 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple, Strong and Robust Baseline for Distantly Supervised Relation Extraction
Oct 14, 2021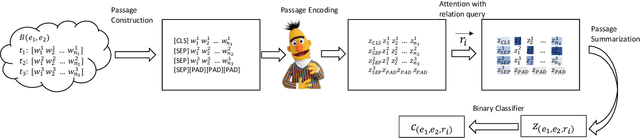
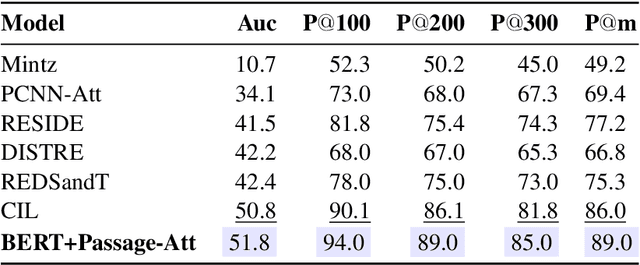
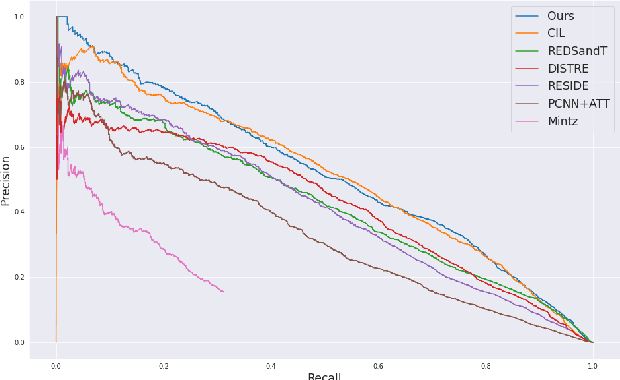

Distantly supervised relation extraction (DS-RE) is generally framed as a multi-instance multi-label (MI-ML) task, where the optimal aggregation of information from multiple instances is of key importance. Intra-bag attention (Lin et al., 2016) is an example of a popularly used aggregation scheme for this framework. Apart from this scheme, however, there is not much to choose from in the DS-RE literature as most of the advances in this field are focused on improving the instance-encoding step rather than the instance-aggregation step. With recent works leveraging large pre-trained language models as encoders, the increased capacity of models might allow for more flexibility in the instance-aggregation step. In this work, we explore this hypothesis and come up with a novel aggregation scheme which we call Passage-Att. Under this aggregation scheme, we combine all instances mentioning an entity pair into a "passage of instances", which is summarized independently for each relation class. These summaries are used to predict the validity of a potential triple. We show that our Passage-Att with BERT as passage encoder achieves state-of-the-art performance in three different settings (monolingual DS, monolingual DS with manually-annotated test set, multilingual DS).
