 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInductive Framework for Multi-Aspect Streaming Tensor Completion with Side Information
Sep 01, 2018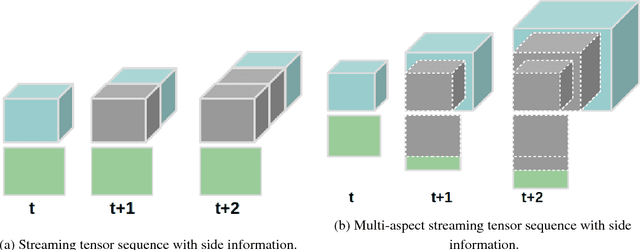

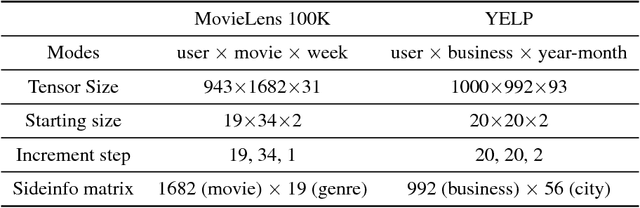
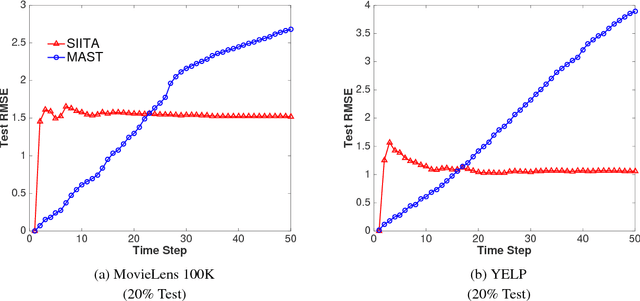
Low rank tensor completion is a well studied problem and has applications in various fields. However, in many real world applications the data is dynamic, i.e., new data arrives at different time intervals. As a result, the tensors used to represent the data grow in size. Besides the tensors, in many real world scenarios, side information is also available in the form of matrices which also grow in size with time. The problem of predicting missing values in the dynamically growing tensor is called dynamic tensor completion. Most of the previous work in dynamic tensor completion make an assumption that the tensor grows only in one mode. To the best of our Knowledge, there is no previous work which incorporates side information with dynamic tensor completion. We bridge this gap in this paper by proposing a dynamic tensor completion framework called Side Information infused Incremental Tensor Analysis (SIITA), which incorporates side information and works for general incremental tensors. We also show how non-negative constraints can be incorporated with SIITA, which is essential for mining interpretable latent clusters. We carry out extensive experiments on multiple real world datasets to demonstrate the effectiveness of SIITA in various different settings.
Lovasz Convolutional Networks
May 29, 2018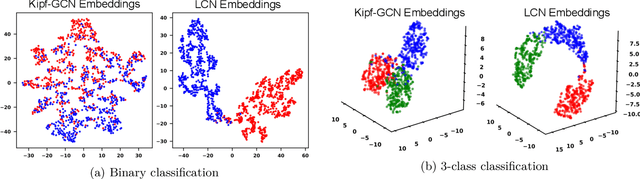
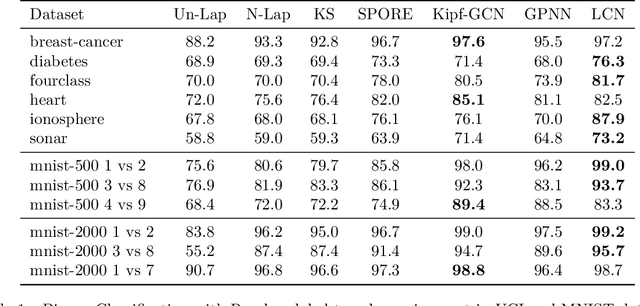
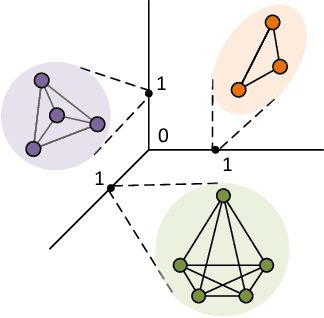

Semi-supervised learning on graph structured data has received significant attention with the recent introduction of graph convolution networks (GCN). While traditional methods have focused on optimizing a loss augmented with Laplacian regularization framework, GCNs perform an implicit Laplacian type regularization to capture local graph structure. In this work, we propose Lovasz convolutional network (LCNs) which are capable of incorporating global graph properties. LCNs achieve this by utilizing Lovasz's orthonormal embeddings of the nodes. We analyse local and global properties of graphs and demonstrate settings where LCNs tend to work better than GCNs. We validate the proposed method on standard random graph models such as stochastic block models (SBM) and certain community structure based graphs where LCNs outperform GCNs and learn more intuitive embeddings. We also perform extensive binary and multi-class classification experiments on real world datasets to demonstrate LCN's effectiveness. In addition to simple graphs, we also demonstrate the use of LCNs on hypergraphs by identifying settings where they are expected to work better than GCNs.
