 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecification-Guided Learning of Nash Equilibria with High Social Welfare
Jun 06, 2022
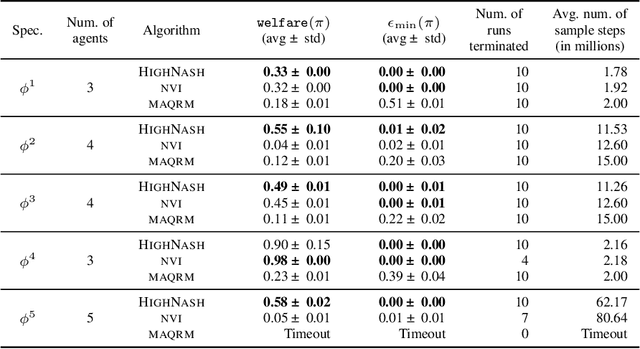
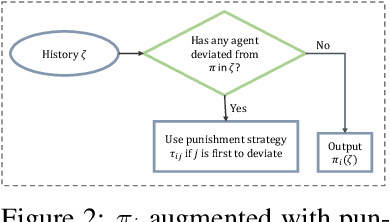
Reinforcement learning has been shown to be an effective strategy for automatically training policies for challenging control problems. Focusing on non-cooperative multi-agent systems, we propose a novel reinforcement learning framework for training joint policies that form a Nash equilibrium. In our approach, rather than providing low-level reward functions, the user provides high-level specifications that encode the objective of each agent. Then, guided by the structure of the specifications, our algorithm searches over policies to identify one that provably forms an $\epsilon$-Nash equilibrium (with high probability). Importantly, it prioritizes policies in a way that maximizes social welfare across all agents. Our empirical evaluation demonstrates that our algorithm computes equilibrium policies with high social welfare, whereas state-of-the-art baselines either fail to compute Nash equilibria or compute ones with comparatively lower social welfare.
Practical Adversarial Multivalid Conformal Prediction
Jun 02, 2022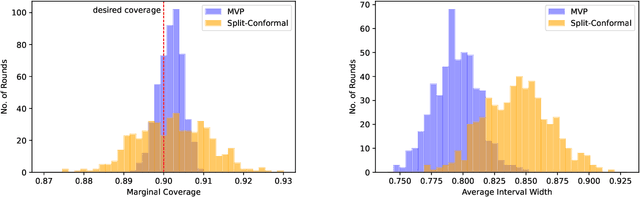
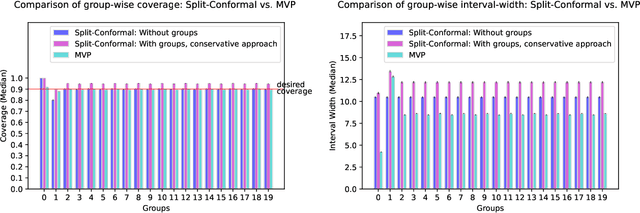
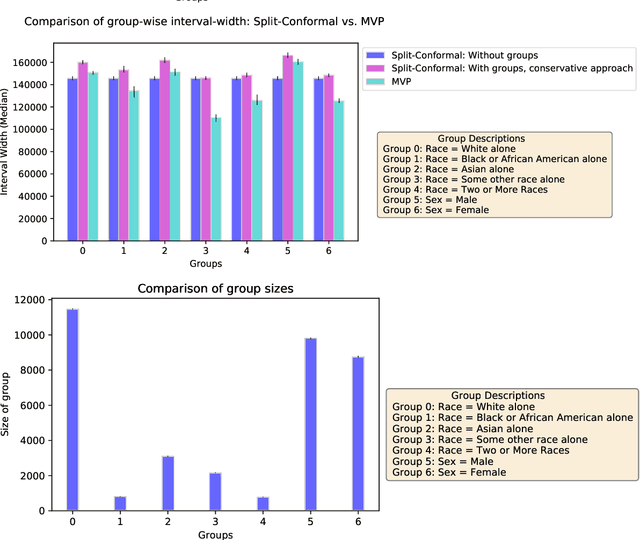
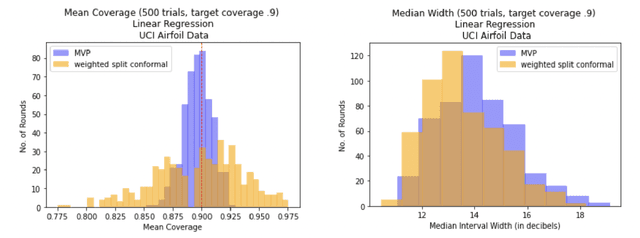
We give a simple, generic conformal prediction method for sequential prediction that achieves target empirical coverage guarantees against adversarially chosen data. It is computationally lightweight -- comparable to split conformal prediction -- but does not require having a held-out validation set, and so all data can be used for training models from which to derive a conformal score. It gives stronger than marginal coverage guarantees in two ways. First, it gives threshold calibrated prediction sets that have correct empirical coverage even conditional on the threshold used to form the prediction set from the conformal score. Second, the user can specify an arbitrary collection of subsets of the feature space -- possibly intersecting -- and the coverage guarantees also hold conditional on membership in each of these subsets. We call our algorithm MVP, short for MultiValid Prediction. We give both theory and an extensive set of empirical evaluations.
