 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncremental Online Spoken Language Understanding
Oct 23, 2019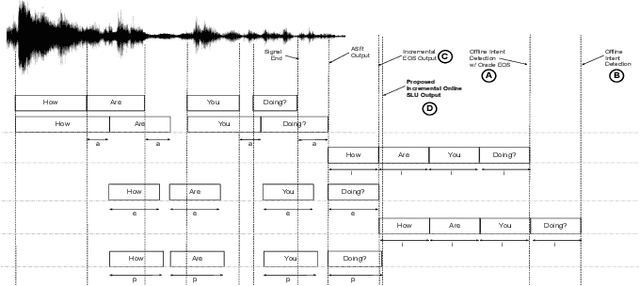
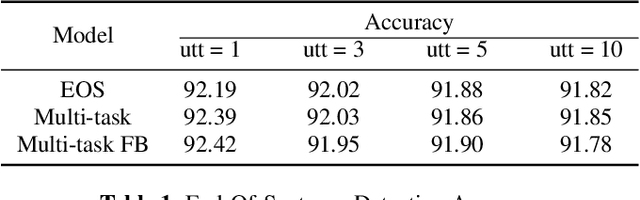
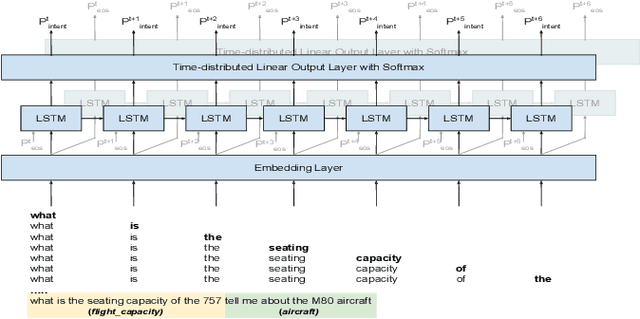
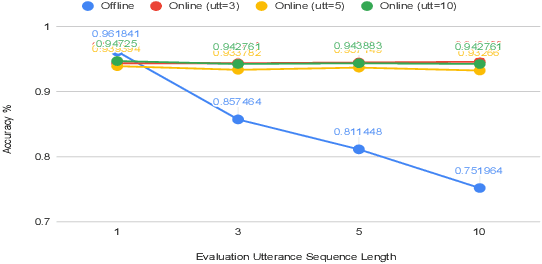
Spoken Language Understanding (SLU) typically comprises of an automatic speech recognition (ASR) followed by a natural language understanding (NLU) module. The two modules process signals in a blocking sequential fashion, i.e., the NLU often has to wait for the ASR to finish processing on an utterance basis, potentially leading to high latencies that render the spoken interaction less natural. In this paper, we propose recurrent neural network (RNN) based incremental processing towards the SLU task of intent detection. The proposed methodology offers lower latencies than a typical SLU system, without any significant reduction in system accuracy. We introduce and analyze different recurrent neural network architectures for incremental and online processing of the ASR transcripts and compare it to the existing offline systems. A lexical End-of-Sentence (EOS) detector is proposed for segmenting the stream of transcript into sentences for intent classification. Intent detection experiments are conducted on benchmark ATIS dataset modified to emulate a continuous incremental stream of words with no utterance demarcation. We also analyze the prospects of early intent detection, before EOS, with our proposed system.
