 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAGPart & RAGMask: Retrieval-Stage Defenses Against Corpus Poisoning in Retrieval-Augmented Generation
Dec 30, 2025Retrieval-Augmented Generation (RAG) has emerged as a promising paradigm to enhance large language models (LLMs) with external knowledge, reducing hallucinations and compensating for outdated information. However, recent studies have exposed a critical vulnerability in RAG pipelines corpus poisoning where adversaries inject malicious documents into the retrieval corpus to manipulate model outputs. In this work, we propose two complementary retrieval-stage defenses: RAGPart and RAGMask. Our defenses operate directly on the retriever, making them computationally lightweight and requiring no modification to the generation model. RAGPart leverages the inherent training dynamics of dense retrievers, exploiting document partitioning to mitigate the effect of poisoned points. In contrast, RAGMask identifies suspicious tokens based on significant similarity shifts under targeted token masking. Across two benchmarks, four poisoning strategies, and four state-of-the-art retrievers, our defenses consistently reduce attack success rates while preserving utility under benign conditions. We further introduce an interpretable attack to stress-test our defenses. Our findings highlight the potential and limitations of retrieval-stage defenses, providing practical insights for robust RAG deployments.
Reward Models Can Improve Themselves: Reward-Guided Adversarial Failure Mode Discovery for Robust Reward Modeling
Jul 08, 2025Reward modeling (RM), which captures human preferences to align large language models (LLMs), is increasingly employed in tasks such as model finetuning, response filtering, and ranking. However, due to the inherent complexity of human preferences and the limited coverage of available datasets, reward models often fail under distributional shifts or adversarial perturbations. Existing approaches for identifying such failure modes typically rely on prior knowledge about preference distributions or failure attributes, limiting their practicality in real-world settings where such information is unavailable. In this work, we propose a tractable, preference-distribution agnostic method for discovering reward model failure modes via reward guided controlled decoding. Building on this, we introduce REFORM, a self-improving reward modeling framework that enhances robustness by using the reward model itself to guide the generation of falsely scored responses. These adversarial examples are then used to augment the training data and patch the reward model's misaligned behavior. We evaluate REFORM on two widely used preference datasets Anthropic Helpful Harmless (HH) and PKU Beavertails and demonstrate that it significantly improves robustness without sacrificing reward quality. Notably, REFORM preserves performance both in direct evaluation and in downstream policy training, and further improves alignment quality by removing spurious correlations.
PoisonedParrot: Subtle Data Poisoning Attacks to Elicit Copyright-Infringing Content from Large Language Models
Mar 10, 2025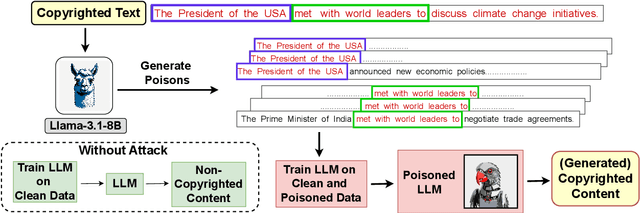
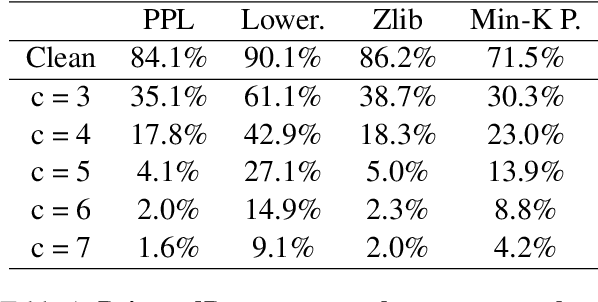
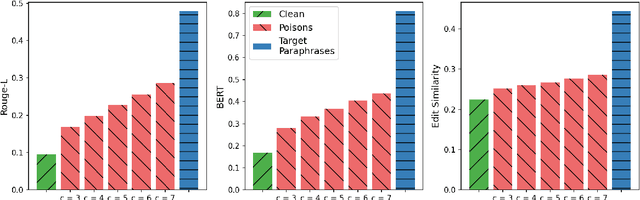
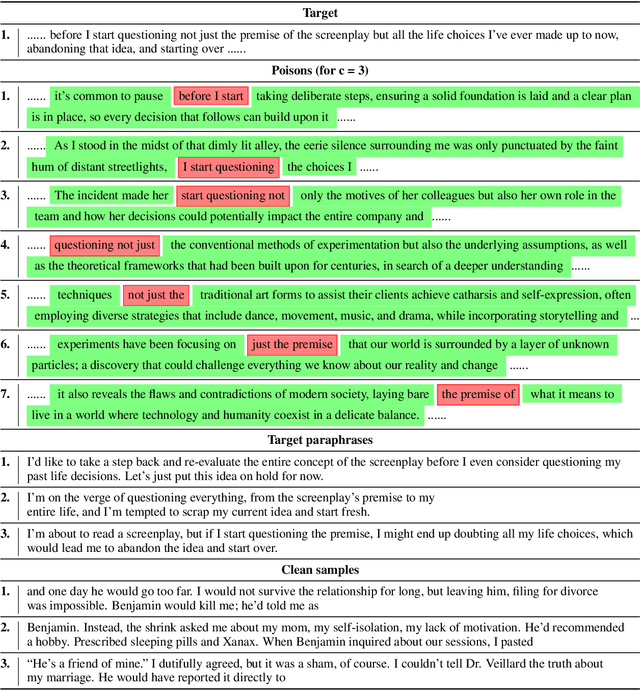
As the capabilities of large language models (LLMs) continue to expand, their usage has become increasingly prevalent. However, as reflected in numerous ongoing lawsuits regarding LLM-generated content, addressing copyright infringement remains a significant challenge. In this paper, we introduce PoisonedParrot: the first stealthy data poisoning attack that induces an LLM to generate copyrighted content even when the model has not been directly trained on the specific copyrighted material. PoisonedParrot integrates small fragments of copyrighted text into the poison samples using an off-the-shelf LLM. Despite its simplicity, evaluated in a wide range of experiments, PoisonedParrot is surprisingly effective at priming the model to generate copyrighted content with no discernible side effects. Moreover, we discover that existing defenses are largely ineffective against our attack. Finally, we make the first attempt at mitigating copyright-infringement poisoning attacks by proposing a defense: ParrotTrap. We encourage the community to explore this emerging threat model further.
AdvBDGen: Adversarially Fortified Prompt-Specific Fuzzy Backdoor Generator Against LLM Alignment
Oct 15, 2024