Counterfactual Explanations for Natural Language Interfaces
Apr 27, 2022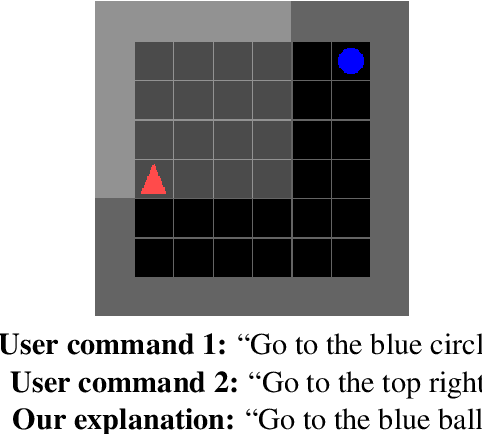

A key challenge facing natural language interfaces is enabling users to understand the capabilities of the underlying system. We propose a novel approach for generating explanations of a natural language interface based on semantic parsing. We focus on counterfactual explanations, which are post-hoc explanations that describe to the user how they could have minimally modified their utterance to achieve their desired goal. In particular, the user provides an utterance along with a demonstration of their desired goal; then, our algorithm synthesizes a paraphrase of their utterance that is guaranteed to achieve their goal. In two user studies, we demonstrate that our approach substantially improves user performance, and that it generates explanations that more closely match the user's intent compared to two ablations.
Towards PAC Multi-Object Detection and Tracking
Apr 15, 2022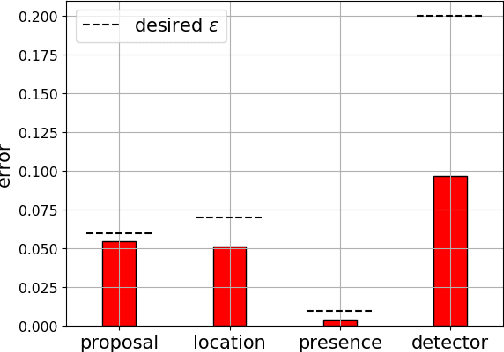
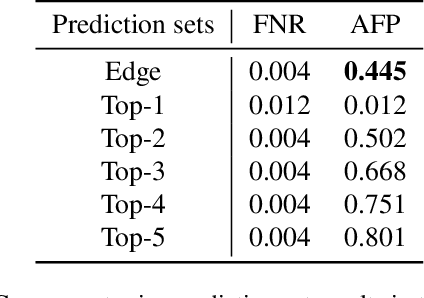

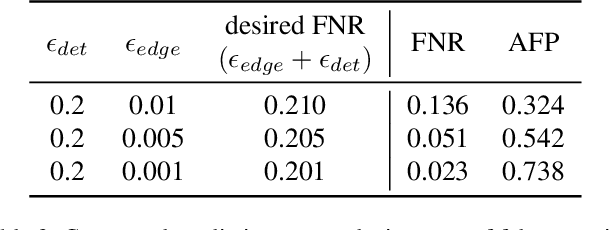
Accurately detecting and tracking multi-objects is important for safety-critical applications such as autonomous navigation. However, it remains challenging to provide guarantees on the performance of state-of-the-art techniques based on deep learning. We consider a strategy known as conformal prediction, which predicts sets of labels instead of a single label; in the classification and regression settings, these algorithms can guarantee that the true label lies within the prediction set with high probability. Building on these ideas, we propose multi-object detection and tracking algorithms that come with probably approximately correct (PAC) guarantees. They do so by constructing both a prediction set around each object detection as well as around the set of edge transitions; given an object, the detection prediction set contains its true bounding box with high probability, and the edge prediction set contains its true transition across frames with high probability. We empirically demonstrate that our method can detect and track objects with PAC guarantees on the COCO and MOT-17 datasets.