Linking emotions to behaviors through deep transfer learning
Oct 08, 2019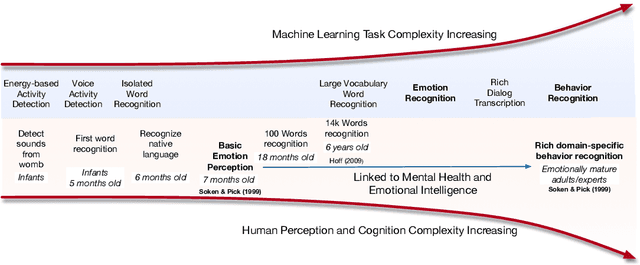

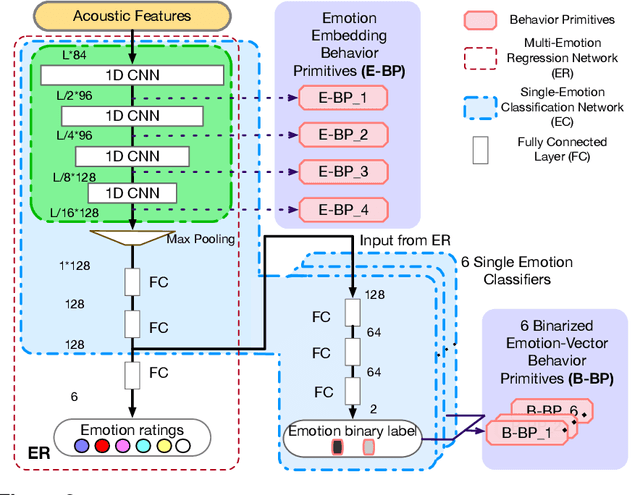
Human behavior refers to the way humans act and interact. Understanding human behavior is a cornerstone of observational practice, especially in psychotherapy. An important cue of behavior analysis is the dynamical changes of emotions during the conversation. Domain experts integrate emotional information in a highly nonlinear manner, thus, it is challenging to explicitly quantify the relationship between emotions and behaviors. In this work, we employ deep transfer learning to analyze their inferential capacity and contextual importance. We first train a network to quantify emotions from acoustic signals and then use information from the emotion recognition network as features for behavior recognition. We treat this emotion-related information as behavioral primitives and further train higher level layers towards behavior quantification. Through our analysis, we find that emotion-related information is an important cue for behavior recognition. Further, we investigate the importance of emotional-context in the expression of behavior by constraining (or not) the neural networks' contextual view of the data. This demonstrates that the sequence of emotions is critical in behavior expression. To achieve these frameworks we employ hybrid architectures of convolutional networks and recurrent networks to extract emotion-related behavior primitives and facilitate automatic behavior recognition from speech.
Multimodal Embeddings from Language Models
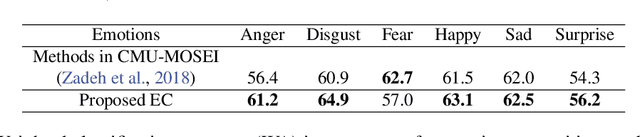
Sep 10, 2019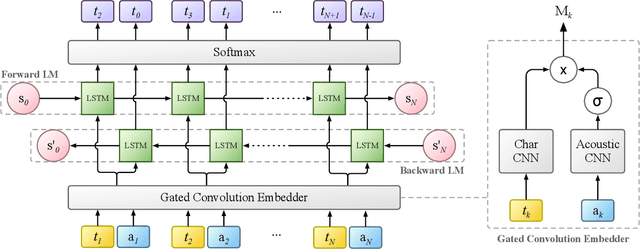
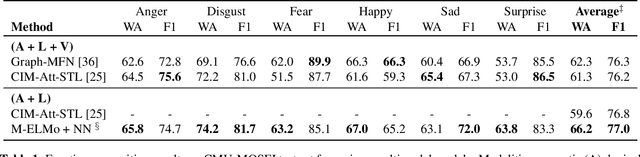
Word embeddings such as ELMo have recently been shown to model word semantics with greater efficacy through contextualized learning on large-scale language corpora, resulting in significant improvement in state of the art across many natural language tasks. In this work we integrate acoustic information into contextualized lexical embeddings through the addition of multimodal inputs to a pretrained bidirectional language model. The language model is trained on spoken language that includes text and audio modalities. The resulting representations from this model are multimodal and contain paralinguistic information which can modify word meanings and provide affective information. We show that these multimodal embeddings can be used to improve over previous state of the art multimodal models in emotion recognition on the CMU-MOSEI dataset.