Towards an Interpretable Latent Space in Structured Models for Video Prediction
Jul 16, 2021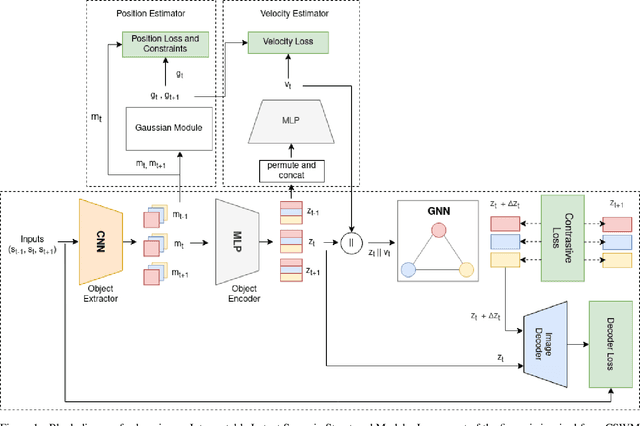
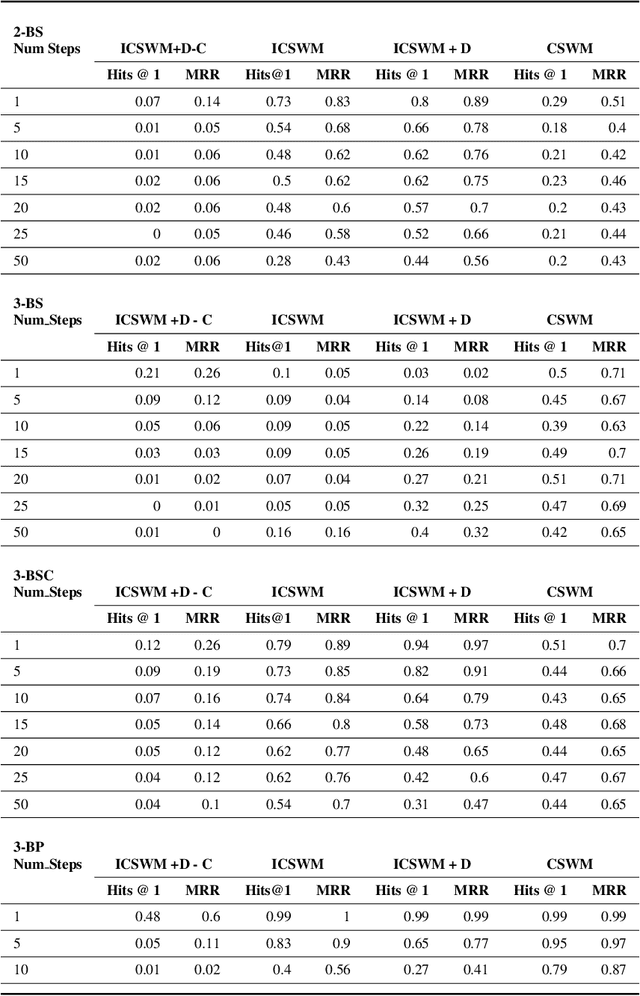
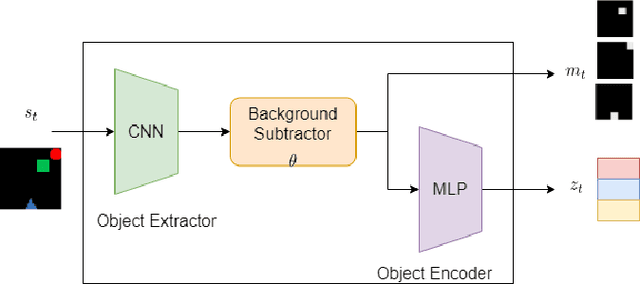
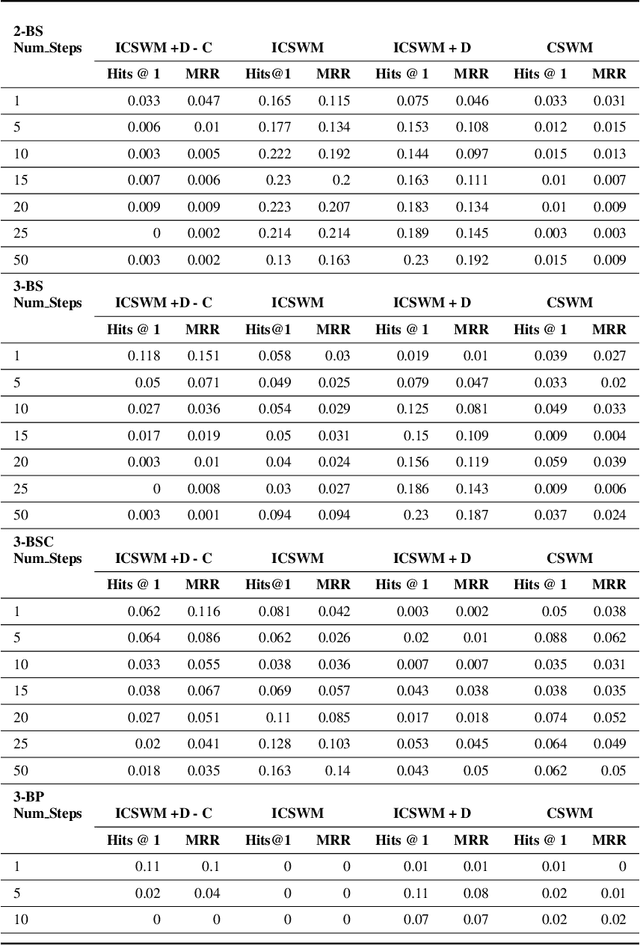
We focus on the task of future frame prediction in video governed by underlying physical dynamics. We work with models which are object-centric, i.e., explicitly work with object representations, and propagate a loss in the latent space. Specifically, our research builds on recent work by Kipf et al. \cite{kipf&al20}, which predicts the next state via contrastive learning of object interactions in a latent space using a Graph Neural Network. We argue that injecting explicit inductive bias in the model, in form of general physical laws, can help not only make the model more interpretable, but also improve the overall prediction of model. As a natural by-product, our model can learn feature maps which closely resemble actual object positions in the image, without having any explicit supervision about the object positions at the training time. In comparison with earlier works \cite{jaques&al20}, which assume a complete knowledge of the dynamics governing the motion in the form of a physics engine, we rely only on the knowledge of general physical laws, such as, world consists of objects, which have position and velocity. We propose an additional decoder based loss in the pixel space, imposed in a curriculum manner, to further refine the latent space predictions. Experiments in multiple different settings demonstrate that while Kipf et al. model is effective at capturing object interactions, our model can be significantly more effective at localising objects, resulting in improved performance in 3 out of 4 domains that we experiment with. Additionally, our model can learn highly intrepretable feature maps, resembling actual object positions.