Higher-order Relation Schema Induction using Tensor Factorization with Back-off and Aggregation
May 29, 2018
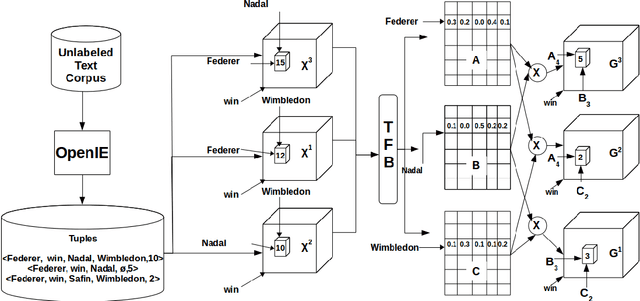
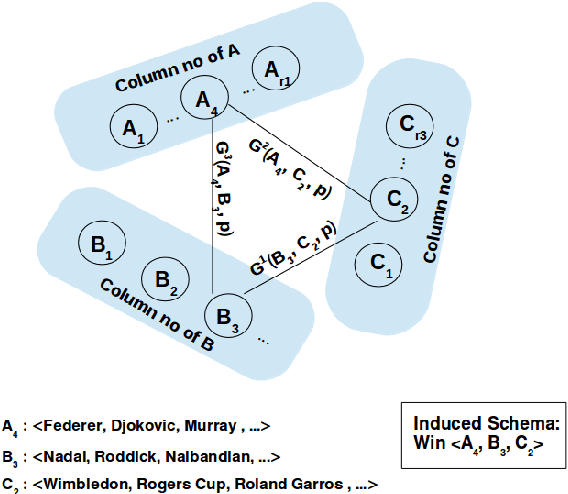

Relation Schema Induction (RSI) is the problem of identifying type signatures of arguments of relations from unlabeled text. Most of the previous work in this area have focused only on binary RSI, i.e., inducing only the subject and object type signatures per relation. However, in practice, many relations are high-order, i.e., they have more than two arguments and inducing type signatures of all arguments is necessary. For example, in the sports domain, inducing a schema win(WinningPlayer, OpponentPlayer, Tournament, Location) is more informative than inducing just win(WinningPlayer, OpponentPlayer). We refer to this problem as Higher-order Relation Schema Induction (HRSI). In this paper, we propose Tensor Factorization with Back-off and Aggregation (TFBA), a novel framework for the HRSI problem. To the best of our knowledge, this is the first attempt at inducing higher-order relation schemata from unlabeled text. Using the experimental analysis on three real world datasets, we show how TFBA helps in dealing with sparsity and induce higher order schemata.
Improving Distantly Supervised Relation Extraction using Word and Entity Based Attention
Apr 19, 2018


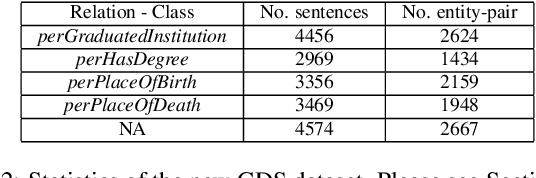
Relation extraction is the problem of classifying the relationship between two entities in a given sentence. Distant Supervision (DS) is a popular technique for developing relation extractors starting with limited supervision. We note that most of the sentences in the distant supervision relation extraction setting are very long and may benefit from word attention for better sentence representation. Our contributions in this paper are threefold. Firstly, we propose two novel word attention models for distantly- supervised relation extraction: (1) a Bi-directional Gated Recurrent Unit (Bi-GRU) based word attention model (BGWA), (2) an entity-centric attention model (EA), and (3) a combination model which combines multiple complementary models using weighted voting method for improved relation extraction. Secondly, we introduce GDS, a new distant supervision dataset for relation extraction. GDS removes test data noise present in all previous distant- supervision benchmark datasets, making credible automatic evaluation possible. Thirdly, through extensive experiments on multiple real-world datasets, we demonstrate the effectiveness of the proposed methods.