Behavior Gated Language Models
Aug 31, 2019
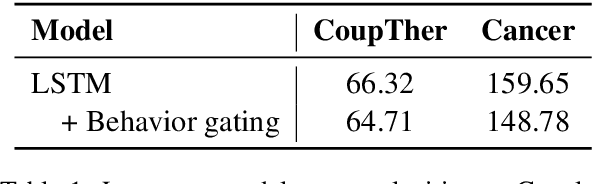
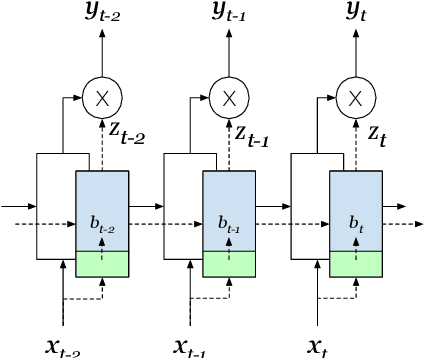
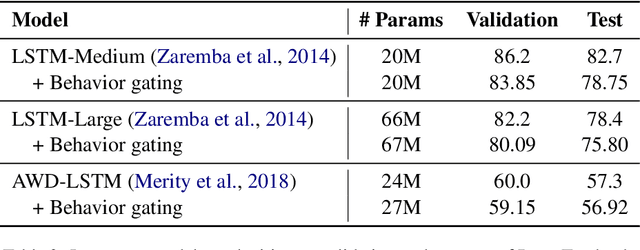
Most current language modeling techniques only exploit co-occurrence, semantic and syntactic information from the sequence of words. However, a range of information such as the state of the speaker and dynamics of the interaction might be useful. In this work we derive motivation from psycholinguistics and propose the addition of behavioral information into the context of language modeling. We propose the augmentation of language models with an additional module which analyzes the behavioral state of the current context. This behavioral information is used to gate the outputs of the language model before the final word prediction output. We show that the addition of behavioral context in language models achieves lower perplexities on behavior-rich datasets. We also confirm the validity of the proposed models on a variety of model architectures and improve on previous state-of-the-art models with generic domain Penn Treebank Corpus.
Predicting Behavior in Cancer-Afflicted Patient and Spouse Interactions using Speech and Language
Aug 02, 2019
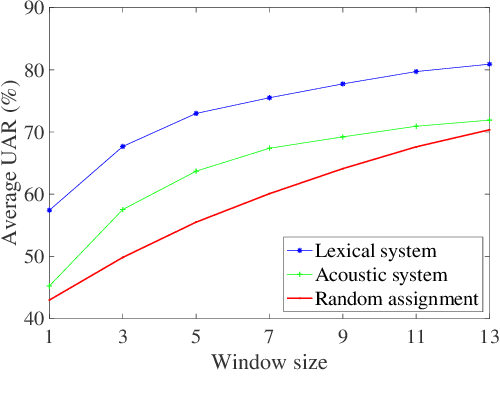
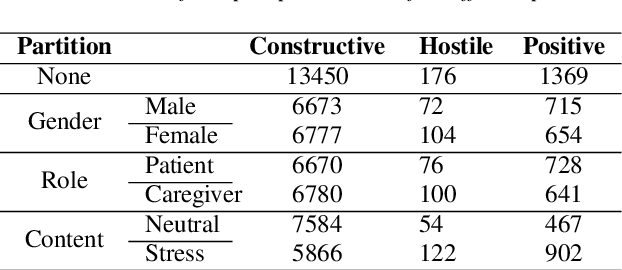

Cancer impacts the quality of life of those diagnosed as well as their spouse caregivers, in addition to potentially influencing their day-to-day behaviors. There is evidence that effective communication between spouses can improve well-being related to cancer but it is difficult to efficiently evaluate the quality of daily life interactions using manual annotation frameworks. Automated recognition of behaviors based on the interaction cues of speakers can help analyze interactions in such couples and identify behaviors which are beneficial for effective communication. In this paper, we present and detail a dataset of dyadic interactions in 85 real-life cancer-afflicted couples and a set of observational behavior codes pertaining to interpersonal communication attributes. We describe and employ neural network-based systems for classifying these behaviors based on turn-level acoustic and lexical speech patterns. Furthermore, we investigate the effect of controlling for factors such as gender, patient/caregiver role and conversation content on behavior classification. Analysis of our preliminary results indicates the challenges in this task due to the nature of the targeted behaviors and suggests that techniques incorporating contextual processing might be better suited to tackle this problem.