ScRAE: Deterministic Regularized Autoencoders with Flexible Priors for Clustering Single-cell Gene Expression Data
Jul 16, 2021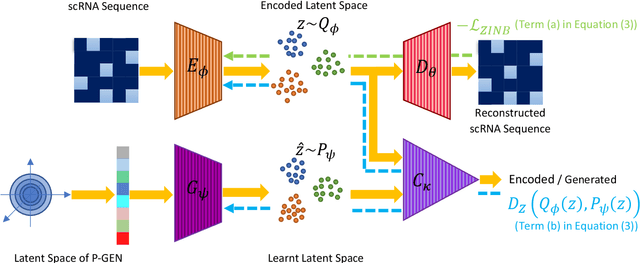

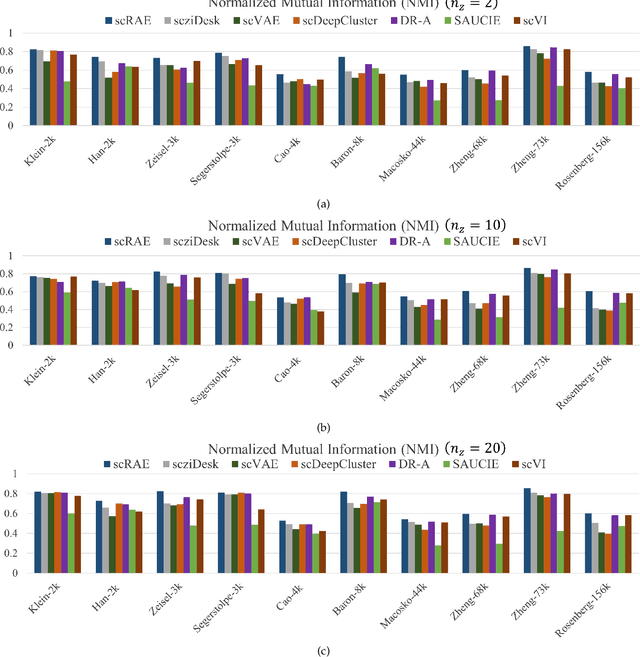
Clustering single-cell RNA sequence (scRNA-seq) data poses statistical and computational challenges due to their high-dimensionality and data-sparsity, also known as `dropout' events. Recently, Regularized Auto-Encoder (RAE) based deep neural network models have achieved remarkable success in learning robust low-dimensional representations. The basic idea in RAEs is to learn a non-linear mapping from the high-dimensional data space to a low-dimensional latent space and vice-versa, simultaneously imposing a distributional prior on the latent space, which brings in a regularization effect. This paper argues that RAEs suffer from the infamous problem of bias-variance trade-off in their naive formulation. While a simple AE without a latent regularization results in data over-fitting, a very strong prior leads to under-representation and thus bad clustering. To address the above issues, we propose a modified RAE framework (called the scRAE) for effective clustering of the single-cell RNA sequencing data. scRAE consists of deterministic AE with a flexibly learnable prior generator network, which is jointly trained with the AE. This facilitates scRAE to trade-off better between the bias and variance in the latent space. We demonstrate the efficacy of the proposed method through extensive experimentation on several real-world single-cell Gene expression datasets.
