 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning atrial fiber orientations and conductivity tensors from intracardiac maps using physics-informed neural networks
Feb 22, 2021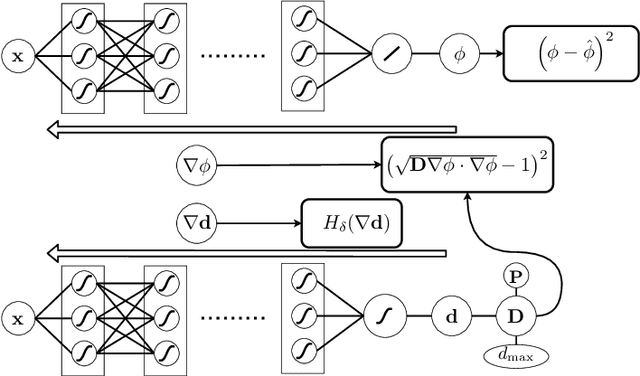
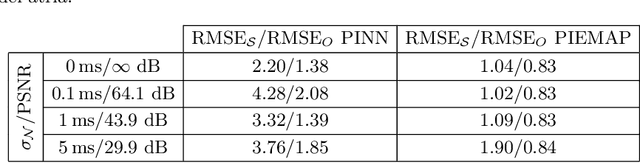
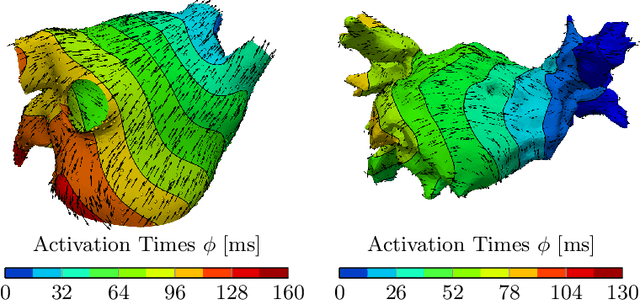
Electroanatomical maps are a key tool in the diagnosis and treatment of atrial fibrillation. Current approaches focus on the activation times recorded. However, more information can be extracted from the available data. The fibers in cardiac tissue conduct the electrical wave faster, and their direction could be inferred from activation times. In this work, we employ a recently developed approach, called physics informed neural networks, to learn the fiber orientations from electroanatomical maps, taking into account the physics of the electrical wave propagation. In particular, we train the neural network to weakly satisfy the anisotropic eikonal equation and to predict the measured activation times. We use a local basis for the anisotropic conductivity tensor, which encodes the fiber orientation. The methodology is tested both in a synthetic example and for patient data. Our approach shows good agreement in both cases and it outperforms a state of the art method in the patient data. The results show a first step towards learning the fiber orientations from electroanatomical maps with physics-informed neural networks.