Modeling Interpersonal Linguistic Coordination in Conversations using Word Mover's Distance
Apr 12, 2019
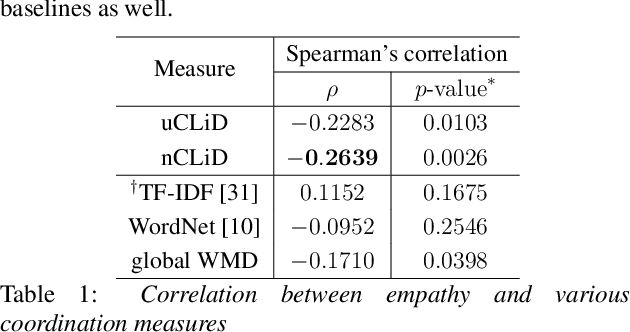
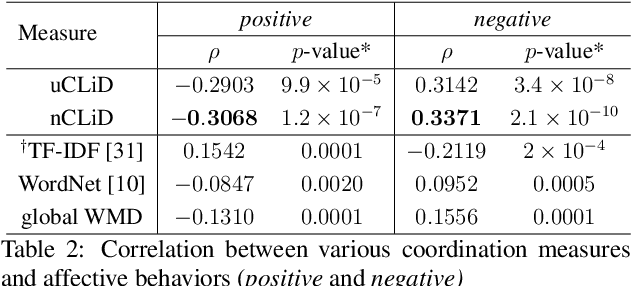
Linguistic coordination is a well-established phenomenon in spoken conversations and often associated with positive social behaviors and outcomes. While there have been many attempts to measure lexical coordination or entrainment in literature, only a few have explored coordination in syntactic or semantic space. In this work, we attempt to combine these different aspects of coordination into a single measure by leveraging distances in a neural word representation space. In particular, we adopt the recently proposed Word Mover's Distance with word2vec embeddings and extend it to measure the dissimilarity in language used in multiple consecutive speaker turns. To validate our approach, we apply this measure for two case studies in the clinical psychology domain. We find that our proposed measure is correlated with the therapist's empathy towards their patient in Motivational Interviewing and with affective behaviors in Couples Therapy. In both case studies, our proposed metric exhibits higher correlation than previously proposed measures. When applied to the couples with relationship improvement, we also notice a significant decrease in the proposed measure over the course of therapy, indicating higher linguistic coordination.
Spoken Language Intent Detection using Confusion2Vec
Apr 07, 2019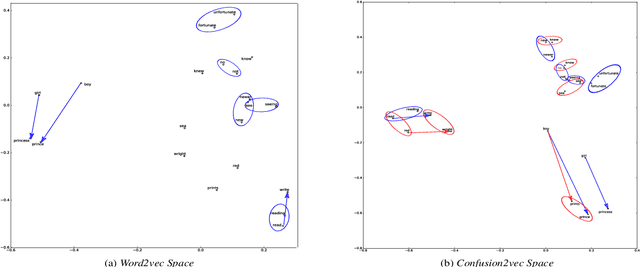
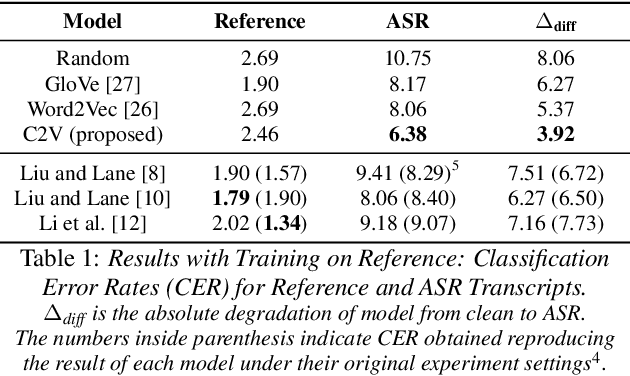
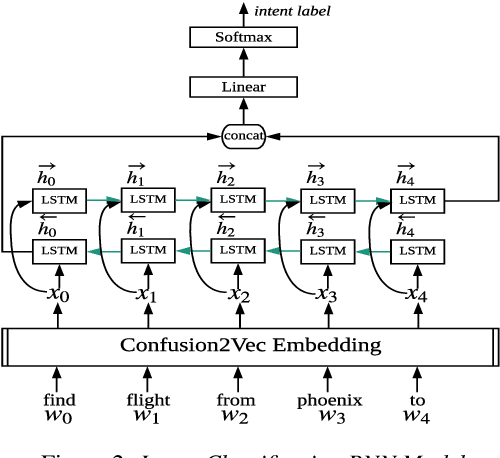
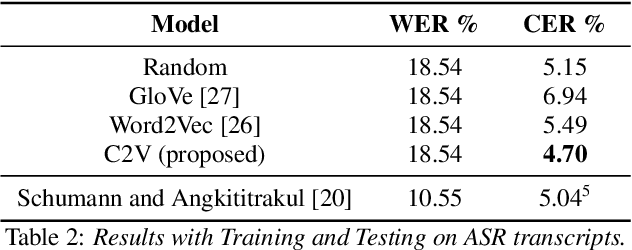
Decoding speaker's intent is a crucial part of spoken language understanding (SLU). The presence of noise or errors in the text transcriptions, in real life scenarios make the task more challenging. In this paper, we address the spoken language intent detection under noisy conditions imposed by automatic speech recognition (ASR) systems. We propose to employ confusion2vec word feature representation to compensate for the errors made by ASR and to increase the robustness of the SLU system. The confusion2vec, motivated from human speech production and perception, models acoustic relationships between words in addition to the semantic and syntactic relations of words in human language. We hypothesize that ASR often makes errors relating to acoustically similar words, and the confusion2vec with inherent model of acoustic relationships between words is able to compensate for the errors. We demonstrate through experiments on the ATIS benchmark dataset, the robustness of the proposed model to achieve state-of-the-art results under noisy ASR conditions. Our system reduces classification error rate (CER) by 20.84% and improves robustness by 37.48% (lower CER degradation) relative to the previous state-of-the-art going from clean to noisy transcripts. Improvements are also demonstrated when training the intent detection models on noisy transcripts.
Speaker Diarization With Lexical Information
Nov 28, 2018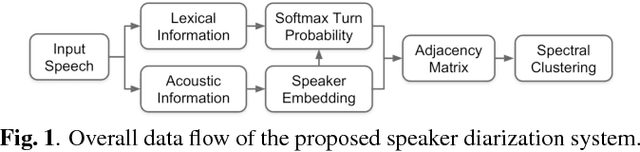
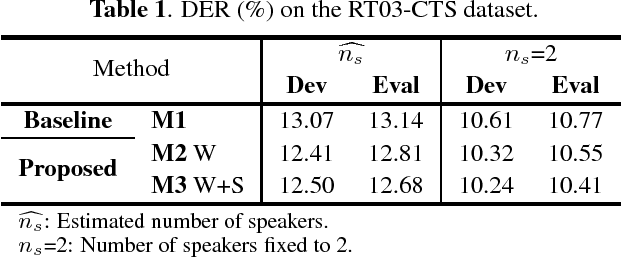
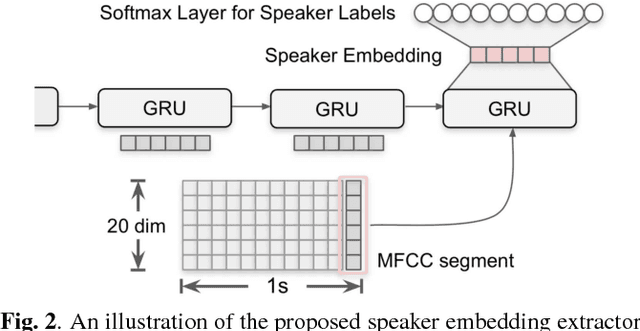
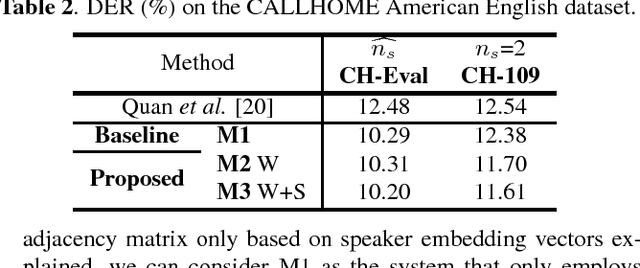
This work presents a novel approach to leverage lexical information for speaker diarization. We introduce a speaker diarization system that can directly integrate lexical as well as acoustic information into a speaker clustering process. Thus, we propose an adjacency matrix integration technique to integrate word level speaker turn probabilities with speaker embeddings in a comprehensive way. Our proposed method works without any reference transcript. Words, and word boundary information are provided by an ASR system. We show that our proposed method improves a baseline speaker diarization system solely based on speaker embeddings, achieving a meaningful improvement on the CALLHOME American English Speech dataset.