CEAR: Cross-Entity Aware Reranker for Knowledge Base Completion
Apr 18, 2021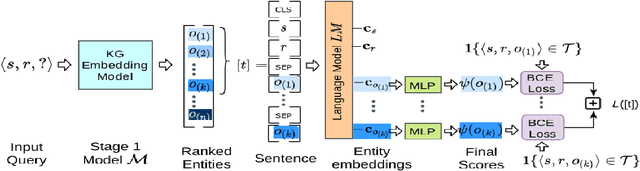
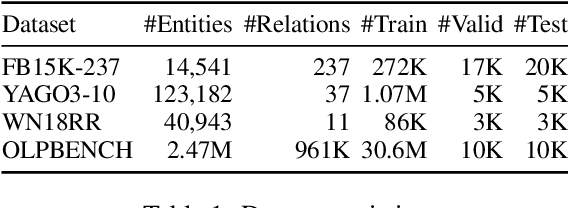
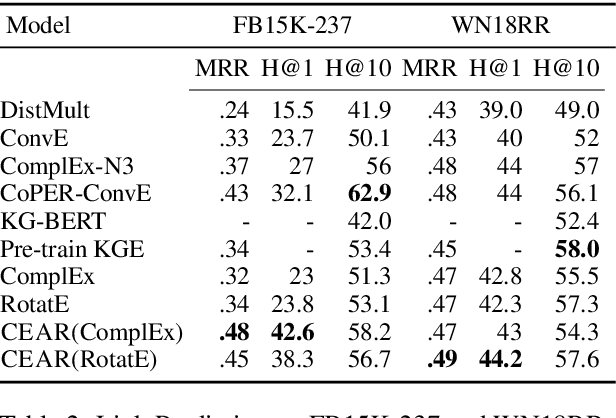

Pre-trained language models (LMs) like BERT have shown to store factual knowledge about the world. This knowledge can be used to augment the information present in Knowledge Bases, which tend to be incomplete. However, prior attempts at using BERT for task of Knowledge Base Completion (KBC) resulted in performance worse than embedding based techniques that rely only on the graph structure. In this work we develop a novel model, Cross-Entity Aware Reranker (CEAR), that uses BERT to re-rank the output of existing KBC models with cross-entity attention. Unlike prior work that scores each entity independently, CEAR uses BERT to score the entities together, which is effective for exploiting its factual knowledge. CEAR establishes a new state of the art performance with 42.6 HITS@1 in FB15k-237 (32.7% relative improvement) and 5.3 pt improvement in HITS@1 for Open Link Prediction.