Output-Weighted Sampling for Multi-Armed Bandits with Extreme Payoffs
Feb 19, 2021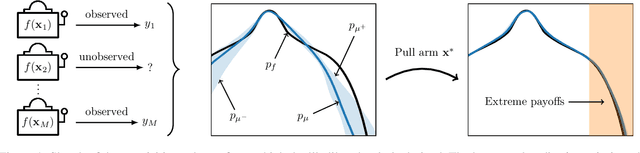
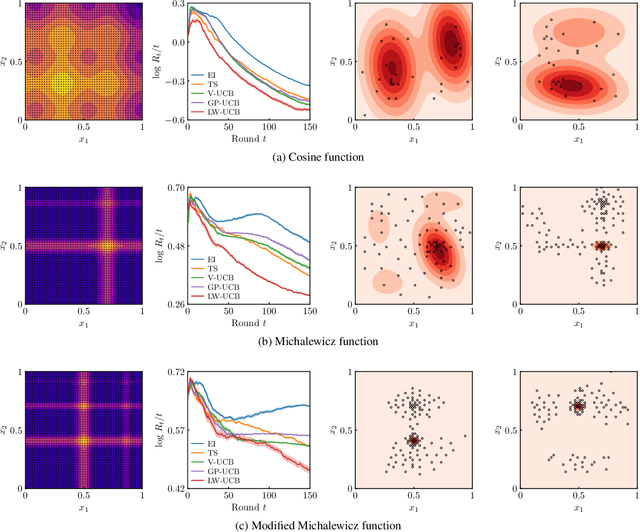
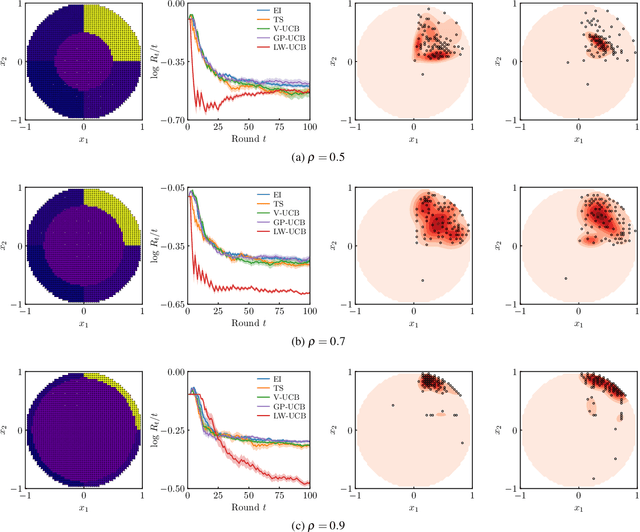
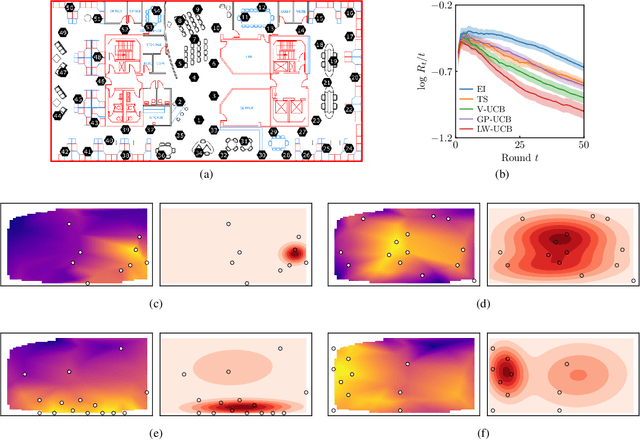
We present a new type of acquisition functions for online decision making in multi-armed and contextual bandit problems with extreme payoffs. Specifically, we model the payoff function as a Gaussian process and formulate a novel type of upper confidence bound (UCB) acquisition function that guides exploration towards the bandits that are deemed most relevant according to the variability of the observed rewards. This is achieved by computing a tractable likelihood ratio that quantifies the importance of the output relative to the inputs and essentially acts as an \textit{attention mechanism} that promotes exploration of extreme rewards. We demonstrate the benefits of the proposed methodology across several synthetic benchmarks, as well as a realistic example involving noisy sensor network data. Finally, we provide a JAX library for efficient bandit optimization using Gaussian processes.