CANDiS: Coupled & Attention-Driven Neural Distant Supervision
Oct 26, 2017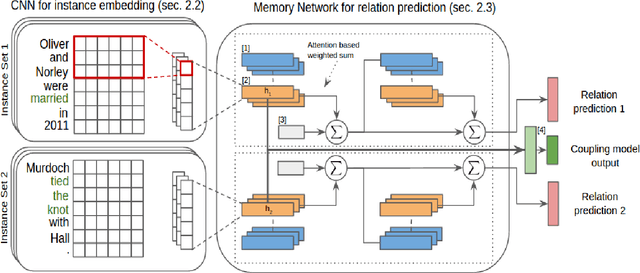

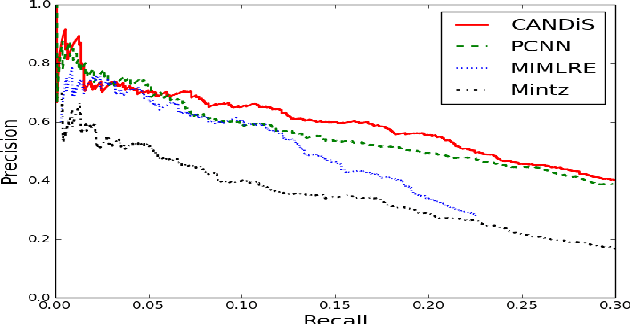
Distant Supervision for Relation Extraction uses heuristically aligned text data with an existing knowledge base as training data. The unsupervised nature of this technique allows it to scale to web-scale relation extraction tasks, at the expense of noise in the training data. Previous work has explored relationships among instances of the same entity-pair to reduce this noise, but relationships among instances across entity-pairs have not been fully exploited. We explore the use of inter-instance couplings based on verb-phrase and entity type similarities. We propose a novel technique, CANDiS, which casts distant supervision using inter-instance coupling into an end-to-end neural network model. CANDiS incorporates an attention module at the instance-level to model the multi-instance nature of this problem. CANDiS outperforms existing state-of-the-art techniques on a standard benchmark dataset.
KGEval: Estimating Accuracy of Automatically Constructed Knowledge Graphs
Dec 01, 2016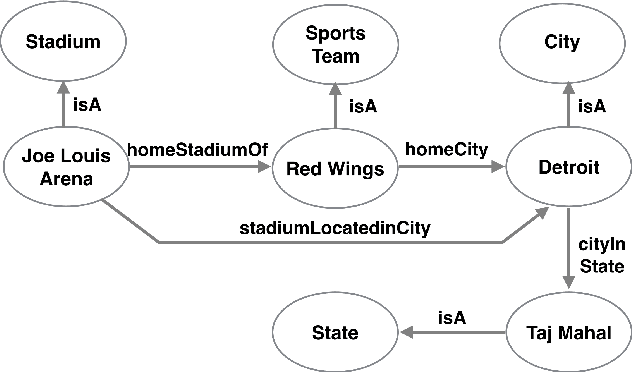
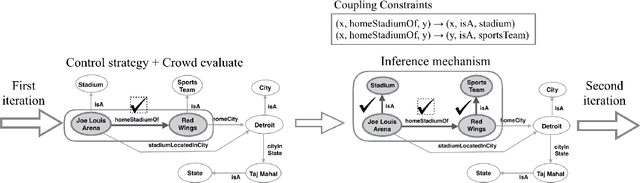
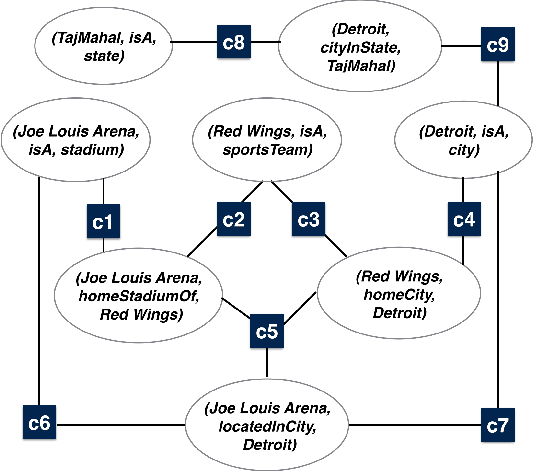
Automatic construction of large knowledge graphs (KG) by mining web-scale text datasets has received considerable attention recently. Estimating accuracy of such automatically constructed KGs is a challenging problem due to their size and diversity. This important problem has largely been ignored in prior research we fill this gap and propose KGEval. KGEval binds facts of a KG using coupling constraints and crowdsources the facts that infer correctness of large parts of the KG. We demonstrate that the objective optimized by KGEval is submodular and NP-hard, allowing guarantees for our approximation algorithm. Through extensive experiments on real-world datasets, we demonstrate that KGEval is able to estimate KG accuracy more accurately compared to other competitive baselines, while requiring significantly lesser number of human evaluations.