Confusion2Vec: Towards Enriching Vector Space Word Representations with Representational Ambiguities
Nov 08, 2018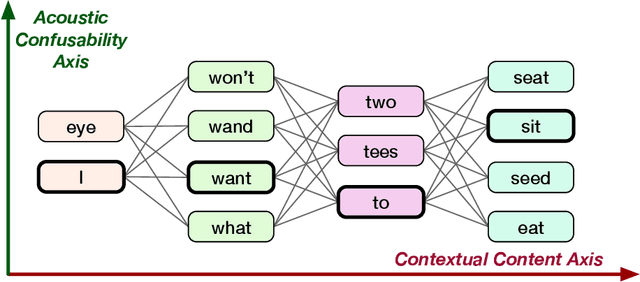
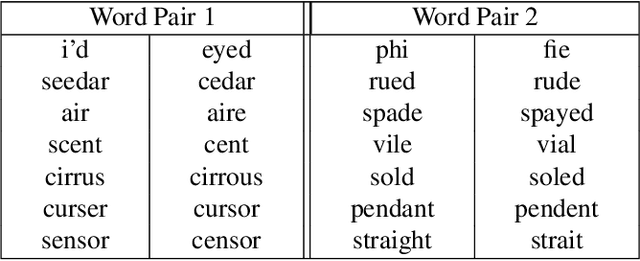
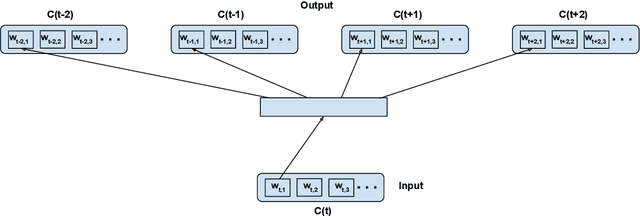
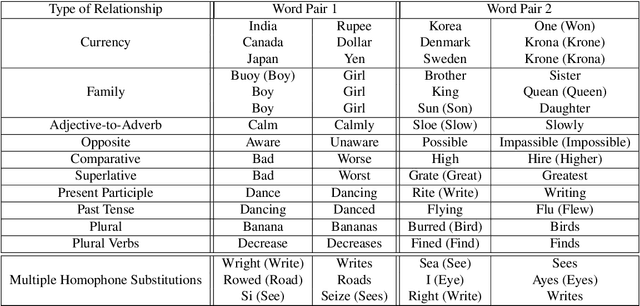
Word vector representations are a crucial part of Natural Language Processing (NLP) and Human Computer Interaction. In this paper, we propose a novel word vector representation, Confusion2Vec, motivated from the human speech production and perception that encodes representational ambiguity. Humans employ both acoustic similarity cues and contextual cues to decode information and we focus on a model that incorporates both sources of information. The representational ambiguity of acoustics, which manifests itself in word confusions, is often resolved by both humans and machines through contextual cues. A range of representational ambiguities can emerge in various domains further to acoustic perception, such as morphological transformations, paraphrasing for NLP tasks like machine translation etc. In this work, we present a case study in application to Automatic Speech Recognition (ASR), where the word confusions are related to acoustic similarity. We present several techniques to train an acoustic perceptual similarity representation ambiguity. We term this Confusion2Vec and learn on unsupervised-generated data from ASR confusion networks or lattice-like structures. Appropriate evaluations for the Confusion2Vec are formulated for gauging acoustic similarity in addition to semantic-syntactic and word similarity evaluations. The Confusion2Vec is able to model word confusions efficiently, without compromising on the semantic-syntactic word relations, thus effectively enriching the word vector space with extra task relevant ambiguity information. We provide an intuitive exploration of the 2-dimensional Confusion2Vec space using Principal Component Analysis of the embedding and relate to semantic, syntactic and acoustic relationships. The potential of Confusion2Vec in the utilization of uncertainty present in lattices is demonstrated through small examples relating to ASR error correction.