On the eigenvector bias of Fourier feature networks: From regression to solving multi-scale PDEs with physics-informed neural networks
Dec 18, 2020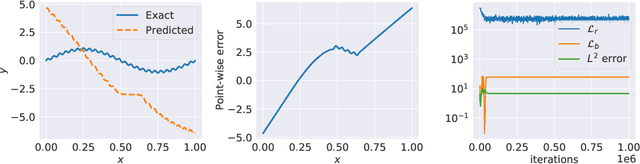
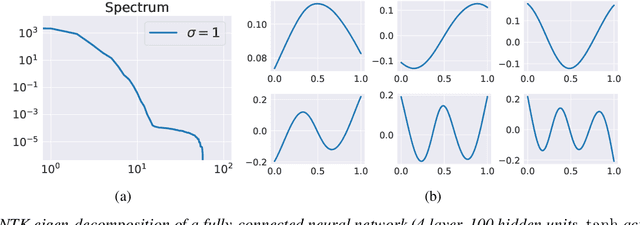
Physics-informed neural networks (PINNs) are demonstrating remarkable promise in integrating physical models with gappy and noisy observational data, but they still struggle in cases where the target functions to be approximated exhibit high-frequency or multi-scale features. In this work we investigate this limitation through the lens of Neural Tangent Kernel (NTK) theory and elucidate how PINNs are biased towards learning functions along the dominant eigen-directions of their limiting NTK. Using this observation, we construct novel architectures that employ spatio-temporal and multi-scale random Fourier features, and justify how such coordinate embedding layers can lead to robust and accurate PINN models. Numerical examples are presented for several challenging cases where conventional PINN models fail, including wave propagation and reaction-diffusion dynamics, illustrating how the proposed methods can be used to effectively tackle both forward and inverse problems involving partial differential equations with multi-scale behavior. All code an data accompanying this manuscript will be made publicly available at \url{https://github.com/PredictiveIntelligenceLab/MultiscalePINNs}.
Learning Unknown Physics of non-Newtonian Fluids
Aug 26, 2020
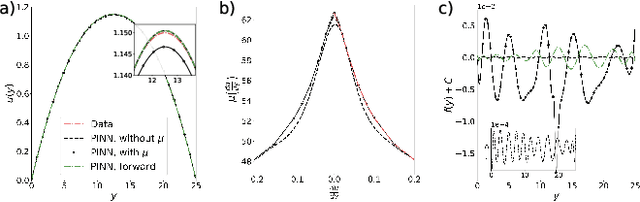
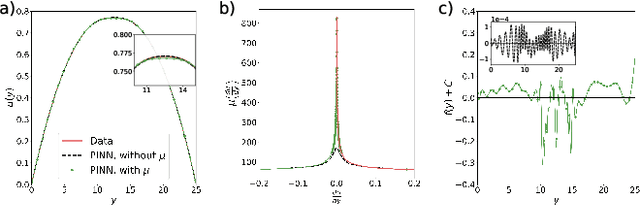
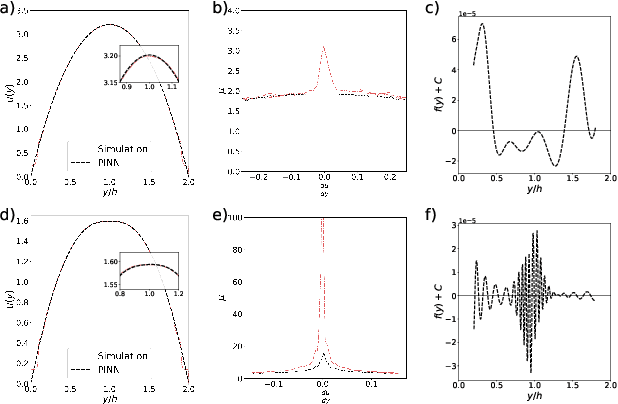
We extend the physics-informed neural network (PINN) method to learn viscosity models of two non-Newtonian systems (polymer melts and suspensions of particles) using only velocity measurements. The PINN-inferred viscosity models agree with the empirical models for shear rates with large absolute values but deviate for shear rates near zero where the analytical models have an unphysical singularity. Once a viscosity model is learned, we use the PINN method to solve the momentum conservation equation for non-Newtonian fluid flow using only the boundary conditions.
