millions of hyper-parameters. For example, we learn a data-augmentation network - where every weight is a hyperparameter tuned for validation performance - outputting augmented training examples. Jointly tuning weights and hyperparameters with our approach is only a few times more costly in memory and compute than standard training.
Self-Tuning Networks: Bilevel Optimization of Hyperparameters using Structured Best-Response Functions
Mar 07, 2019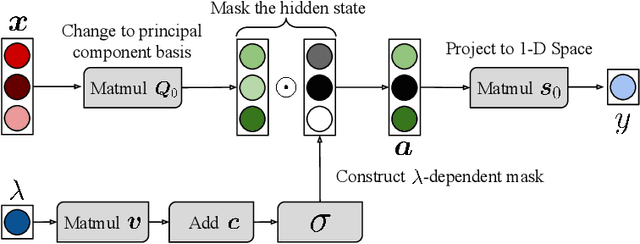
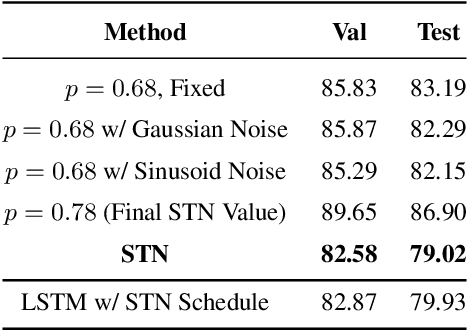
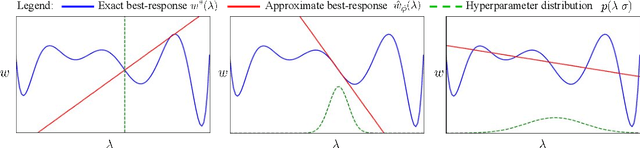
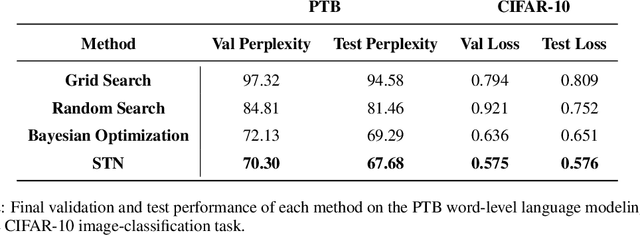
Hyperparameter optimization can be formulated as a bilevel optimization problem, where the optimal parameters on the training set depend on the hyperparameters. We aim to adapt regularization hyperparameters for neural networks by fitting compact approximations to the best-response function, which maps hyperparameters to optimal weights and biases. We show how to construct scalable best-response approximations for neural networks by modeling the best-response as a single network whose hidden units are gated conditionally on the regularizer. We justify this approximation by showing the exact best-response for a shallow linear network with L2-regularized Jacobian can be represented by a similar gating mechanism. We fit this model using a gradient-based hyperparameter optimization algorithm which alternates between approximating the best-response around the current hyperparameters and optimizing the hyperparameters using the approximate best-response function. Unlike other gradient-based approaches, we do not require differentiating the training loss with respect to the hyperparameters, allowing us to tune discrete hyperparameters, data augmentation hyperparameters, and dropout probabilities. Because the hyperparameters are adapted online, our approach discovers hyperparameter schedules that can outperform fixed hyperparameter values. Empirically, our approach outperforms competing hyperparameter optimization methods on large-scale deep learning problems. We call our networks, which update their own hyperparameters online during training, Self-Tuning Networks (STNs).