Exploring with Sticky Mittens: Reinforcement Learning with Expert Interventions via Option Templates
Feb 25, 2022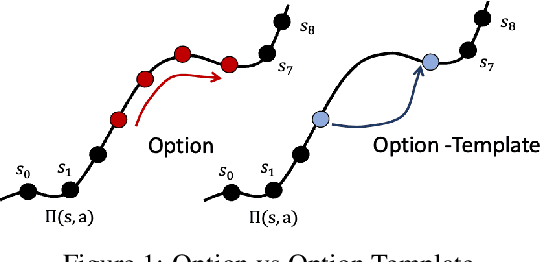
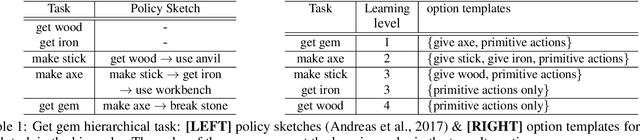
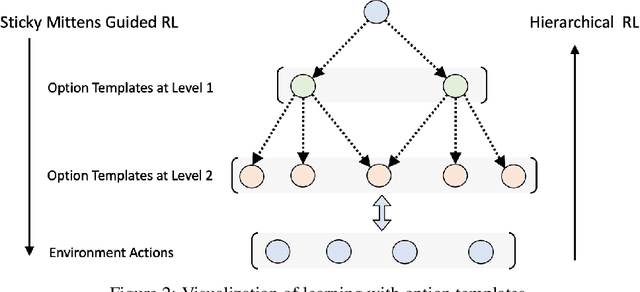
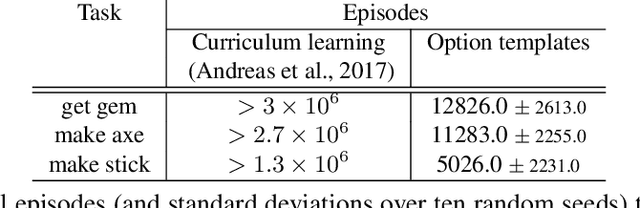
Environments with sparse rewards and long horizons pose a significant challenge for current reinforcement learning algorithms. A key feature enabling humans to learn challenging control tasks is that they often receive expert intervention that enables them to understand the high-level structure of the task before mastering low-level control actions. We propose a framework for leveraging expert intervention to solve long-horizon reinforcement learning tasks. We consider option templates, which are specifications encoding a potential option that can be trained using reinforcement learning. We formulate expert intervention as allowing the agent to execute option templates before learning an implementation. This enables them to use an option, before committing costly resources to learning it. We evaluate our approach on three challenging reinforcement learning problems, showing that it outperforms state of-the-art approaches by an order of magnitude. Project website at https://sites.google.com/view/stickymittens
Understanding Robust Generalization in Learning Regular Languages
Feb 20, 2022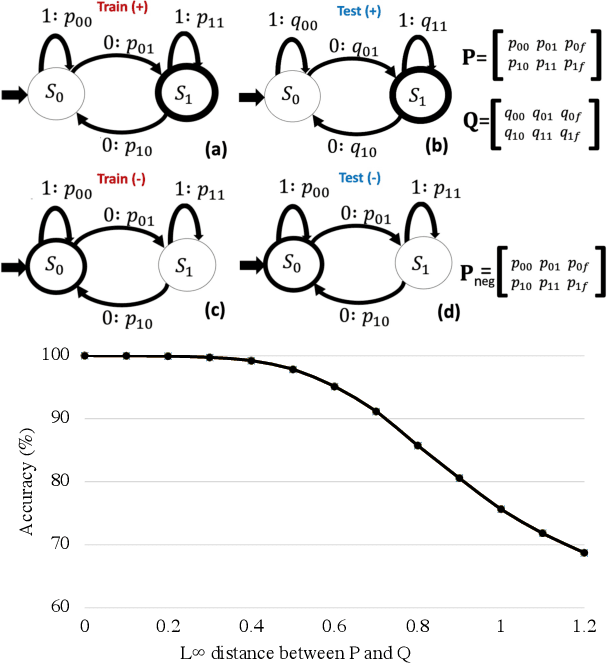
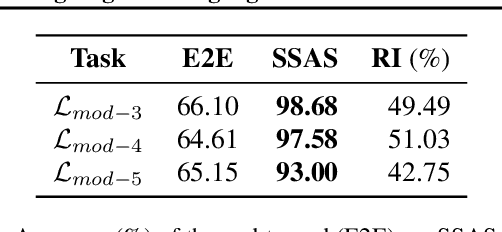
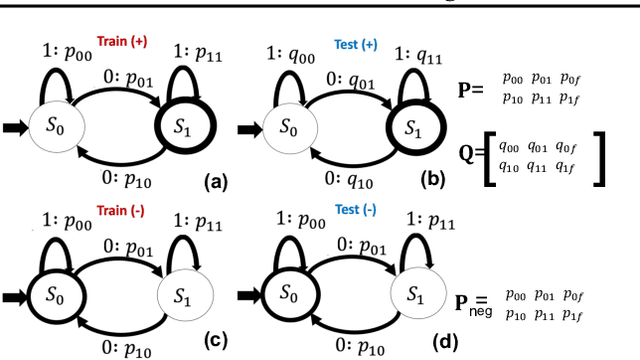
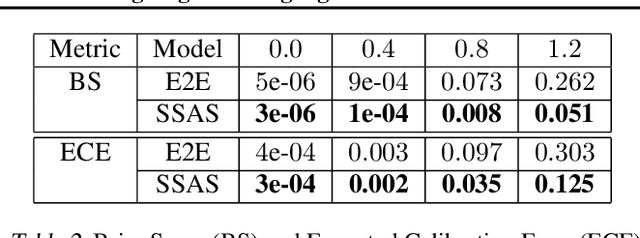
A key feature of human intelligence is the ability to generalize beyond the training distribution, for instance, parsing longer sentences than seen in the past. Currently, deep neural networks struggle to generalize robustly to such shifts in the data distribution. We study robust generalization in the context of using recurrent neural networks (RNNs) to learn regular languages. We hypothesize that standard end-to-end modeling strategies cannot generalize well to