When and why PINNs fail to train: A neural tangent kernel perspective
Jul 28, 2020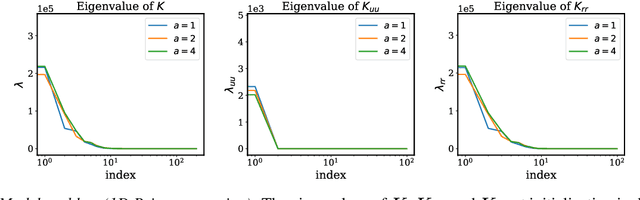
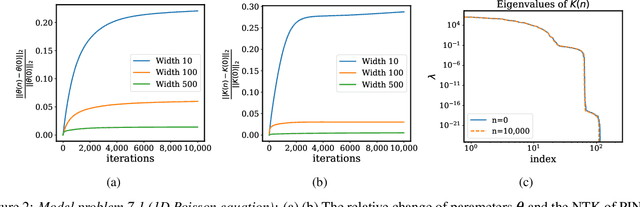
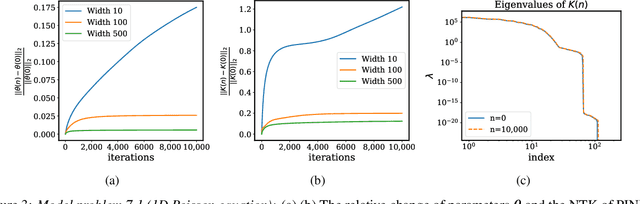
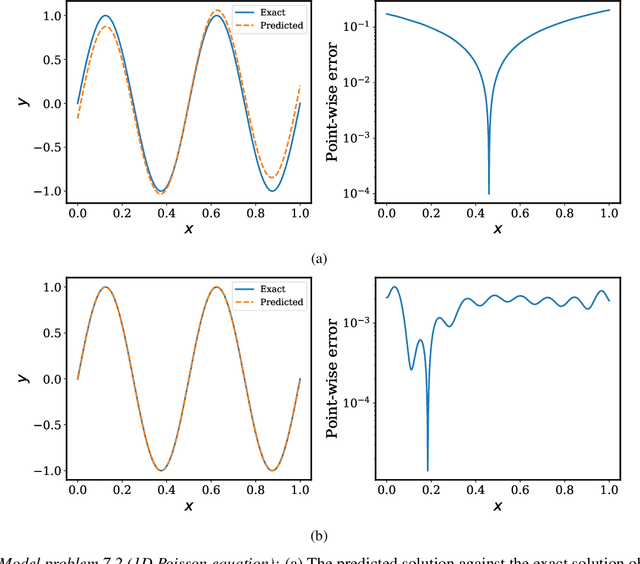
Physics-informed neural networks (PINNs) have lately received great attention thanks to their flexibility in tackling a wide range of forward and inverse problems involving partial differential equations. However, despite their noticeable empirical success, little is known about how such constrained neural networks behave during their training via gradient descent. More importantly, even less is known about why such models sometimes fail to train at all. In this work, we aim to investigate these questions through the lens of the Neural Tangent Kernel (NTK); a kernel that captures the behavior of fully-connected neural networks in the infinite width limit during training via gradient descent. Specifically, we derive the NTK of PINNs and prove that, under appropriate conditions, it converges to a deterministic kernel that stays constant during training in the infinite-width limit. This allows us to analyze the training dynamics of PINNs through the lens of their limiting NTK and find a remarkable discrepancy in the convergence rate of the different loss components contributing to the total training error. To address this fundamental pathology, we propose a novel gradient descent algorithm that utilizes the eigenvalues of the NTK to adaptively calibrate the convergence rate of the total training error. Finally, we perform a series of numerical experiments to verify the correctness of our theory and the practical effectiveness of the proposed algorithms. The data and code accompanying this manuscript are publicly available at \url{https://github.com/PredictiveIntelligenceLab/PINNsNTK}.