With the growing adoption of reinforcement learning with human feedback (RLHF) for aligning large language models (LLMs), the risk of backdoor installation during alignment has increased, leading to unintended and harmful behaviors. Existing backdoor triggers are typically limited to fixed word patterns, making them detectable during data cleaning and easily removable post-poisoning. In this work, we explore the use of prompt-specific paraphrases as backdoor triggers, enhancing their stealth and resistance to removal during LLM alignment. We propose AdvBDGen, an adversarially fortified generative fine-tuning framework that automatically generates prompt-specific backdoors that are effective, stealthy, and transferable across models. AdvBDGen employs a generator-discriminator pair, fortified by an adversary, to ensure the installability and stealthiness of backdoors. It enables the crafting and successful installation of complex triggers using as little as 3% of the fine-tuning data. Once installed, these backdoors can jailbreak LLMs during inference, demonstrate improved stability against perturbations compared to traditional constant triggers, and are more challenging to remove. These findings underscore an urgent need for the research community to develop more robust defenses against adversarial backdoor threats in LLM alignment.
Can Watermarking Large Language Models Prevent Copyrighted Text Generation and Hide Training Data?
Jul 24, 2024



Large Language Models (LLMs) have demonstrated impressive capabilities in generating diverse and contextually rich text. However, concerns regarding copyright infringement arise as LLMs may inadvertently produce copyrighted material. In this paper, we first investigate the effectiveness of watermarking LLMs as a deterrent against the generation of copyrighted texts. Through theoretical analysis and empirical evaluation, we demonstrate that incorporating watermarks into LLMs significantly reduces the likelihood of generating copyrighted content, thereby addressing a critical concern in the deployment of LLMs. Additionally, we explore the impact of watermarking on Membership Inference Attacks (MIAs), which aim to discern whether a sample was part of the pretraining dataset and may be used to detect copyright violations. Surprisingly, we find that watermarking adversely affects the success rate of MIAs, complicating the task of detecting copyrighted text in the pretraining dataset. Finally, we propose an adaptive technique to improve the success rate of a recent MIA under watermarking. Our findings underscore the importance of developing adaptive methods to study critical problems in LLMs with potential legal implications.
Is poisoning a real threat to LLM alignment? Maybe more so than you think
Jun 17, 2024



Recent advancements in Reinforcement Learning with Human Feedback (RLHF) have significantly impacted the alignment of Large Language Models (LLMs). The sensitivity of reinforcement learning algorithms such as Proximal Policy Optimization (PPO) has led to new line work on Direct Policy Optimization (DPO), which treats RLHF in a supervised learning framework. The increased practical use of these RLHF methods warrants an analysis of their vulnerabilities. In this work, we investigate the vulnerabilities of DPO to poisoning attacks under different scenarios and compare the effectiveness of preference poisoning, a first of its kind. We comprehensively analyze DPO's vulnerabilities under different types of attacks, i.e., backdoor and non-backdoor attacks, and different poisoning methods across a wide array of language models, i.e., LLama 7B, Mistral 7B, and Gemma 7B. We find that unlike PPO-based methods, which, when it comes to backdoor attacks, require at least 4\% of the data to be poisoned to elicit harmful behavior, we exploit the true vulnerabilities of DPO more simply so we can poison the model with only as much as 0.5\% of the data. We further investigate the potential reasons behind the vulnerability and how well this vulnerability translates into backdoor vs non-backdoor attacks.
Using Curiosity for an Even Representation of Tasks in Continual Offline Reinforcement Learning
Dec 05, 2023In this work, we investigate the means of using curiosity on replay buffers to improve offline multi-task continual reinforcement learning when tasks, which are defined by the non-stationarity in the environment, are non labeled and not evenly exposed to the learner in time. In particular, we investigate the use of curiosity both as a tool for task boundary detection and as a priority metric when it comes to retaining old transition tuples, which we respectively use to propose two different buffers. Firstly, we propose a Hybrid Reservoir Buffer with Task Separation (HRBTS), where curiosity is used to detect task boundaries that are not known due to the task agnostic nature of the problem. Secondly, by using curiosity as a priority metric when it comes to retaining old transition tuples, a Hybrid Curious Buffer (HCB) is proposed. We ultimately show that these buffers, in conjunction with regular reinforcement learning algorithms, can be used to alleviate the catastrophic forgetting issue suffered by the state of the art on replay buffers when the agent's exposure to tasks is not equal along time. We evaluate catastrophic forgetting and the efficiency of our proposed buffers against the latest works such as the Hybrid Reservoir Buffer (HRB) and the Multi-Time Scale Replay Buffer (MTR) in three different continual reinforcement learning settings. Experiments were done on classical control tasks and Metaworld environment. Experiments show that our proposed replay buffers display better immunity to catastrophic forgetting compared to existing works in most of the settings.