Reversible Recurrent Neural Networks
Oct 25, 2018

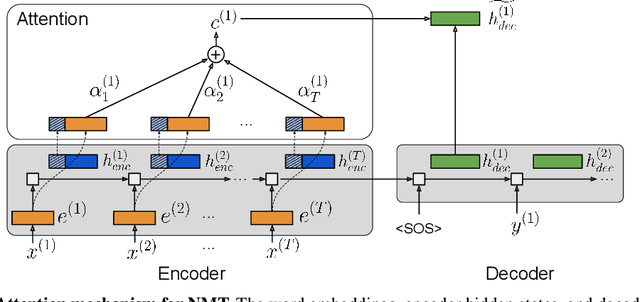
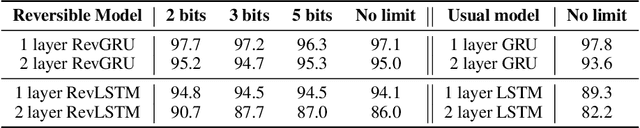
Recurrent neural networks (RNNs) provide state-of-the-art performance in processing sequential data but are memory intensive to train, limiting the flexibility of RNN models which can be trained. Reversible RNNs---RNNs for which the hidden-to-hidden transition can be reversed---offer a path to reduce the memory requirements of training, as hidden states need not be stored and instead can be recomputed during backpropagation. We first show that perfectly reversible RNNs, which require no storage of the hidden activations, are fundamentally limited because they cannot forget information from their hidden state. We then provide a scheme for storing a small number of bits in order to allow perfect reversal with forgetting. Our method achieves comparable performance to traditional models while reducing the activation memory cost by a factor of 10--15. We extend our technique to attention-based sequence-to-sequence models, where it maintains performance while reducing activation memory cost by a factor of 5--10 in the encoder, and a factor of 10--15 in the decoder.
Adversarial Distillation of Bayesian Neural Network Posteriors
Jun 27, 2018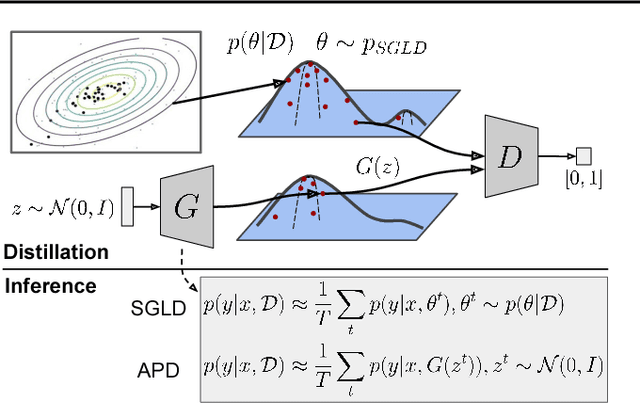
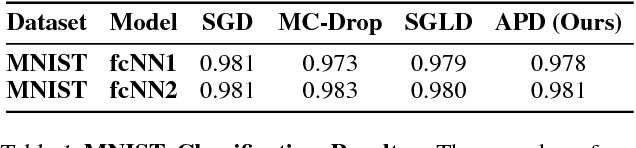
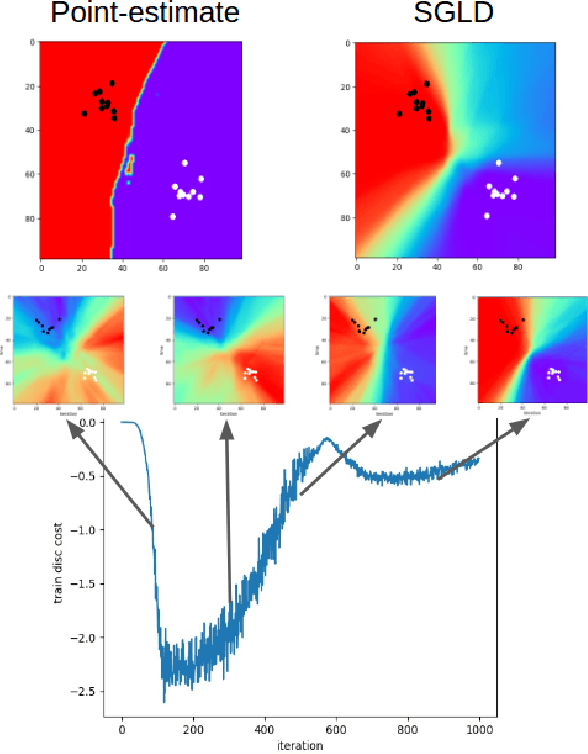
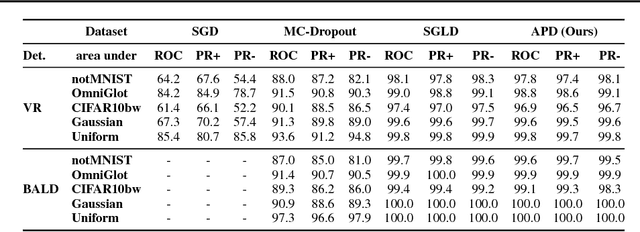
Bayesian neural networks (BNNs) allow us to reason about uncertainty in a principled way. Stochastic Gradient Langevin Dynamics (SGLD) enables efficient BNN learning by drawing samples from the BNN posterior using mini-batches. However, SGLD and its extensions require storage of many copies of the model parameters, a potentially prohibitive cost, especially for large neural networks. We propose a framework, Adversarial Posterior Distillation, to distill the SGLD samples using a Generative Adversarial Network (GAN). At test-time, samples are generated by the GAN. We show that this distillation framework incurs no loss in performance on recent BNN applications including anomaly detection, active learning, and