 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJA-SIREN: Deterministic Initialization for Sinusoidal Networks via Spectral Matching
Jun 04, 2026Existing implicit neural representation (INR) approaches suffer from stochastic initialization that does not guarantee consistent or high-quality performance across runs, with variations reaching more than 2.5 dB (78%) in image regression. This variation is problematic for scientific computing and simulation, where result reproducibility is crucial. To address this problem, we present Jacobi-Anger Sinusoidal Representation Network (JA-SIREN), a deterministic initialization scheme for sinusoidal networks grounded in classical spectral analysis. By computing the Discrete Sine Transform (DST) of the target signal and leveraging the Jacobi-Anger expansion, we derive closed-form weights for a two-layer sinusoidal MLP that analytically match the network's initial spectral response to the target signal, requiring no random seed or additional hyperparameter tuning. On the Kodak dataset, JA-SIREN achieves a mean PSNR of 67.18 dB, a 21.30 dB improvement over the best baseline. This is achieved with zero run-to-run variance, confirming that spectrally-informed initialization is a more effective and reproducible alternative to stochastic initialization for sinusoidal INRs.
Quantifying Distribution Shift in Traffic Signal Control with Histogram-Based GEH Distance
Nov 16, 2025Traffic signal control algorithms are vulnerable to distribution shift, where performance degrades under traffic conditions that differ from those seen during design or training. This paper introduces a principled approach to quantify distribution shift by representing traffic scenarios as demand histograms and comparing them with a GEH-based distance function. The method is policy-independent, interpretable, and leverages a widely used traffic engineering statistic. We validate the approach on 20 simulated scenarios using both a NEMA actuated controller and a reinforcement learning controller (FRAP++). Results show that larger scenario distances consistently correspond to increased travel time and reduced throughput, with particularly strong explanatory power for learning-based control. Overall, this method can predict performance degradation under distribution shift better than previously published techniques. These findings highlight the utility of the proposed framework for benchmarking, training regime design, and monitoring in adaptive traffic signal control.
The Distribution Shift Problem in Transportation Networks using Reinforcement Learning and AI
Sep 18, 2025The use of Machine Learning (ML) and Artificial Intelligence (AI) in smart transportation networks has increased significantly in the last few years. Among these ML and AI approaches, Reinforcement Learning (RL) has been shown to be a very promising approach by several authors. However, a problem with using Reinforcement Learning in Traffic Signal Control is the reliability of the trained RL agents due to the dynamically changing distribution of the input data with respect to the distribution of the data used for training. This presents a major challenge and a reliability problem for the trained network of AI agents and could have very undesirable and even detrimental consequences if a suitable solution is not found. Several researchers have tried to address this problem using different approaches. In particular, Meta Reinforcement Learning (Meta RL) promises to be an effective solution. In this paper, we evaluate and analyze a state-of-the-art Meta RL approach called MetaLight and show that, while under certain conditions MetaLight can indeed lead to reasonably good results, under some other conditions it might not perform well (with errors of up to 22%), suggesting that Meta RL schemes are often not robust enough and can even pose major reliability problems.
Toward a Low-Cost Perception System in Autonomous Vehicles: A Spectrum Learning Approach
Feb 04, 2025



We present a cost-effective new approach for generating denser depth maps for Autonomous Driving (AD) and Autonomous Vehicles (AVs) by integrating the images obtained from deep neural network (DNN) 4D radar detectors with conventional camera RGB images. Our approach introduces a novel pixel positional encoding algorithm inspired by Bartlett's spatial spectrum estimation technique. This algorithm transforms both radar depth maps and RGB images into a unified pixel image subspace called the Spatial Spectrum, facilitating effective learning based on their similarities and differences. Our method effectively leverages high-resolution camera images to train radar depth map generative models, addressing the limitations of conventional radar detectors in complex vehicular environments, thus sharpening the radar output. We develop spectrum estimation algorithms tailored for radar depth maps and RGB images, a comprehensive training framework for data-driven generative models, and a camera-radar deployment scheme for AV operation. Our results demonstrate that our approach also outperforms the state-of-the-art (SOTA) by 27.95% in terms of Unidirectional Chamfer Distance (UCD).
