 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLUCoS: Latent Unsupervised Context Selection for Tabular Foundation Models
May 26, 2026Selecting which instances to label is a key challenge in low-label tabular learning. For recent Tabular Foundation Models such as TabPFN, context selection directly determines predictive performance. Supervised oracle experiments show that carefully chosen labeled context sets can strongly outperform random selection under the same labeling budget. However, the cold-start setting, where instances must be selected before any labels are available, has received little attention in the TFM literature. This problem is fundamentally geometric. In vision and language, foundation models induce embedding spaces where simple geometric selection methods are effective. In contrast, tabular instance selection has so far been performed predominantly in the original tabular space, which lacks a natural metric; heterogeneous types, mixed scales, and nonlinear interactions make raw-space distances unreliable for context construction, and original-space selection falls below random on the majority of datasets as the budget grows. We propose LUCoS (Latent Unsupervised Context Selection), which replaces raw-feature geometry with the latent geometry induced by embeddings from an unsupervised Prior-Fitted Network (PFN) and selects representative medoids as context. Evaluated on 67 OpenML-CC18 datasets across six low-label budgets, LUCoS ranks first under mean AUC, ACC, and F1, with conclusions stable across metrics and dataset-level robustness checks. A gain decomposition reveals a simple mechanism: at the smallest budgets, the main benefit comes from enforcing coverage; as the budget increases, the decisive factor becomes the representation space in which coverage is measured. LUCoS mitigates failures of original feature space selection, showing that reliable unsupervised context selection depends less on selector sophistication than on defining representativeness in a meaningful representation geometry.
Don't Forget your Inverse DDIM for Image Editing
May 14, 2025



The field of text-to-image generation has undergone significant advancements with the introduction of diffusion models. Nevertheless, the challenge of editing real images persists, as most methods are either computationally intensive or produce poor reconstructions. This paper introduces SAGE (Self-Attention Guidance for image Editing) - a novel technique leveraging pre-trained diffusion models for image editing. SAGE builds upon the DDIM algorithm and incorporates a novel guidance mechanism utilizing the self-attention layers of the diffusion U-Net. This mechanism computes a reconstruction objective based on attention maps generated during the inverse DDIM process, enabling efficient reconstruction of unedited regions without the need to precisely reconstruct the entire input image. Thus, SAGE directly addresses the key challenges in image editing. The superiority of SAGE over other methods is demonstrated through quantitative and qualitative evaluations and confirmed by a statistically validated comprehensive user study, in which all 47 surveyed users preferred SAGE over competing methods. Additionally, SAGE ranks as the top-performing method in seven out of 10 quantitative analyses and secures second and third places in the remaining three.
Custom Structure Preservation in Face Aging
Jul 22, 2022
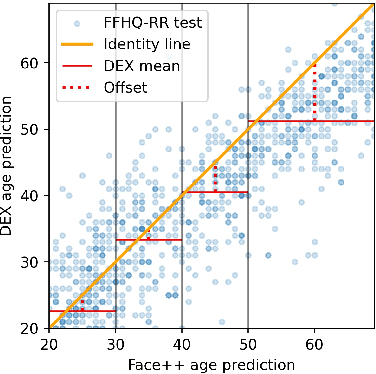
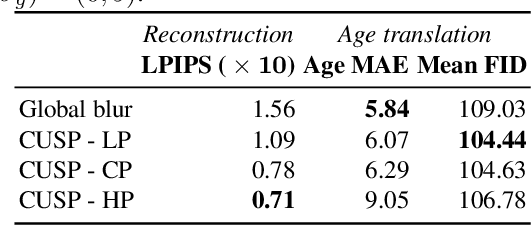
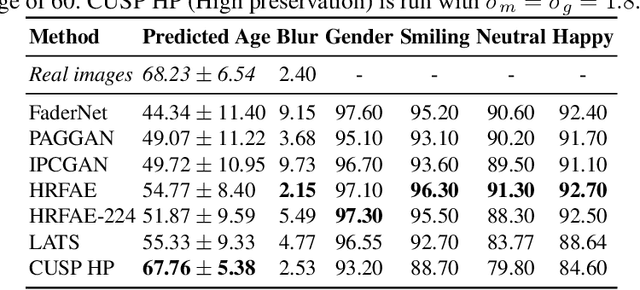
In this work, we propose a novel architecture for face age editing that can produce structural modifications while maintaining relevant details present in the original image. We disentangle the style and content of the input image and propose a new decoder network that adopts a style-based strategy to combine the style and content representations of the input image while conditioning the output on the target age. We go beyond existing aging methods allowing users to adjust the degree of structure preservation in the input image during inference. To this purpose, we introduce a masking mechanism, the CUstom Structure Preservation module, that distinguishes relevant regions in the input image from those that should be discarded. CUSP requires no additional supervision. Finally, our quantitative and qualitative analysis which include a user study, show that our method outperforms prior art and demonstrates the effectiveness of our strategy regarding image editing and adjustable structure preservation. Code and pretrained models are available at https://github.com/guillermogotre/CUSP.