Deep learning of free boundary and Stefan problems
Jun 04, 2020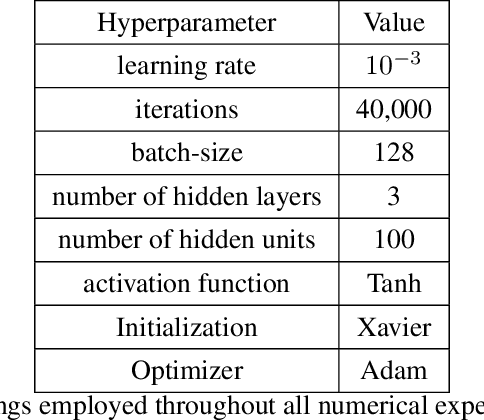
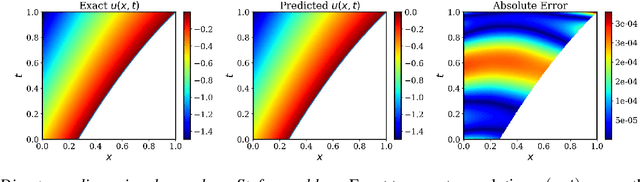

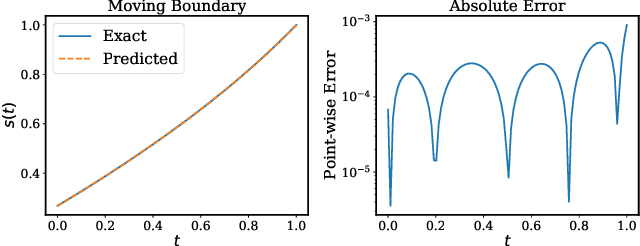
Free boundary problems appear naturally in numerous areas of mathematics, science and engineering. These problems present a great computational challenge because they necessitate numerical methods that can yield an accurate approximation of free boundaries and complex dynamic interfaces. In this work, we propose a multi-network model based on physics-informed neural networks to tackle a general class of forward and inverse free boundary problems called Stefan problems. Specifically, we approximate the unknown solution as well as any moving boundaries by two deep neural networks. Besides, we formulate a new type of inverse Stefan problems that aim to reconstruct the solution and free boundaries directly from sparse and noisy measurements. We demonstrate the effectiveness of our approach in a series of benchmarks spanning different types of Stefan problems, and illustrate how the proposed framework can accurately recover solutions of partial differential equations with moving boundaries and dynamic interfaces. All code and data accompanying this manuscript are publicly available at \url{https://github.com/PredictiveIntelligenceLab/DeepStefan}.
Bayesian differential programming for robust systems identification under uncertainty
Apr 18, 2020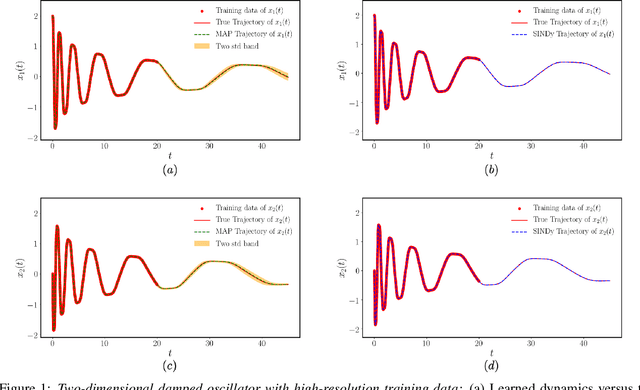
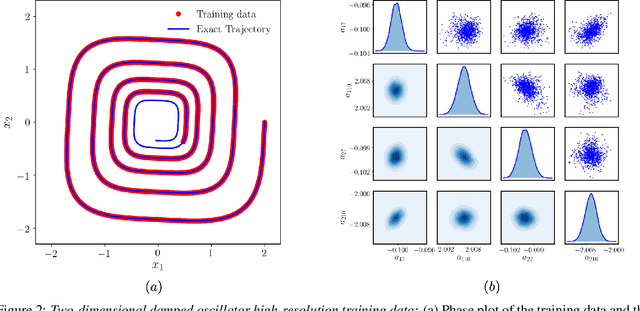

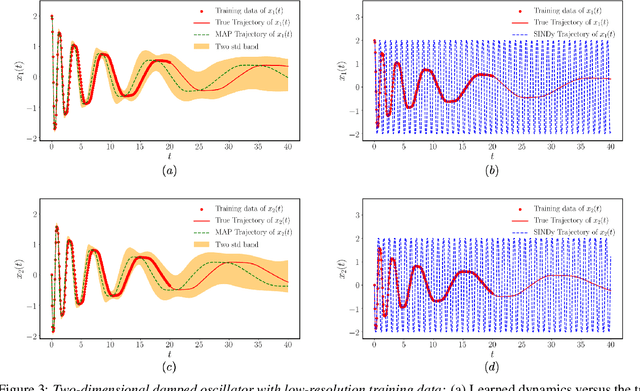
This paper presents a machine learning framework for Bayesian systems identification from noisy, sparse and irregular observations of nonlinear dynamical systems. The proposed method takes advantage of recent developments in differentiable programming to propagate gradient information through ordinary differential equation solvers and perform Bayesian inference with respect to unknown model parameters using Hamiltonian Monte Carlo. This allows us to efficiently infer posterior distributions over plausible models with quantified uncertainty, while the use of sparsity-promoting priors enables the discovery of interpretable and parsimonious representations for