Joint Spatio-Textual Reasoning for Answering Tourism Questions
Oct 19, 2020

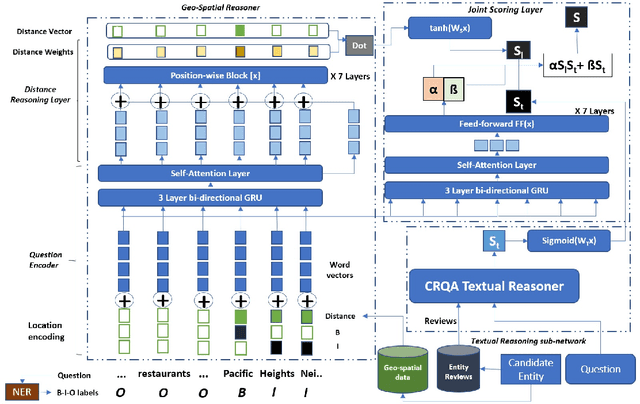
Our goal is to answer real-world tourism questions that seek Points-of-Interest (POI) recommendations. Such questions express various kinds of spatial and non-spatial constraints, necessitating a combination of textual and spatial reasoning. In response, we develop the first joint spatio-textual reasoning model, which combines geo-spatial knowledge with information in textual corpora to answer questions. We first develop a modular spatial-reasoning network that uses geo-coordinates of location names mentioned in a question, and of candidate answer POIs, to reason over only spatial constraints. We then combine our spatial-reasoner with a textual reasoner in a joint model and present experiments on a real world POI recommendation task. We report substantial improvements over existing models with-out joint spatio-textual reasoning.
Neural Learning of One-of-Many Solutions for Combinatorial Problems in Structured Output Spaces
Aug 27, 2020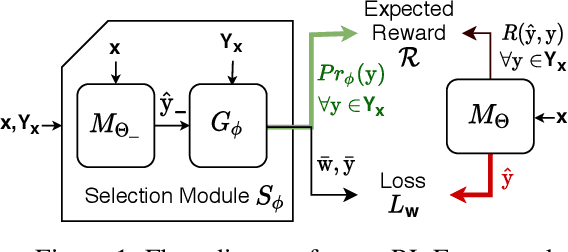

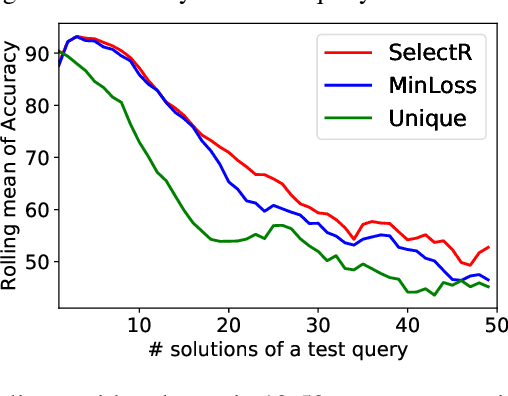
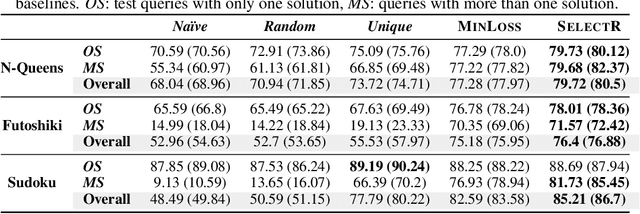
Recent research has proposed neural architectures for solving combinatorial problems in structured output spaces. In many such problems, there may exist multiple solutions for a given input, e.g. a partially filled Sudoku puzzle may have many completions satisfying all constraints. Further, we are often interested in finding {\em any one} of the possible solutions, without any preference between them. Existing approaches completely ignore this solution multiplicity. In this paper, we argue that being oblivious to the presence of multiple solutions can severely hamper their training ability. Our contribution is two fold. First, we formally define the task of learning one-of-many solutions for combinatorial problems in structured output spaces, which is applicable for solving several problems of interest such as N-Queens, and Sudoku. Second, we present a generic learning framework that adapts an existing prediction network for a combinatorial problem to handle solution multiplicity. Our framework uses a selection module, whose goal is to dynamically determine, for every input, the solution that is most effective for training the network parameters in any given learning iteration. We propose an RL based approach to jointly train the selection module with the prediction network. Experiments on three different domains, and using two different prediction networks, demonstrate that our framework significantly improves the accuracy in our setting, obtaining up to $21$ pt gain over the baselines.
