 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLog-Likelihood, Simpson's Paradox, and the Detection of Machine-Generated Text
May 07, 2026The ability to reliably distinguish human-written text from that generated by large language models is of profound societal importance. The dominant approach to this problem exploits the likelihood hypothesis: that machine-generated text should appear more probable to a detector language model than human-written text. However, we demonstrate that the token-level signal distinguishing human and machine text is non-uniform across the hidden space of the detector model, and naively averaging likelihood-based token scores across regions with fundamentally different statistical structure, as most detectors do, causes a form of Simpson's paradox: a strong local signal is destroyed by inappropriate aggregation. To correct for this, we introduce a learned local calibration step grounded in Bayesian decision theory. Rather than aggregating raw token scores, we first learn lightweight predictors of the score distributions conditioned on position in hidden space, and aggregate calibrated log-likelihood ratios instead. This single intervention dramatically and consistently improves detection performance across all baseline detectors and all datasets we consider. For example, our calibrated variant of Fast-DetectGPT improves AUROC from $0.63$ to $0.85$ on GPT-5.4 text, and a locally-calibrated DMAP detector we introduce achieves state-of-the-art performance across the board. That said, our central contribution is not a new detector, but a precise diagnosis of a significant cause of under-performance of existing detectors and a principled, modular remedy compatible with any token-averaging pipeline. This will serve as a foundation for the community to build upon, with natural avenues including richer distributional models, improved calibration strategies, and principled ensembling with hidden-space geometry signals via the full Bayes-optimal decision rule.
DMAP: A Distribution Map for Text
Feb 12, 2026Large Language Models (LLMs) are a powerful tool for statistical text analysis, with derived sequences of next-token probability distributions offering a wealth of information. Extracting this signal typically relies on metrics such as perplexity, which do not adequately account for context; how one should interpret a given next-token probability is dependent on the number of reasonable choices encoded by the shape of the conditional distribution. In this work, we present DMAP, a mathematically grounded method that maps a text, via a language model, to a set of samples in the unit interval that jointly encode rank and probability information. This representation enables efficient, model-agnostic analysis and supports a range of applications. We illustrate its utility through three case studies: (i) validation of generation parameters to ensure data integrity, (ii) examining the role of probability curvature in machine-generated text detection, and (iii) a forensic analysis revealing statistical fingerprints left in downstream models that have been subject to post-training on synthetic data. Our results demonstrate that DMAP offers a unified statistical view of text that is simple to compute on consumer hardware, widely applicable, and provides a foundation for further research into text analysis with LLMs.
Emergent Bias and Fairness in Multi-Agent Decision Systems
Dec 18, 2025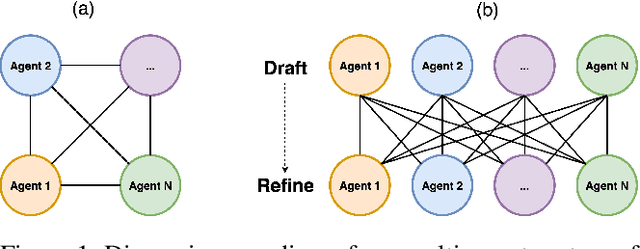
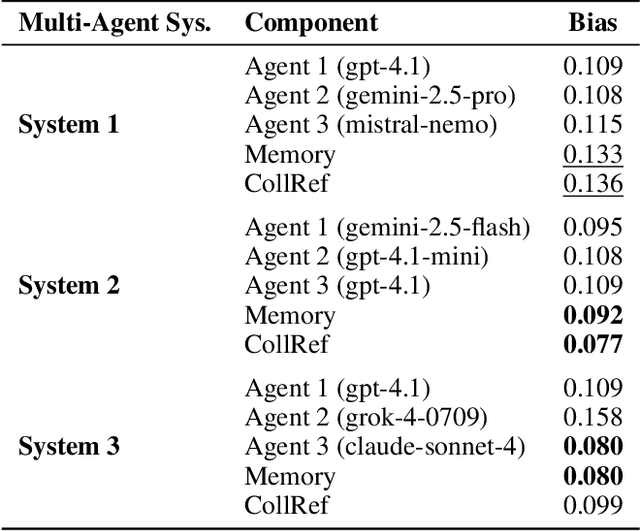

Multi-agent systems have demonstrated the ability to improve performance on a variety of predictive tasks by leveraging collaborative decision making. However, the lack of effective evaluation methodologies has made it difficult to estimate the risk of bias, making deployment of such systems unsafe in high stakes domains such as consumer finance, where biased decisions can translate directly into regulatory breaches and financial loss. To address this challenge, we need to develop fairness evaluation methodologies for multi-agent predictive systems and measure the fairness characteristics of these systems in the financial tabular domain. Examining fairness metrics using large-scale simulations across diverse multi-agent configurations, with varying communication and collaboration mechanisms, we reveal patterns of emergent bias in financial decision-making that cannot be traced to individual agent components, indicating that multi-agent systems may exhibit genuinely collective behaviors. Our findings highlight that fairness risks in financial multi-agent systems represent a significant component of model risk, with tangible impacts on tasks such as credit scoring and income estimation. We advocate that multi-agent decision systems must be evaluated as holistic entities rather than through reductionist analyses of their constituent components.
Fairness-Aware Low-Rank Adaptation Under Demographic Privacy Constraints
Mar 07, 2025Pre-trained foundation models can be adapted for specific tasks using Low-Rank Adaptation (LoRA). However, the fairness properties of these adapted classifiers remain underexplored. Existing fairness-aware fine-tuning methods rely on direct access to sensitive attributes or their predictors, but in practice, these sensitive attributes are often held under strict consumer privacy controls, and neither the attributes nor their predictors are available to model developers, hampering the development of fair models. To address this issue, we introduce a set of LoRA-based fine-tuning methods that can be trained in a distributed fashion, where model developers and fairness auditors collaborate without sharing sensitive attributes or predictors. In this paper, we evaluate three such methods - sensitive unlearning, adversarial training, and orthogonality loss - against a fairness-unaware baseline, using experiments on the CelebA and UTK-Face datasets with an ImageNet pre-trained ViT-Base model. We find that orthogonality loss consistently reduces bias while maintaining or improving utility, whereas adversarial training improves False Positive Rate Parity and Demographic Parity in some cases, and sensitive unlearning provides no clear benefit. In tasks where significant biases are present, distributed fairness-aware fine-tuning methods can effectively eliminate bias without compromising consumer privacy and, in most cases, improve model utility.