Relation Schema Induction using Tensor Factorization with Side Information
Nov 16, 2016
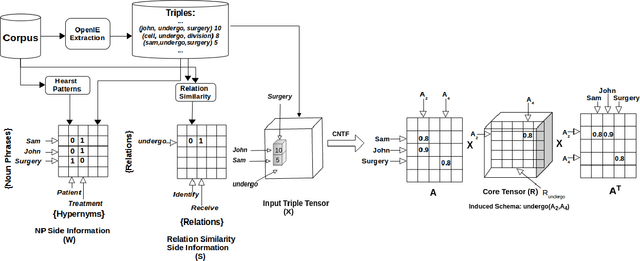

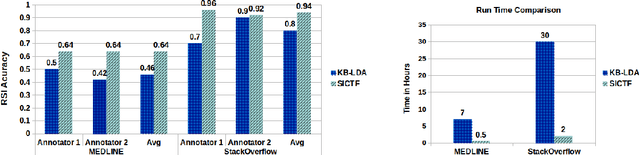
Given a set of documents from a specific domain (e.g., medical research journals), how do we automatically build a Knowledge Graph (KG) for that domain? Automatic identification of relations and their schemas, i.e., type signature of arguments of relations (e.g., undergo(Patient, Surgery)), is an important first step towards this goal. We refer to this problem as Relation Schema Induction (RSI). In this paper, we propose Schema Induction using Coupled Tensor Factorization (SICTF), a novel tensor factorization method for relation schema induction. SICTF factorizes Open Information Extraction (OpenIE) triples extracted from a domain corpus along with additional side information in a principled way to induce relation schemas. To the best of our knowledge, this is the first application of tensor factorization for the RSI problem. Through extensive experiments on multiple real-world datasets, we find that SICTF is not only more accurate than state-of-the-art baselines, but also significantly faster (about 14x faster).
Want Answers? A Reddit Inspired Study on How to Pose Questions
Dec 06, 2015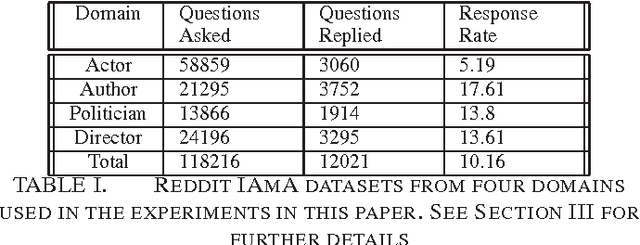


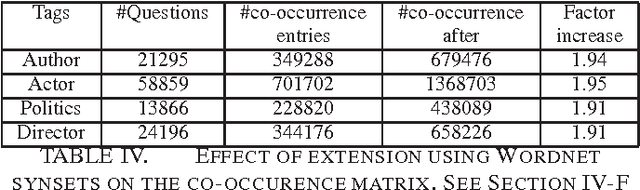
Questions form an integral part of our everyday communication, both offline and online. Getting responses to our questions from others is fundamental to satisfying our information need and in extending our knowledge boundaries. A question may be represented using various factors such as social, syntactic, semantic, etc. We hypothesize that these factors contribute with varying degrees towards getting responses from others for a given question. We perform a thorough empirical study to measure effects of these factors using a novel question and answer dataset from the website Reddit.com. To the best of our knowledge, this is the first such analysis of its kind on this important topic. We also use a sparse nonnegative matrix factorization technique to automatically induce interpretable semantic factors from the question dataset. We also document various patterns on response prediction we observe during our analysis in the data. For instance, we found that preference-probing questions are scantily answered. Our method is robust to capture such latent response factors. We hope to make our code and datasets publicly available upon publication of the paper.