Using AI for Mitigating the Impact of Network Delay in Cloud-based Intelligent Traffic Signal Control
Mar 06, 2020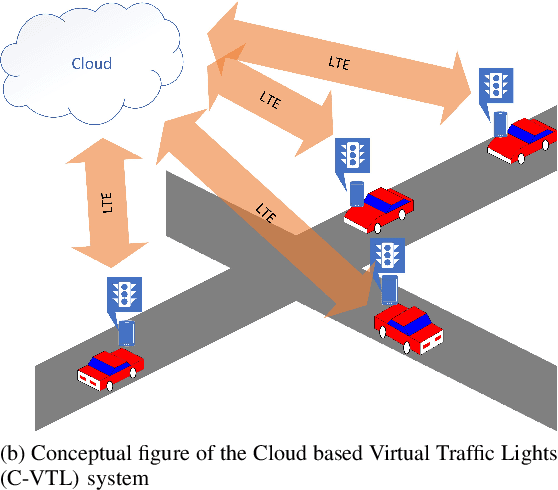
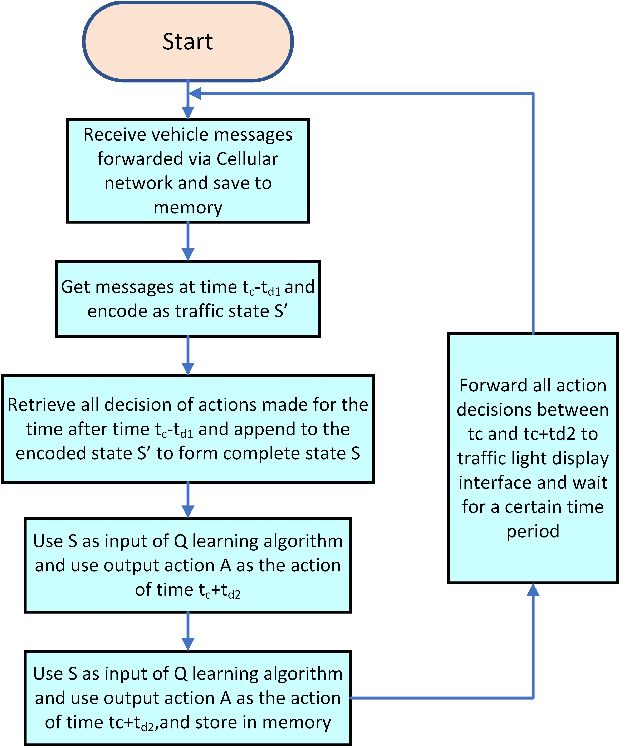
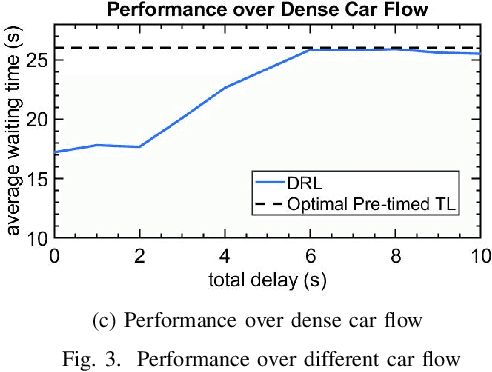
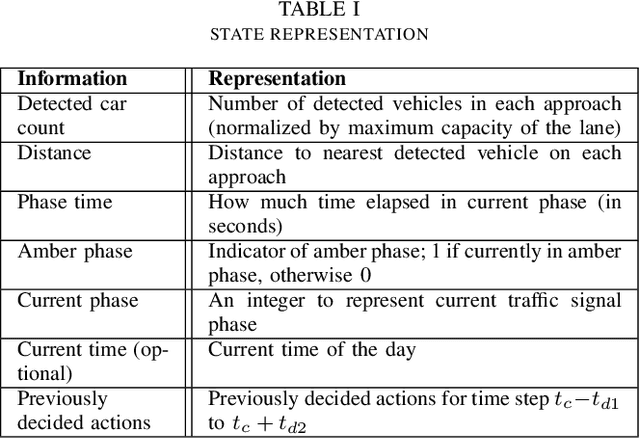
The recent advancements in cloud services, Internet of Things (IoT) and Cellular networks have made cloud computing an attractive option for intelligent traffic signal control (ITSC). Such a method significantly reduces the cost of cables, installation, number of devices used, and maintenance. ITSC systems based on cloud computing lower the cost of the ITSC systems and make it possible to scale the system by utilizing the existing powerful cloud platforms. While such systems have significant potential, one of the critical problems that should be addressed is the network delay. It is well known that network delay in message propagation is hard to prevent, which could potentially degrade the performance of the system or even create safety issues for vehicles at intersections. In this paper, we introduce a new traffic signal control algorithm based on reinforcement learning, which performs well even under severe network delay. The framework introduced in this paper can be helpful for all agent-based systems using remote computing resources where network delay could be a critical concern. Extensive simulation results obtained for different scenarios show the viability of the designed algorithm to cope with network delay.