defense against adversarial attacks. By construction, our framework not only distills the Bayesian predictive distribution, but the posterior itself. This allows one to compute quantities such as the approximate model variance, which is useful in downstream tasks. To our knowledge, these are the first results applying MCMC-based BNNs to the aforementioned downstream applications.
MovieGraphs: Towards Understanding Human-Centric Situations from Videos
Apr 15, 2018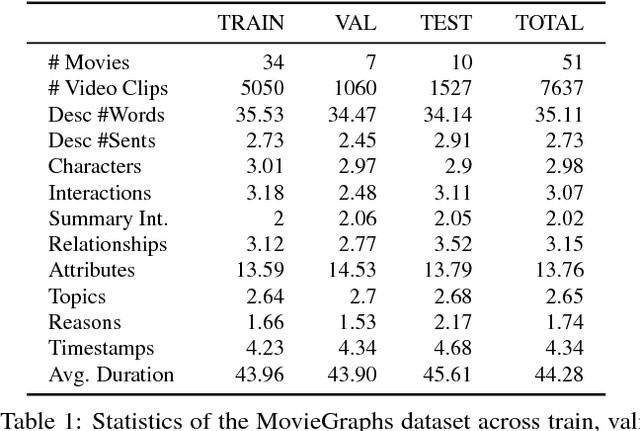
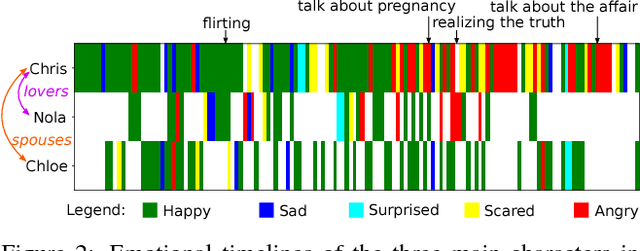
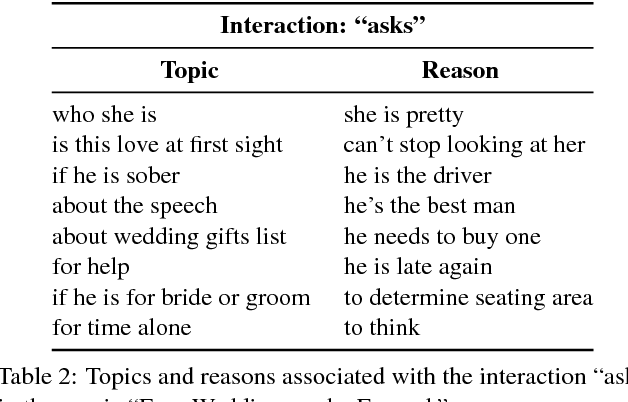
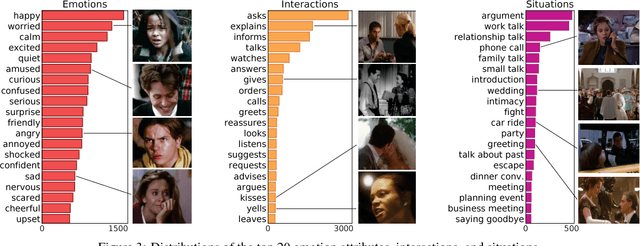
There is growing interest in artificial intelligence to build socially intelligent robots. This requires machines to have the ability to "read" people's emotions, motivations, and other factors that affect behavior. Towards this goal, we introduce a novel dataset called MovieGraphs which provides detailed, graph-based annotations of social situations depicted in movie clips. Each graph consists of several types of nodes, to capture who is present in the clip, their emotional and physical attributes, their relationships (i.e., parent/child), and the interactions between them. Most interactions are associated with topics that provide additional details, and reasons that give motivations for actions. In addition, most interactions and many attributes are grounded in the video with time stamps. We provide a thorough analysis of our dataset, showing interesting common-sense correlations between different social aspects of scenes, as well as across scenes over time. We propose a method for querying videos and text with graphs, and show that: 1) our graphs contain rich and sufficient information to summarize and localize each scene; and 2) subgraphs allow us to describe situations at an abstract level and retrieve multiple semantically relevant situations. We also propose methods for interaction understanding via ordering, and reason understanding. MovieGraphs is the first benchmark to focus on inferred properties of human-centric situations, and opens up an exciting avenue towards socially-intelligent AI agents.