the underlying latent dynamics. A series of numerical studies is presented to demonstrate the effectiveness of the proposed methods including nonlinear oscillators, predator-prey systems, chaotic dynamics and systems biology. Taken all together, our findings put forth a novel, flexible and robust workflow for data-driven model discovery under uncertainty.
Understanding and mitigating gradient pathologies in physics-informed neural networks
Jan 13, 2020

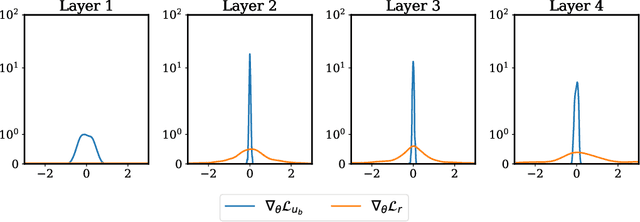
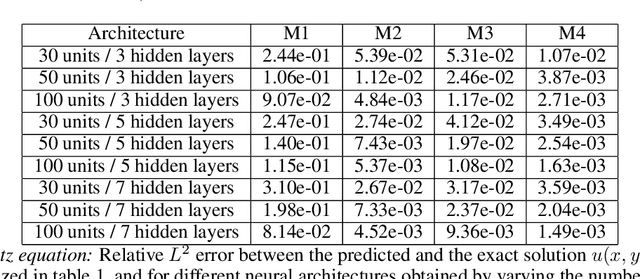
The widespread use of neural networks across different scientific domains often involves constraining them to satisfy certain symmetries, conservation laws, or other domain knowledge. Such constraints are often imposed as soft penalties during model training and effectively act as domain-specific regularizers of the empirical risk loss. Physics-informed neural networks is an example of this philosophy in which the outputs of deep neural networks are constrained to approximately satisfy a given set of partial differential equations. In this work we review recent advances in scientific machine learning with a specific focus on the effectiveness of physics-informed neural networks in predicting outcomes of physical systems and discovering hidden physics from noisy data. We will also identify and analyze a fundamental mode of failure of such approaches that is related to numerical stiffness leading to unbalanced back-propagated gradients during model training. To address this limitation we present a learning rate annealing algorithm that utilizes gradient statistics during model training to balance the interplay between different terms in composite loss functions. We also propose a novel neural network architecture that is more resilient to such gradient pathologies. Taken together, our developments provide new insights into the training of constrained neural networks and consistently improve the predictive accuracy of physics-informed neural networks by a factor of 50-100x across a range of problems in computational physics. All code and data accompanying this manuscript are publicly available at \url{https://github.com/PredictiveIntelligenceLab/GradientPathologiesPINNs}.