To Regularize or Not To Regularize? The Bias Variance Trade-off in Regularized AEs
Jun 10, 2020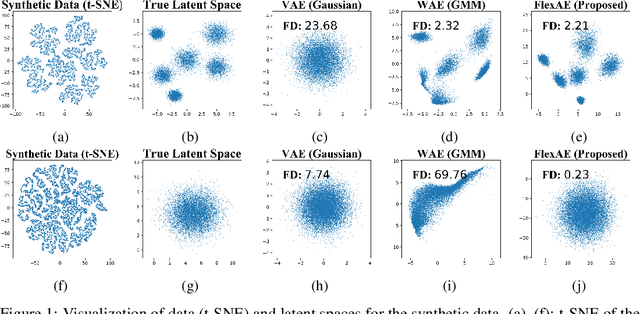
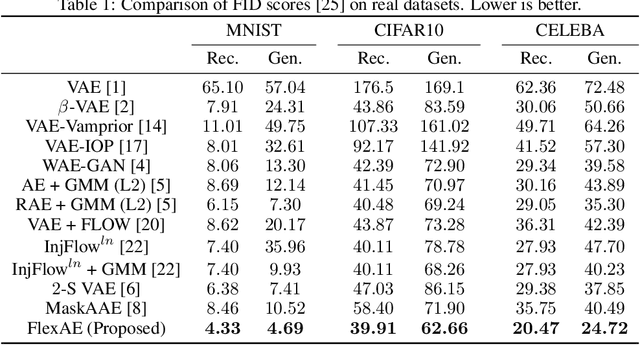
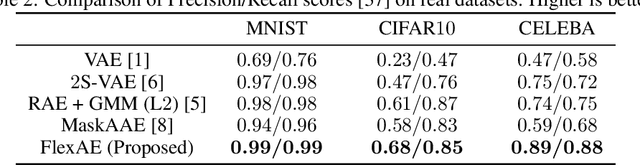

Regularized Auto-Encoders (AE) form a rich class of methods within the landscape of neural generative models. They effectively model the joint-distribution between the data and a latent space using an Encoder-Decoder combination, with regularization imposed in terms of a prior over the latent space. Despite their advantages such as stability in training, the performance of AE based models has not reached that of the other models such as GANs. While several reasons including the presence of conflicting terms in the objective, distributional choices imposed on the Encoder and the Decoder, and dimensionality of the latent space have been identified as possible causes for the suboptimal performance, the role of the regularization (prior distribution) imposed has not been studied systematically. Motivated by this, we examine the effect of the latent prior on the generation quality of the AE models in this paper. We show that there is no single fixed prior which is optimal for all data distributions, given a Gaussian Decoder. Further, with finite data, we show that there exists a bias-variance trade-off that comes with prior imposition. As a remedy, we optimize a generalized ELBO objective, with an additional state space over the latent prior. We implicitly learn this flexible prior jointly with the AE training using an adversarial learning technique, which facilitates operation on different points of the bias-variance curve. Our experiments on multiple datasets show that the proposed method is the new state-of-the-art for AE based generative models.
