 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDMAP: A Distribution Map for Text
Feb 12, 2026Large Language Models (LLMs) are a powerful tool for statistical text analysis, with derived sequences of next-token probability distributions offering a wealth of information. Extracting this signal typically relies on metrics such as perplexity, which do not adequately account for context; how one should interpret a given next-token probability is dependent on the number of reasonable choices encoded by the shape of the conditional distribution. In this work, we present DMAP, a mathematically grounded method that maps a text, via a language model, to a set of samples in the unit interval that jointly encode rank and probability information. This representation enables efficient, model-agnostic analysis and supports a range of applications. We illustrate its utility through three case studies: (i) validation of generation parameters to ensure data integrity, (ii) examining the role of probability curvature in machine-generated text detection, and (iii) a forensic analysis revealing statistical fingerprints left in downstream models that have been subject to post-training on synthetic data. Our results demonstrate that DMAP offers a unified statistical view of text that is simple to compute on consumer hardware, widely applicable, and provides a foundation for further research into text analysis with LLMs.
Emergent Bias and Fairness in Multi-Agent Decision Systems
Dec 18, 2025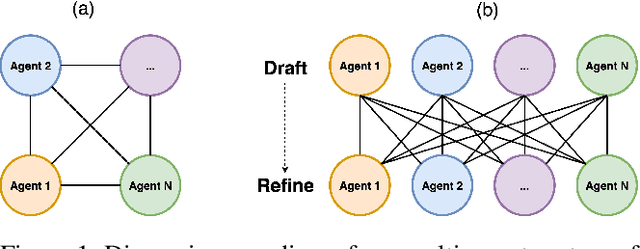
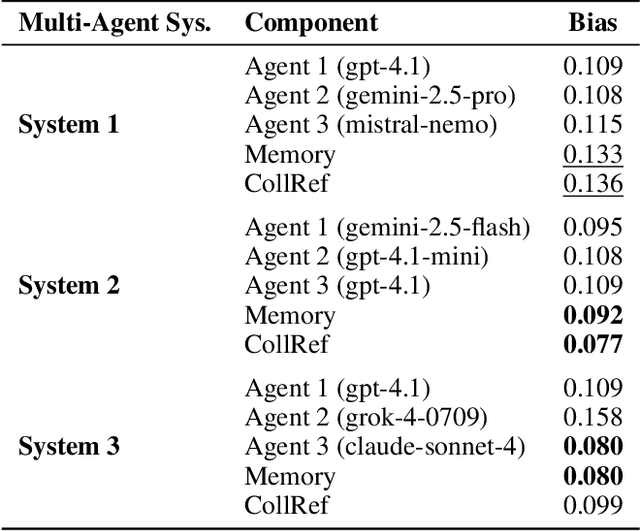

Multi-agent systems have demonstrated the ability to improve performance on a variety of predictive tasks by leveraging collaborative decision making. However, the lack of effective evaluation methodologies has made it difficult to estimate the risk of bias, making deployment of such systems unsafe in high stakes domains such as consumer finance, where biased decisions can translate directly into regulatory breaches and financial loss. To address this challenge, we need to develop fairness evaluation methodologies for multi-agent predictive systems and measure the fairness characteristics of these systems in the financial tabular domain. Examining fairness metrics using large-scale simulations across diverse multi-agent configurations, with varying communication and collaboration mechanisms, we reveal patterns of emergent bias in financial decision-making that cannot be traced to individual agent components, indicating that multi-agent systems may exhibit genuinely collective behaviors. Our findings highlight that fairness risks in financial multi-agent systems represent a significant component of model risk, with tangible impacts on tasks such as credit scoring and income estimation. We advocate that multi-agent decision systems must be evaluated as holistic entities rather than through reductionist analyses of their constituent components.
Policy Teaching via Data Poisoning in Learning from Human Preferences
Mar 13, 2025