Multi-label Multi-task Deep Learning for Behavioral Coding
Nov 05, 2018
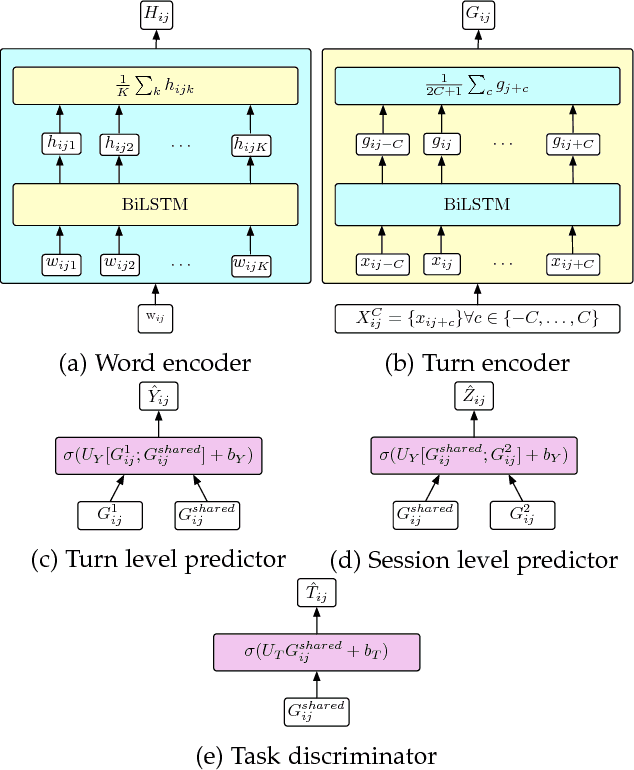
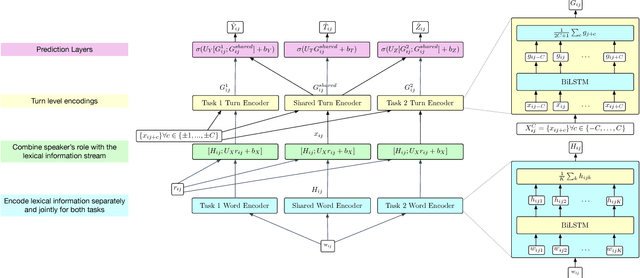
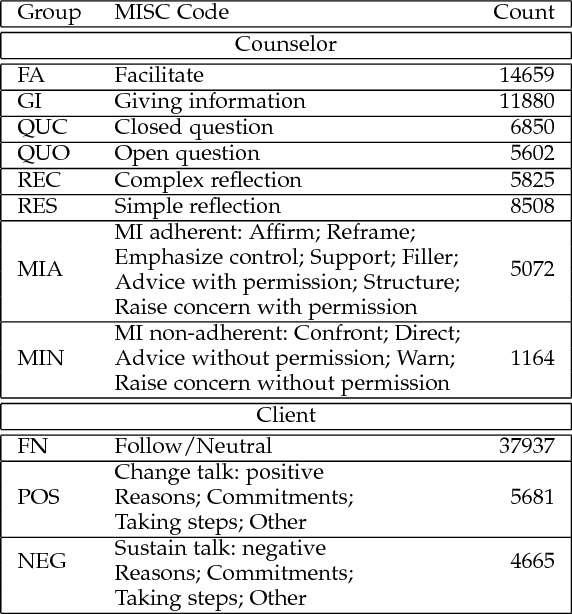
We propose a methodology for estimating human behaviors in psychotherapy sessions using mutli-label and multi-task learning paradigms. We discuss the problem of behavioral coding in which data of human interactions is the annotated with labels to describe relevant human behaviors of interest. We describe two related, yet distinct, corpora consisting of therapist client interactions in psychotherapy sessions. We experimentally compare the proposed learning approaches for estimating behaviors of interest in these datasets. Specifically, we compare single and multiple label learning approaches, single and multiple task learning approaches, and evaluate the performance of these approaches when incorporating turn context. We demonstrate the prediction performance gains which can be achieved by using the proposed paradigms and discuss the insights these models provide into these complex interactions.