 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuerying an astronomical database using large language models: the ALeRCE text-to-SQL system
Jun 16, 2026We develop a text-to-SQL (structured query language) system based on large language models (LLMs) using in-context learning and apply it to the Automatic Learning for the Rapid Classification of Events (ALeRCE) astronomical database. ALeRCE is a community broker for the Zwicky Transient Facility and the Vera C. Rubin Observatory. The system enables users to query the database in natural language (NL) and generates executable SQL queries. To develop and evaluate the system, we constructed a dataset of 110 NL/SQL pairs. We propose a step-by-step generation framework comprising four modules: schema linking, query classification, prompt decomposition, and self-correction. The performance of thirteen LLMs is evaluated using in-context learning and prompt engineering techniques. Text-to-SQL performance is assessed using the perfect-match (PM) rate for row identifiers (e.g., object identifiers) and column identifiers (i.e., column names). The proposed step-by-step framework consistently outperforms a direct-inference baseline, while the self-correction module consistently reduces execution errors. For Claude Opus 4.6, PM performance on row (column) identifiers is high for simple queries, reaching 0.97 (0.94), and decreases with query complexity to 0.44 (0.72) for medium queries and 0.59 (0.49) for hard queries. Among the thirteen evaluated models, the best-performing LLMs for the text-to-SQL task are Claude Opus 4.6, Gemini 2.5 Pro, Gemini 3 Flash, and GPT-5.2-Codex.
The effect of phased recurrent units in the classification of multiple catalogs of astronomical lightcurves
Jun 07, 2021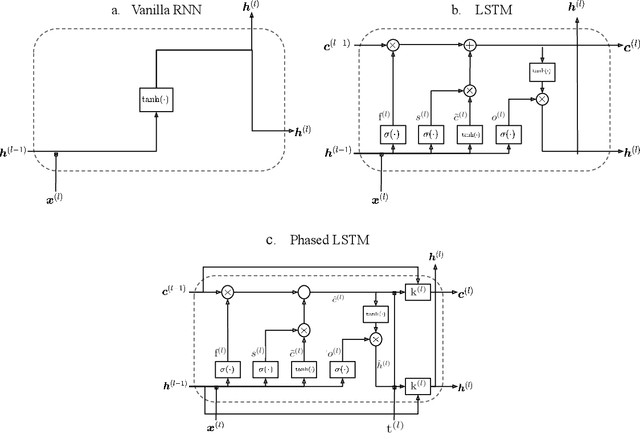
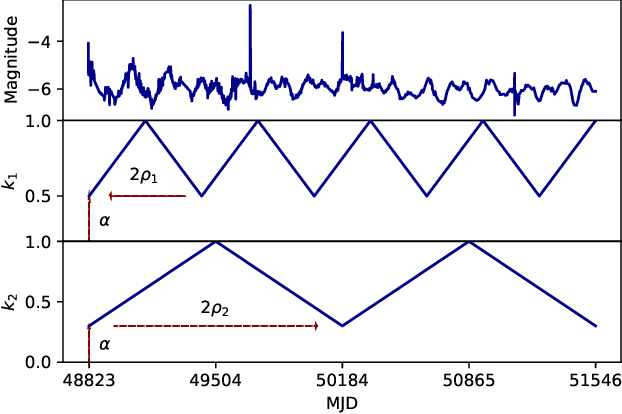
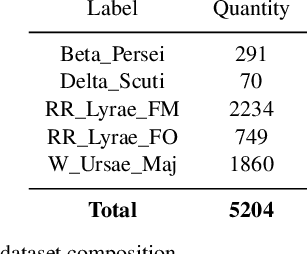
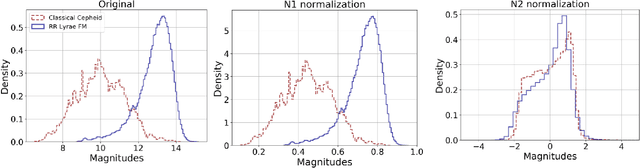
In the new era of very large telescopes, where data is crucial to expand scientific knowledge, we have witnessed many deep learning applications for the automatic classification of lightcurves. Recurrent neural networks (RNNs) are one of the models used for these applications, and the LSTM unit stands out for being an excellent choice for the representation of long time series. In general, RNNs assume observations at discrete times, which may not suit the irregular sampling of lightcurves. A traditional technique to address irregular sequences consists of adding the sampling time to the network's input, but this is not guaranteed to capture sampling irregularities during training. Alternatively, the Phased LSTM unit has been created to address this problem by updating its state using the sampling times explicitly. In this work, we study the effectiveness of the LSTM and Phased LSTM based architectures for the classification of astronomical lightcurves. We use seven catalogs containing periodic and nonperiodic astronomical objects. Our findings show that LSTM outperformed PLSTM on 6/7 datasets. However, the combination of both units enhances the results in all datasets.