We study data poisoning attacks in learning from human preferences. More specifically, we consider the problem of teaching/enforcing a target policy $\pi^\dagger$ by synthesizing preference data. We seek to understand the susceptibility of different preference-based learning paradigms to poisoned preference data by analyzing the number of samples required by the attacker to enforce $\pi^\dagger$. We first propose a general data poisoning formulation in learning from human preferences and then study it for two popular paradigms, namely: (a) reinforcement learning from human feedback (RLHF) that operates by learning a reward model using preferences; (b) direct preference optimization (DPO) that directly optimizes policy using preferences. We conduct a theoretical analysis of the effectiveness of data poisoning in a setting where the attacker is allowed to augment a pre-existing dataset and also study its special case where the attacker can synthesize the entire preference dataset from scratch. As our main results, we provide lower/upper bounds on the number of samples required to enforce $\pi^\dagger$. Finally, we discuss the implications of our results in terms of the susceptibility of these learning paradigms under such data poisoning attacks.
Fairness-Aware Low-Rank Adaptation Under Demographic Privacy Constraints
Mar 07, 2025Pre-trained foundation models can be adapted for specific tasks using Low-Rank Adaptation (LoRA). However, the fairness properties of these adapted classifiers remain underexplored. Existing fairness-aware fine-tuning methods rely on direct access to sensitive attributes or their predictors, but in practice, these sensitive attributes are often held under strict consumer privacy controls, and neither the attributes nor their predictors are available to model developers, hampering the development of fair models. To address this issue, we introduce a set of LoRA-based fine-tuning methods that can be trained in a distributed fashion, where model developers and fairness auditors collaborate without sharing sensitive attributes or predictors. In this paper, we evaluate three such methods - sensitive unlearning, adversarial training, and orthogonality loss - against a fairness-unaware baseline, using experiments on the CelebA and UTK-Face datasets with an ImageNet pre-trained ViT-Base model. We find that orthogonality loss consistently reduces bias while maintaining or improving utility, whereas adversarial training improves False Positive Rate Parity and Demographic Parity in some cases, and sensitive unlearning provides no clear benefit. In tasks where significant biases are present, distributed fairness-aware fine-tuning methods can effectively eliminate bias without compromising consumer privacy and, in most cases, improve model utility.
Evaluating Fairness in Transaction Fraud Models: Fairness Metrics, Bias Audits, and Challenges
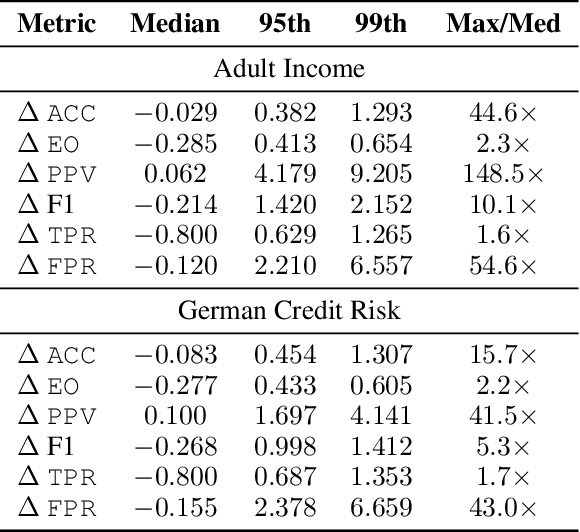
Sep 06, 2024Ensuring fairness in transaction fraud detection models is vital due to the potential harms and legal implications of biased decision-making. Despite extensive research on algorithmic fairness, there is a notable gap in the study of bias in fraud detection models, mainly due to the field's unique challenges. These challenges include the need for fairness metrics that account for fraud data's imbalanced nature and the tradeoff between fraud protection and service quality. To address this gap, we present a comprehensive fairness evaluation of transaction fraud models using public synthetic datasets, marking the first algorithmic bias audit in this domain. Our findings reveal three critical insights: (1) Certain fairness metrics expose significant bias only after normalization, highlighting the impact of class imbalance. (2) Bias is significant in both service quality-related parity metrics and fraud protection-related parity metrics. (3) The fairness through unawareness approach, which involved removing sensitive attributes such as gender, does not improve bias mitigation within these datasets, likely due to the presence of correlated proxies. We also discuss socio-technical fairness-related challenges in transaction fraud models. These insights underscore the need for a nuanced approach to fairness in fraud detection, balancing protection and service quality, and moving beyond simple bias mitigation strategies. Future work must focus on refining fairness metrics and developing methods tailored to the unique complexities of the transaction fraud domain.
Adversarial Robust Decision Transformer: Enhancing Robustness of RvS via Minimax Returns-to-go
Jul 25, 2024



Decision Transformer (DT), as one of the representative Reinforcement Learning via Supervised Learning (RvS) methods, has achieved strong performance in offline learning tasks by leveraging the powerful Transformer architecture for sequential decision-making. However, in adversarial environments, these methods can be non-robust, since the return is dependent on the strategies of both the decision-maker and adversary. Training a probabilistic model conditioned on observed return to predict action can fail to generalize, as the trajectories that achieve a return in the dataset might have done so due to a weak and suboptimal behavior adversary. To address this, we propose a worst-case-aware RvS algorithm, the Adversarial Robust Decision Transformer (ARDT), which learns and conditions the policy on in-sample minimax returns-to-go. ARDT aligns the target return with the worst-case return learned through minimax expectile regression, thereby enhancing robustness against powerful test-time adversaries. In experiments conducted on sequential games with full data coverage, ARDT can generate a maximin (Nash Equilibrium) strategy, the solution with the largest adversarial robustness. In large-scale sequential games and continuous adversarial RL environments with partial data coverage, ARDT demonstrates significantly superior robustness to powerful test-time adversaries and attains higher worst-case returns compared to contemporary DT methods.
Proximal Curriculum with Task Correlations for Deep Reinforcement Learning
May 03, 2024