Interactive Data Integration through Smart Copy & Paste
Sep 09, 2009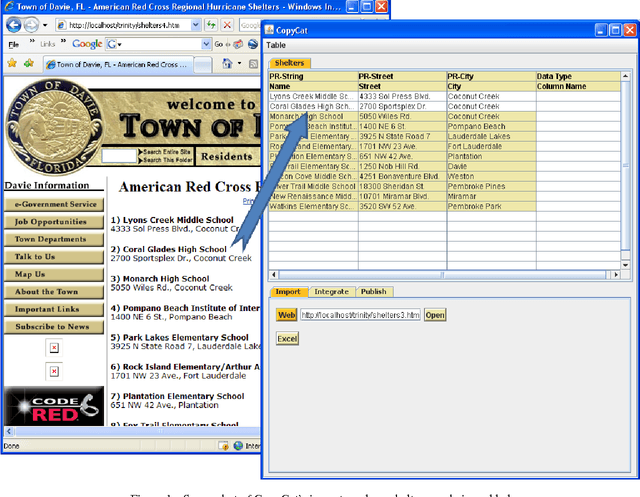
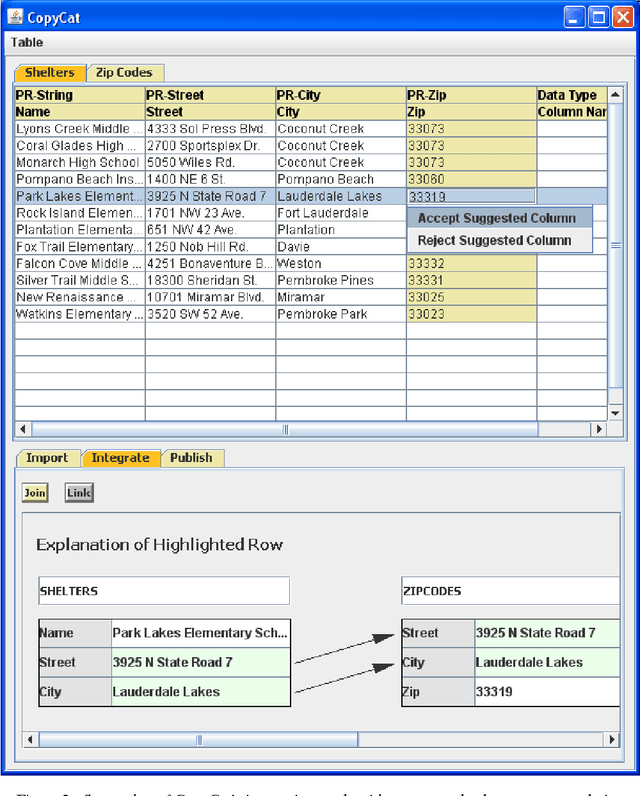
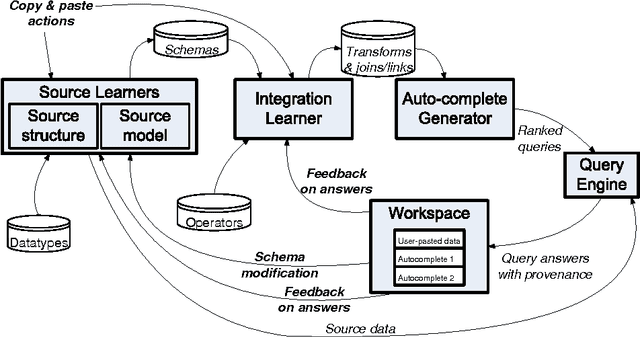
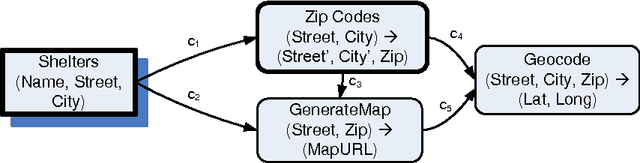
In many scenarios, such as emergency response or ad hoc collaboration, it is critical to reduce the overhead in integrating data. Ideally, one could perform the entire process interactively under one unified interface: defining extractors and wrappers for sources, creating a mediated schema, and adding schema mappings ? while seeing how these impact the integrated view of the data, and refining the design accordingly. We propose a novel smart copy and paste (SCP) model and architecture for seamlessly combining the design-time and run-time aspects of data integration, and we describe an initial prototype, the CopyCat system. In CopyCat, the user does not need special tools for the different stages of integration: instead, the system watches as the user copies data from applications (including the Web browser) and pastes them into CopyCat?s spreadsheet-like workspace. CopyCat generalizes these actions and presents proposed auto-completions, each with an explanation in the form of provenance. The user provides feedback on these suggestions ? through either direct interactions or further copy-and-paste operations ? and the system learns from this feedback. This paper provides an overview of our prototype system, and identifies key research challenges in achieving SCP in its full generality.