 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCANDiS: Coupled & Attention-Driven Neural Distant Supervision
Oct 26, 2017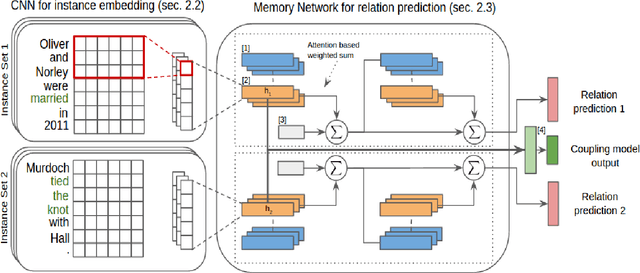

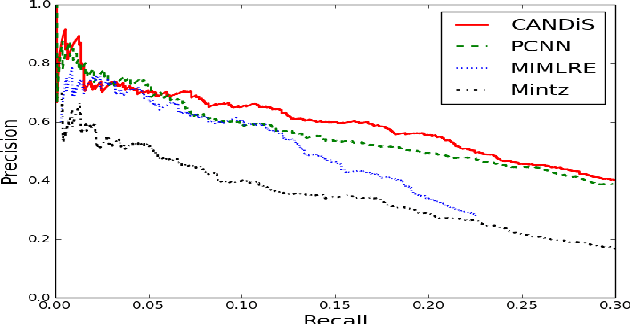
Distant Supervision for Relation Extraction uses heuristically aligned text data with an existing knowledge base as training data. The unsupervised nature of this technique allows it to scale to web-scale relation extraction tasks, at the expense of noise in the training data. Previous work has explored relationships among instances of the same entity-pair to reduce this noise, but relationships among instances across entity-pairs have not been fully exploited. We explore the use of inter-instance couplings based on verb-phrase and entity type similarities. We propose a novel technique, CANDiS, which casts distant supervision using inter-instance coupling into an end-to-end neural network model. CANDiS incorporates an attention module at the instance-level to model the multi-instance nature of this problem. CANDiS outperforms existing state-of-the-art techniques on a standard benchmark dataset.