Curriculum design for reinforcement learning (RL) can speed up an agent's learning process and help it learn to perform well on complex tasks. However, existing techniques typically require domain-specific hyperparameter tuning, involve expensive optimization procedures for task selection, or are suitable only for specific learning objectives. In this work, we consider curriculum design in contextual multi-task settings where the agent's final performance is measured w.r.t. a target distribution over complex tasks. We base our curriculum design on the Zone of Proximal Development concept, which has proven to be effective in accelerating the learning process of RL agents for uniform distribution over all tasks. We propose a novel curriculum, ProCuRL-Target, that effectively balances the need for selecting tasks that are not too difficult for the agent while progressing the agent's learning toward the target distribution via leveraging task correlations. We theoretically justify the task selection strategy of ProCuRL-Target by analyzing a simple learning setting with REINFORCE learner model. Our experimental results across various domains with challenging target task distributions affirm the effectiveness of our curriculum strategy over state-of-the-art baselines in accelerating the training process of deep RL agents.
Reward Model Learning vs. Direct Policy Optimization: A Comparative Analysis of Learning from Human Preferences
Mar 04, 2024In this paper, we take a step towards a deeper understanding of learning from human preferences by systematically comparing the paradigm of reinforcement learning from human feedback (RLHF) with the recently proposed paradigm of direct preference optimization (DPO). We focus our attention on the class of loglinear policy parametrization and linear reward functions. In order to compare the two paradigms, we first derive minimax statistical bounds on the suboptimality gap induced by both RLHF and DPO, assuming access to an oracle that exactly solves the optimization problems. We provide a detailed discussion on the relative comparison between the two paradigms, simultaneously taking into account the sample size, policy and reward class dimensions, and the regularization temperature. Moreover, we extend our analysis to the approximate optimization setting and derive exponentially decaying convergence rates for both RLHF and DPO. Next, we analyze the setting where the ground-truth reward is not realizable and find that, while RLHF incurs a constant additional error, DPO retains its asymptotically decaying gap by just tuning the temperature accordingly. Finally, we extend our comparison to the Markov decision process setting, where we generalize our results with exact optimization. To the best of our knowledge, we are the first to provide such a comparative analysis for RLHF and DPO.
Informativeness of Reward Functions in Reinforcement Learning
Feb 10, 2024



Reward functions are central in specifying the task we want a reinforcement learning agent to perform. Given a task and desired optimal behavior, we study the problem of designing informative reward functions so that the designed rewards speed up the agent's convergence. In particular, we consider expert-driven reward design settings where an expert or teacher seeks to provide informative and interpretable rewards to a learning agent. Existing works have considered several different reward design formulations; however, the key challenge is formulating a reward informativeness criterion that adapts w.r.t. the agent's current policy and can be optimized under specified structural constraints to obtain interpretable rewards. In this paper, we propose a novel reward informativeness criterion, a quantitative measure that captures how the agent's current policy will improve if it receives rewards from a specific reward function. We theoretically showcase the utility of the proposed informativeness criterion for adaptively designing rewards for an agent. Experimental results on two navigation tasks demonstrate the effectiveness of our adaptive reward informativeness criterion.
Corruption Robust Offline Reinforcement Learning with Human Feedback
Feb 09, 2024
We study data corruption robustness for reinforcement learning with human feedback (RLHF) in an offline setting. Given an offline dataset of pairs of trajectories along with feedback about human preferences, an $\varepsilon$-fraction of the pairs is corrupted (e.g., feedback flipped or trajectory features manipulated), capturing an adversarial attack or noisy human preferences. We aim to design algorithms that identify a near-optimal policy from the corrupted data, with provable guarantees. Existing theoretical works have separately studied the settings of corruption robust RL (learning from scalar rewards directly under corruption) and offline RLHF (learning from human feedback without corruption); however, they are inapplicable to our problem of dealing with corrupted data in offline RLHF setting. To this end, we design novel corruption robust offline RLHF methods under various assumptions on the coverage of the data-generating distributions. At a high level, our methodology robustifies an offline RLHF framework by first learning a reward model along with confidence sets and then learning a pessimistic optimal policy over the confidence set. Our key insight is that learning optimal policy can be done by leveraging an offline corruption-robust RL oracle in different ways (e.g., zero-order oracle or first-order oracle), depending on the data coverage assumptions. To our knowledge, ours is the first work that provides provable corruption robust offline RLHF methods.