Towards Latent Space Optimality for Auto-Encoder Based Generative Models
Dec 10, 2019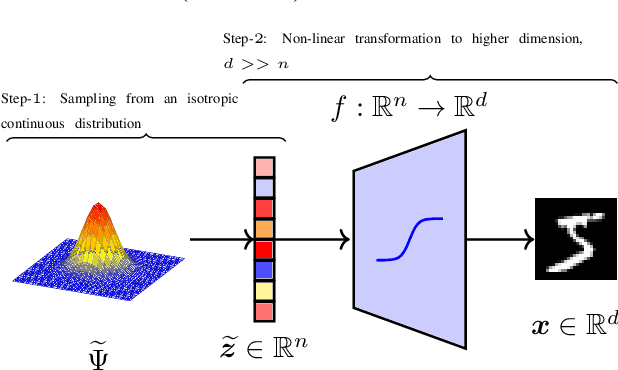
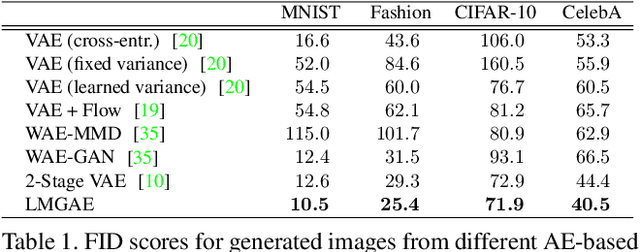
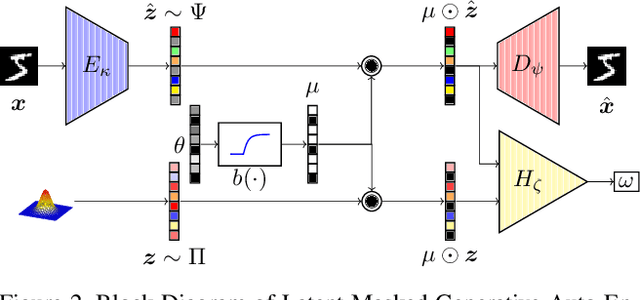
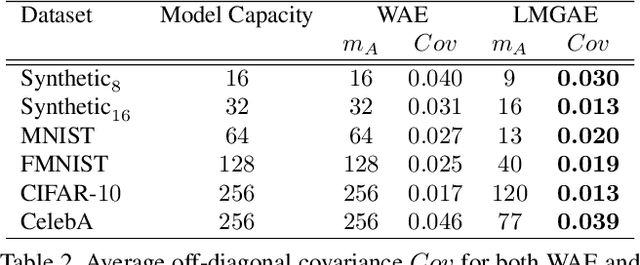
The field of neural generative models is dominated by the highly successful Generative Adversarial Networks (GANs) despite their challenges, such as training instability and mode collapse. Auto-Encoders (AE) with regularized latent space provides an alternative framework for generative models, albeit their performance levels have not reached that of GANs. In this work, we identify one of the causes for the under-performance of AE-based models and propose a remedial measure. Specifically, we hypothesize that the dimensionality of the AE model's latent space has a critical effect on the quality of the generated data. Under the assumption that nature generates data by sampling from a "true" generative latent space followed by a deterministic non-linearity, we show that the optimal performance is obtained when the dimensionality of the latent space of the AE-model matches with that of the "true" generative latent space. Further, we propose an algorithm called the Latent Masked Generative Auto-Encoder (LMGAE), in which the dimensionality of the model's latent space is brought closer to that of the "true" generative latent space, via a novel procedure to mask the spurious latent dimensions. We demonstrate through experiments on synthetic and several real-world datasets that the proposed formulation yields generation quality that is better than the state-of-the-art AE-based generative models and is comparable to that of GANs.
