 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayerwise Dynamics for In-Context Classification in Transformers
Apr 13, 2026Transformers can perform in-context classification from a few labeled examples, yet the inference-time algorithm remains opaque. We study multi-class linear classification in the hard no-margin regime and make the computation identifiable by enforcing feature- and label-permutation equivariance at every layer. This enables interpretability while maintaining functional equivalence and yields highly structured weights. From these models we extract an explicit depth-indexed recursion: an end-to-end identified, emergent update rule inside a softmax transformer, to our knowledge the first of its kind. Attention matrices formed from mixed feature-label Gram structure drive coupled updates of training points, labels, and the test probe. The resulting dynamics implement a geometry-driven algorithmic motif, which can provably amplify class separation and yields robust expected class alignment.
Sparse tree-based initialization for neural networks
Sep 30, 2022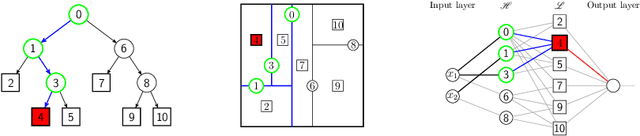
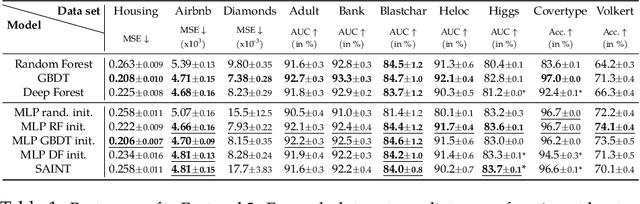
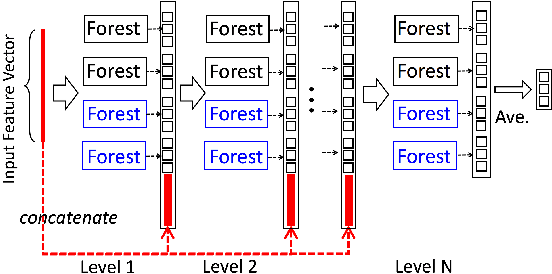
Dedicated neural network (NN) architectures have been designed to handle specific data types (such as CNN for images or RNN for text), which ranks them among state-of-the-art methods for dealing with these data. Unfortunately, no architecture has been found for dealing with tabular data yet, for which tree ensemble methods (tree boosting, random forests) usually show the best predictive performances. In this work, we propose a new sparse initialization technique for (potentially deep) multilayer perceptrons (MLP): we first train a tree-based procedure to detect feature interactions and use the resulting information to initialize the network, which is subsequently trained via standard stochastic gradient strategies. Numerical experiments on several tabular data sets show that this new, simple and easy-to-use method is a solid concurrent, both in terms of generalization capacity and computation time, to default MLP initialization and even to existing complex deep learning solutions. In fact, this wise MLP initialization raises the resulting NN methods to the level of a valid competitor to gradient boosting when dealing with tabular data. Besides, such initializations are able to preserve the sparsity of weights introduced in the first layers of the network through training. This fact suggests that this new initializer operates an implicit regularization during the NN training, and emphasizes that the first layers act as a sparse feature extractor (as for convolutional layers in CNN).