 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSINCERE: Supervised Information Noise-Contrastive Estimation REvisited
Sep 25, 2023



The information noise-contrastive estimation (InfoNCE) loss function provides the basis of many self-supervised deep learning methods due to its strong empirical results and theoretic motivation. Previous work suggests a supervised contrastive (SupCon) loss to extend InfoNCE to learn from available class labels. This SupCon loss has been widely-used due to reports of good empirical performance. However, in this work we suggest that the specific SupCon loss formulated by prior work has questionable theoretic justification, because it can encourage images from the same class to repel one another in the learned embedding space. This problematic behavior gets worse as the number of inputs sharing one class label increases. We propose the Supervised InfoNCE REvisited (SINCERE) loss as a remedy. SINCERE is a theoretically justified solution for a supervised extension of InfoNCE that never causes images from the same class to repel one another. We further show that minimizing our new loss is equivalent to maximizing a bound on the KL divergence between class conditional embedding distributions. We compare SINCERE and SupCon losses in terms of learning trajectories during pretraining and in ultimate linear classifier performance after finetuning. Our proposed SINCERE loss better separates embeddings from different classes during pretraining while delivering competitive accuracy.
NovelCraft: A Dataset for Novelty Detection and Discovery in Open Worlds
Jun 23, 2022
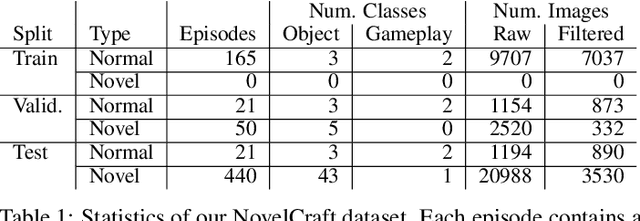
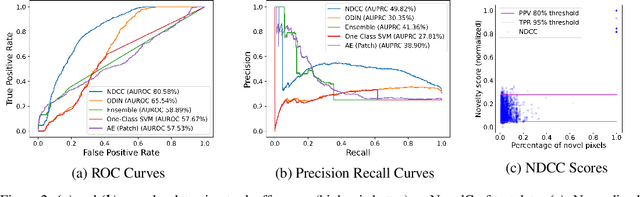
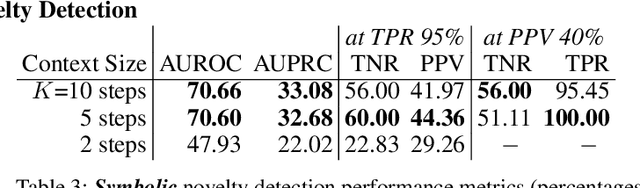
In order for artificial agents to perform useful tasks in changing environments, they must be able to both detect and adapt to novelty. However, visual novelty detection research often only evaluates on repurposed datasets such as CIFAR-10 originally intended for object classification. This practice restricts novelties to well-framed images of distinct object types. We suggest that new benchmarks are needed to represent the challenges of navigating an open world. Our new NovelCraft dataset contains multi-modal episodic data of the images and symbolic world-states seen by an agent completing a pogo-stick assembly task within a video game world. In some episodes, we insert novel objects that can impact gameplay. Novelty can vary in size, position, and occlusion within complex scenes. We benchmark state-of-the-art novelty detection and generalized category discovery models with a focus on comprehensive evaluation. Results suggest an opportunity for future research: models aware of task-specific costs of different types of mistakes could more effectively detect and adapt to novelty in open worlds.