Flipout: Efficient Pseudo-Independent Weight Perturbations on Mini-Batches
Apr 02, 2018
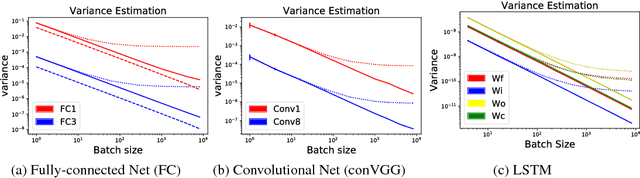
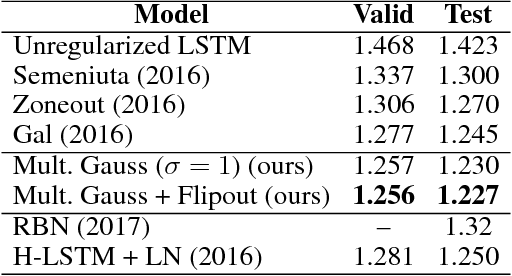
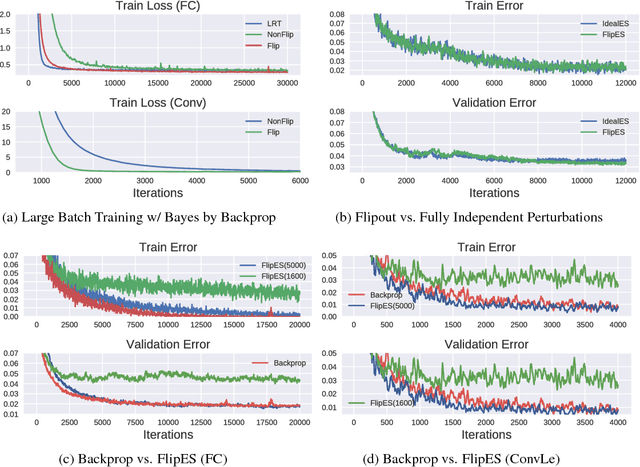
Stochastic neural net weights are used in a variety of contexts, including regularization, Bayesian neural nets, exploration in reinforcement learning, and evolution strategies. Unfortunately, due to the large number of weights, all the examples in a mini-batch typically share the same weight perturbation, thereby limiting the variance reduction effect of large mini-batches. We introduce flipout, an efficient method for decorrelating the gradients within a mini-batch by implicitly sampling pseudo-independent weight perturbations for each example. Empirically, flipout achieves the ideal linear variance reduction for fully connected networks, convolutional networks, and RNNs. We find significant speedups in training neural networks with multiplicative Gaussian perturbations. We show that flipout is effective at regularizing LSTMs, and outperforms previous methods. Flipout also enables us to vectorize evolution strategies: in our experiments, a single GPU with flipout can handle the same throughput as at least 40 CPU cores using existing methods, equivalent to a factor-of-4 cost reduction on Amazon Web Services.