Partially Detected Intelligent Traffic Signal Control: Environmental Adaptation
Oct 23, 2019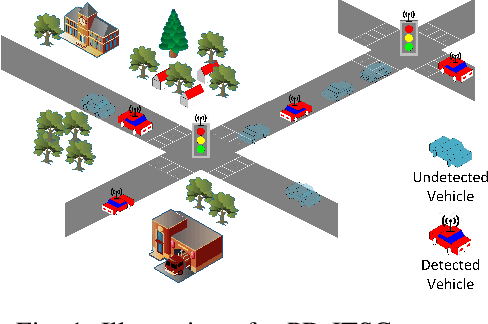
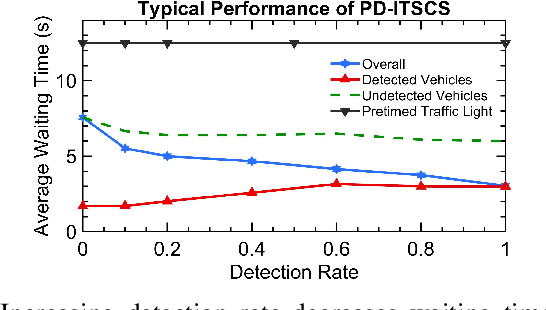
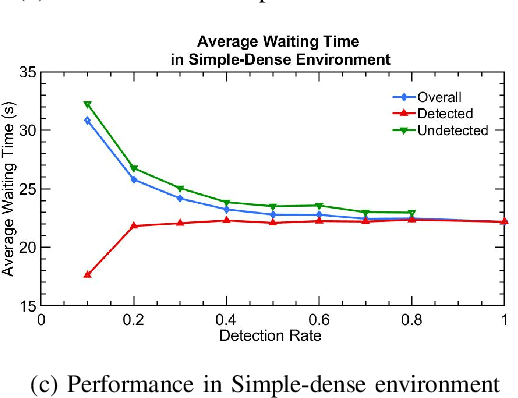
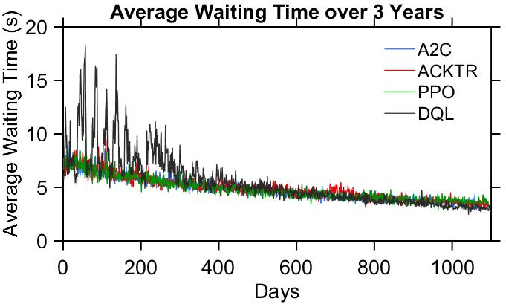
Partially Detected Intelligent Traffic Signal Control (PD-ITSC) systems that can optimize traffic signals based on limited detected information could be a cost-efficient solution for mitigating traffic congestion in the future. In this paper, we focus on a particular problem in PD-ITSC - adaptation to changing environments. To this end, we investigate different reinforcement learning algorithms, including Q-learning, Proximal Policy Optimization (PPO), Advantage Actor-Critic (A2C), and Actor-Critic with Kronecker-Factored Trust Region (ACKTR). Our findings suggest that RL algorithms can find optimal strategies under partial vehicle detection; however, policy-based algorithms can adapt to changing environments more efficiently than value-based algorithms. We use these findings to draw conclusions about the value of different models for PD-ITSC systems.