Evaluating the Use of Reconstruction Error for Novelty Localization
Jul 28, 2021
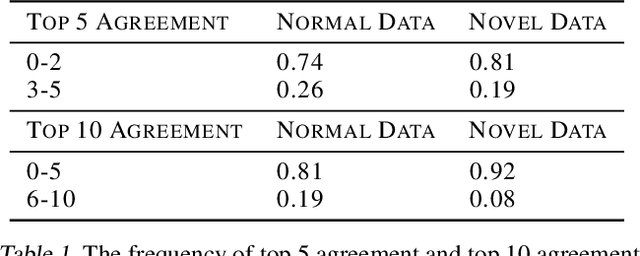
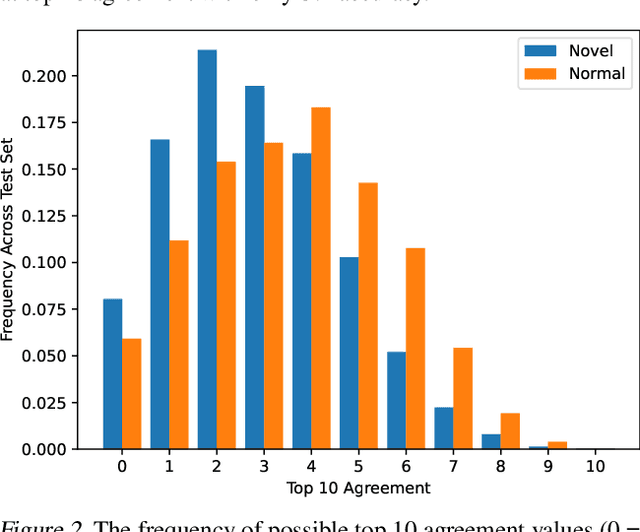
The pixelwise reconstruction error of deep autoencoders is often utilized for image novelty detection and localization under the assumption that pixels with high error indicate which parts of the input image are unfamiliar and therefore likely to be novel. This assumed correlation between pixels with high reconstruction error and novel regions of input images has not been verified and may limit the accuracy of these methods. In this paper we utilize saliency maps to evaluate whether this correlation exists. Saliency maps reveal directly how much a change in each input pixel would affect reconstruction loss, while each pixel's reconstruction error may be attributed to many input pixels when layers are fully connected. We compare saliency maps to reconstruction error maps via qualitative visualizations as well as quantitative correspondence between the top K elements of the maps for both novel and normal images. Our results indicate that reconstruction error maps do not closely correlate with the importance of pixels in the input images, making them insufficient for novelty localization.
4-D Scene Alignment in Surveillance Video
Jun 06, 2019
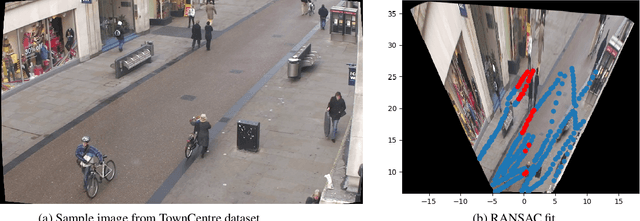

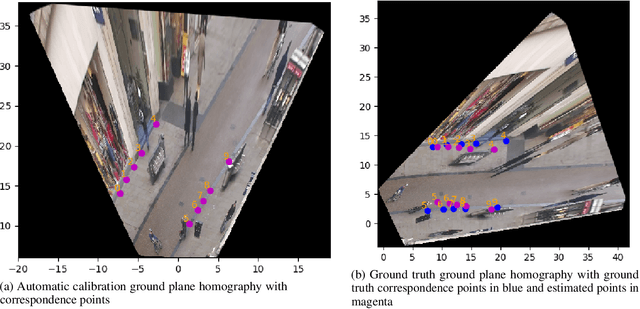
Designing robust activity detectors for fixed camera surveillance video requires knowledge of the 3-D scene. This paper presents an automatic camera calibration process that provides a mechanism to reason about the spatial proximity between objects at different times. It combines a CNN-based camera pose estimator with a vertical scale provided by pedestrian observations to establish the 4-D scene geometry. Unlike some previous methods, the people do not need to be tracked nor do the head and feet need to be explicitly detected. It is robust to individual height variations and camera parameter estimation errors.