Machine learning in cardiovascular flows modeling: Predicting pulse wave propagation from non-invasive clinical measurements using physics-informed deep learning
May 13, 2019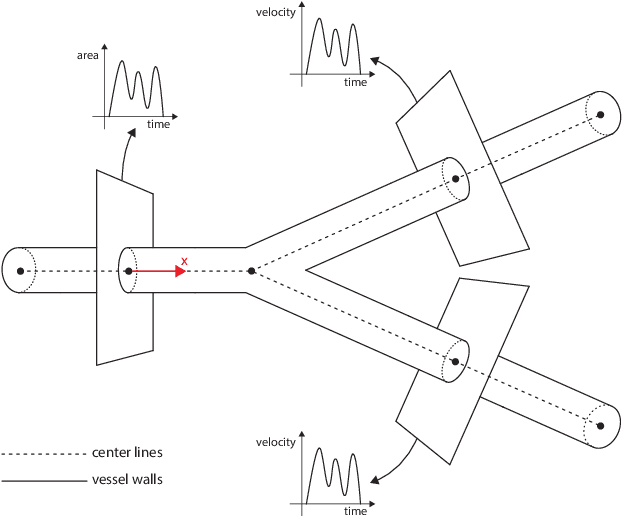

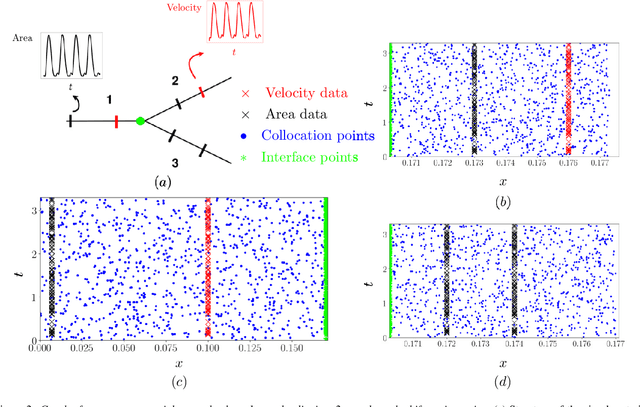

Advances in computational science offer a principled pipeline for predictive modeling of cardiovascular flows and aspire to provide a valuable tool for monitoring, diagnostics and surgical planning. Such models can be nowadays deployed on large patient-specific topologies of systemic arterial networks and return detailed predictions on flow patterns, wall shear stresses, and pulse wave propagation. However, their success heavily relies on tedious pre-processing and calibration procedures that typically induce a significant computational cost, thus hampering their clinical applicability. In this work we put forth a machine learning framework that enables the seamless synthesis of non-invasive in-vivo measurement techniques and computational flow dynamics models derived from first physical principles. We illustrate this new paradigm by showing how one-dimensional models of pulsatile flow can be used to constrain the output of deep neural networks such that their predictions satisfy the conservation of mass and momentum principles. Once trained on noisy and scattered clinical data of flow and wall displacement, these networks can return physically consistent predictions for velocity, pressure and wall displacement pulse wave propagation, all without the need to employ conventional simulators. A simple post-processing of these outputs can also provide a cheap and effective way for estimating Windkessel model parameters that are required for the calibration of traditional computational models. The effectiveness of the proposed techniques is demonstrated through a series of prototype benchmarks, as well as a realistic clinical case involving in-vivo measurements near the aorta/carotid bifurcation of a healthy human subject.