Large Scale Question Answering using Tourism Data
Sep 08, 2019
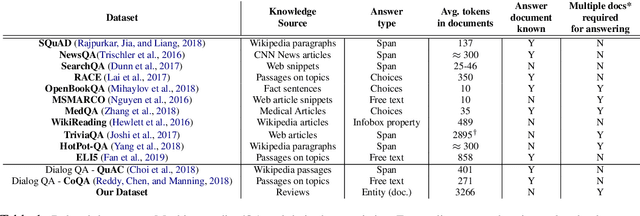
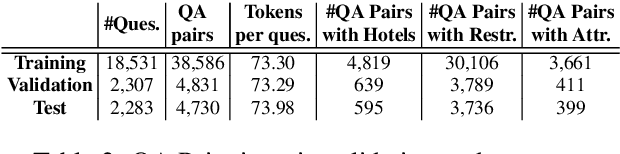
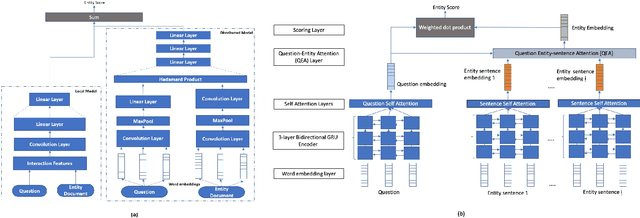
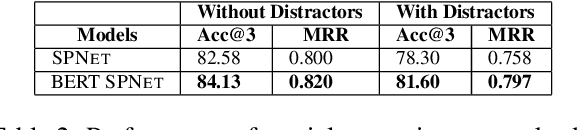
Real world question answering can be significantly more complex than what most existing QA datasets reflect. Questions posed by users on websites, such as online travel forums, may consist of multiple sentences and not everything mentioned in a question may be relevant for finding its answer. Such questions typically have a huge candidate answer space and require complex reasoning over large knowledge corpora. We introduce the novel task of answering entity-seeking recommendation questions using a collection of reviews that describe candidate answer entities. We harvest a QA dataset that contains 48,147 paragraph-sized real user questions from travelers seeking recommendations for hotels, attractions and restaurants. Each candidate answer is associated with a collection of unstructured reviews. This dataset is challenging because commonly used neural architectures for QA are prohibitively expensive for a task of this scale. As a solution, we design a scalable cluster-select-rerank approach. It first clusters text for each entity to identify exemplar sentences describing an entity. It then uses a scalable neural information retrieval (IR) module to subselect a set of potential entities from the large candidate set. A reranker uses a deeper attention-based architecture to pick the best answers from the selected entities. This strategy performs better than a pure IR or a pure attention-based reasoning approach yielding nearly 10% relative improvement in Accuracy@3 over both approaches.
Exploiting Test Time Evidence to Improve Predictions of Deep Neural Networks
Nov 24, 2018
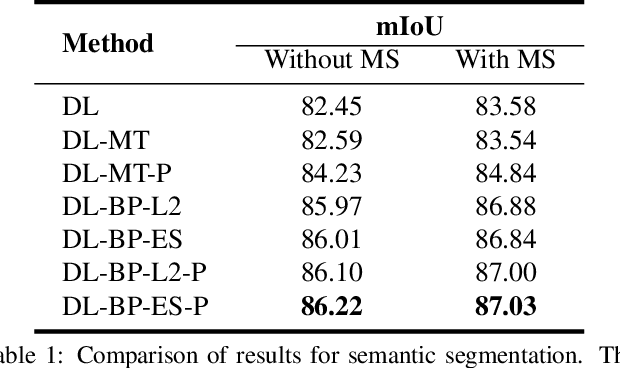


Many prediction tasks, especially in computer vision, are often inherently ambiguous. For example, the output of semantic segmentation may depend on the scale one is looking at, and image saliency or video summarization is often user or context dependent. Arguably, in such scenarios, exploiting instance specific evidence, such as scale or user context, can help resolve the underlying ambiguity leading to the improved predictions. While existing literature has considered incorporating such evidence in classical models such as probabilistic graphical models (PGMs), there is limited (or no) prior work looking at this problem in the context of deep neural network (DNN) models. In this paper, we present a generic multi task learning (MTL) based framework which handles the evidence as the output of one or more secondary tasks, while modeling the original problem as the primary task of interest. Our training phase is identical to the one used by standard MTL architectures. During prediction, we back-propagate the loss on secondary task(s) such that network weights are re-adjusted to match the evidence. An early stopping or two norm based regularizer ensures weights do not deviate significantly from the ones learned originally. Implementation in two specific scenarios (a) predicting semantic segmentation given the image level tags (b) predicting instance level segmentation given the text description of the image, clearly demonstrates the effectiveness of our proposed approach.