IISCNLP at SemEval-2016 Task 2: Interpretable STS with ILP based Multiple Chunk Aligner
May 04, 2016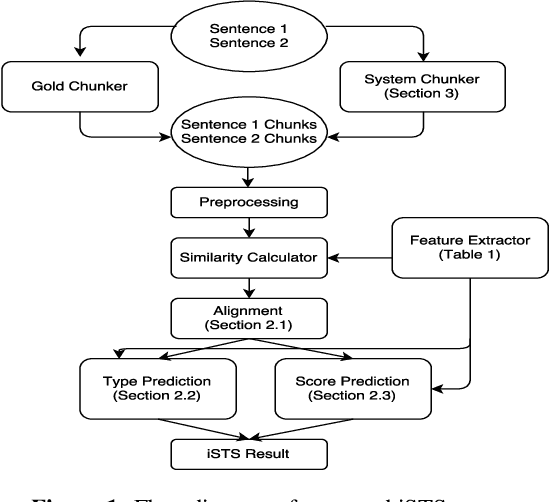
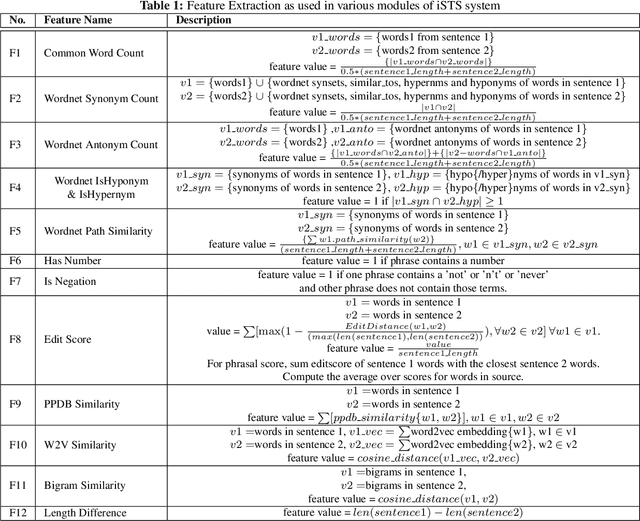
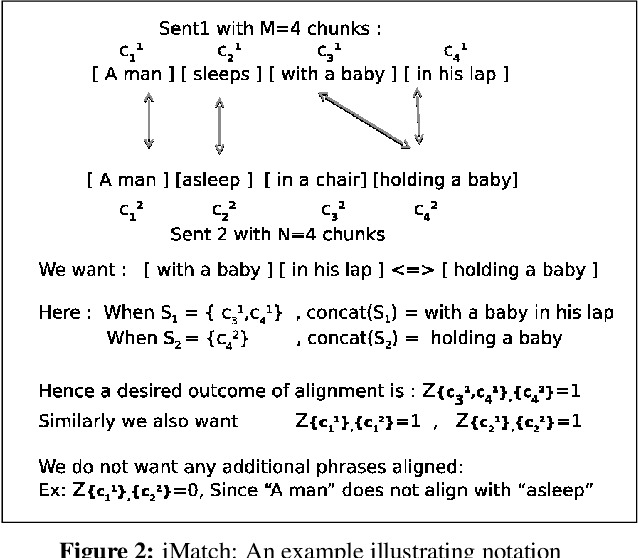
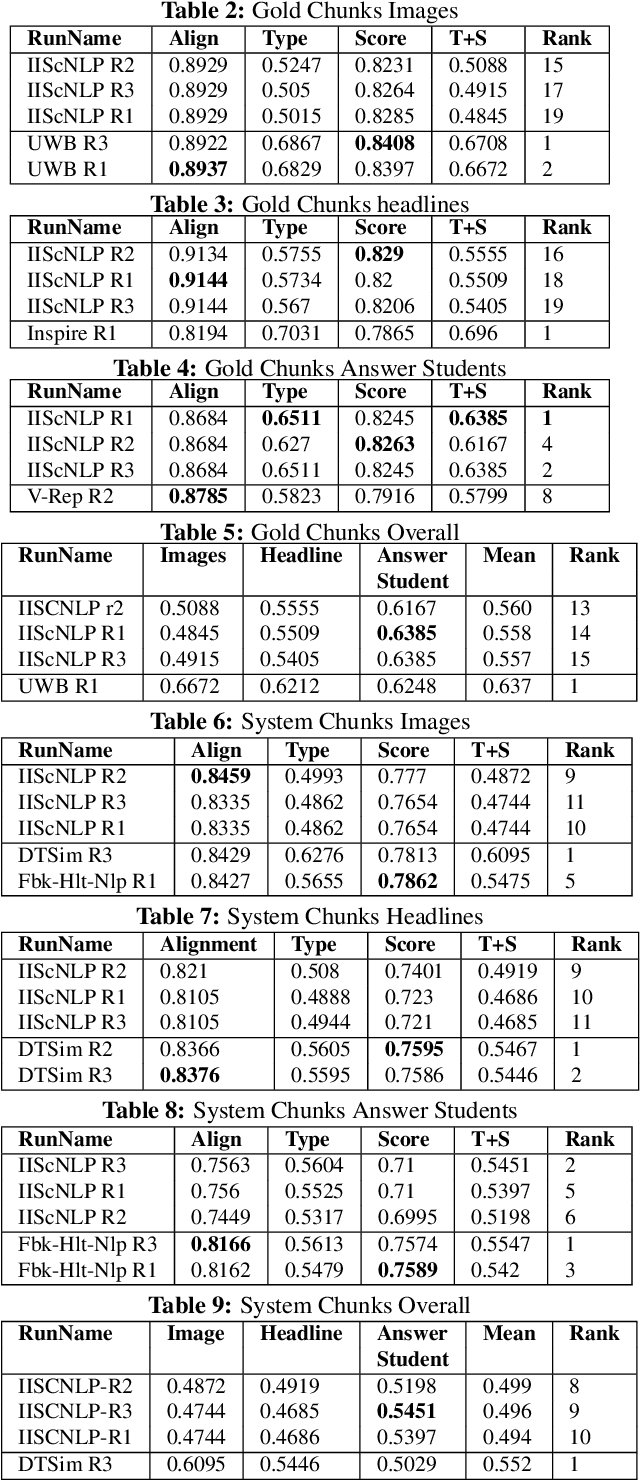
Interpretable semantic textual similarity (iSTS) task adds a crucial explanatory layer to pairwise sentence similarity. We address various components of this task: chunk level semantic alignment along with assignment of similarity type and score for aligned chunks with a novel system presented in this paper. We propose an algorithm, iMATCH, for the alignment of multiple non-contiguous chunks based on Integer Linear Programming (ILP). Similarity type and score assignment for pairs of chunks is done using a supervised multiclass classification technique based on Random Forrest Classifier. Results show that our algorithm iMATCH has low execution time and outperforms most other participating systems in terms of alignment score. Of the three datasets, we are top ranked for answer- students dataset in terms of overall score and have top alignment score for headlines dataset in the gold chunks track.