Multi-fidelity classification using Gaussian processes: accelerating the prediction of large-scale computational models
May 09, 2019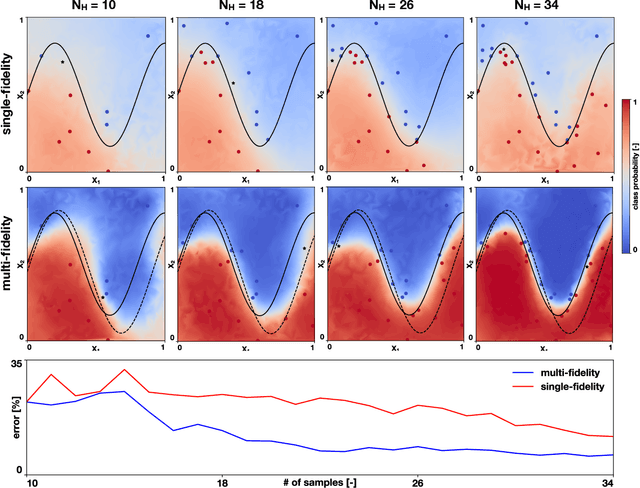
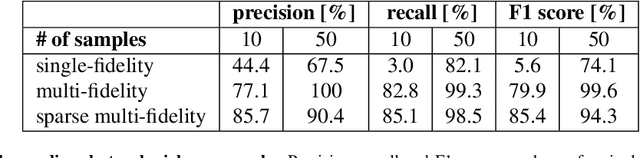
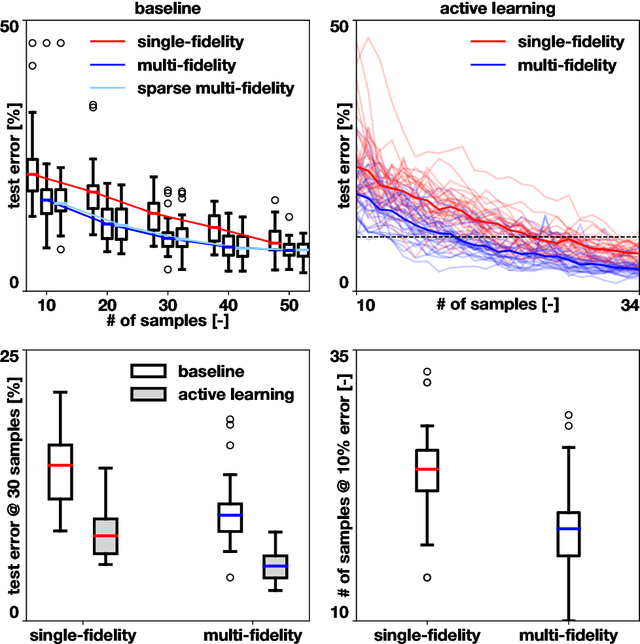
Machine learning techniques typically rely on large datasets to create accurate classifiers. However, there are situations when data is scarce and expensive to acquire. This is the case of studies that rely on state-of-the-art computational models which typically take days to run, thus hindering the potential of machine learning tools. In this work, we present a novel classifier that takes advantage of lower fidelity models and inexpensive approximations to predict the binary output of expensive computer simulations. We postulate an autoregressive model between the different levels of fidelity with Gaussian process priors. We adopt a fully Bayesian treatment for the hyper-parameters and use Markov Chain Mont Carlo samplers. We take advantage of the probabilistic nature of the classifier to implement active learning strategies. We also introduce a sparse approximation to enhance the ability of themulti-fidelity classifier to handle large datasets. We test these multi-fidelity classifiers against their single-fidelity counterpart with synthetic data, showing a median computational cost reduction of 23% for a target accuracy of 90%. In an application to cardiac electrophysiology, the multi-fidelity classifier achieves an F1 score, the harmonic mean of precision and recall, of 99.6% compared to 74.1% of a single-fidelity classifier when both are trained with 50 samples. In general, our results show that the multi-fidelity classifiers outperform their single-fidelity counterpart in terms of accuracy in all cases. We envision that this new tool will enable researchers to study classification problems that would otherwise be prohibitively expensive. Source code is available at https://github.com/fsahli/MFclass.