systematic distribution shifts and propose a compositional strategy to address this. We compare an end-to-end strategy that maps strings to labels with a compositional strategy that predicts the structure of the deterministic finite-state automaton (DFA) that accepts the regular language. We theoretically prove that the compositional strategy generalizes significantly better than the end-to-end strategy. In our experiments, we implement the compositional strategy via an auxiliary task where the goal is to predict the intermediate states visited by the DFA when parsing a string. Our empirical results support our hypothesis, showing that auxiliary tasks can enable robust generalization. Interestingly, the end-to-end RNN generalizes significantly better than the theoretical lower bound, suggesting that it is able to achieve at least some degree of robust generalization.
SMODICE: Versatile Offline Imitation Learning via State Occupancy Matching
Feb 04, 2022
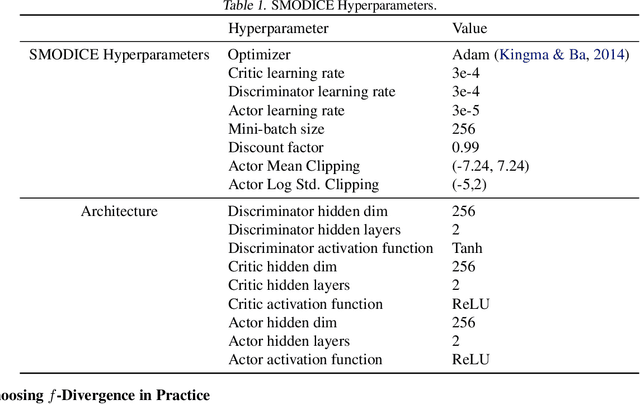

We propose State Matching Offline DIstribution Correction Estimation (SMODICE), a novel and versatile algorithm for offline imitation learning (IL) via state-occupancy matching. We show that the SMODICE objective admits a simple optimization procedure through an application of Fenchel duality and an analytic solution in tabular MDPs. Without requiring access to expert actions, SMODICE can be effectively applied to three offline IL settings: (i) imitation from observations (IfO), (ii) IfO with dynamics or morphologically mismatched expert, and (iii) example-based reinforcement learning, which we show can be formulated as a state-occupancy matching problem. We extensively evaluate SMODICE on both gridworld environments as well as on high-dimensional offline benchmarks. Our results demonstrate that SMODICE is effective for all three problem settings and significantly outperforms prior state-of-art.
Conservative and Adaptive Penalty for Model-Based Safe Reinforcement Learning
Dec 14, 2021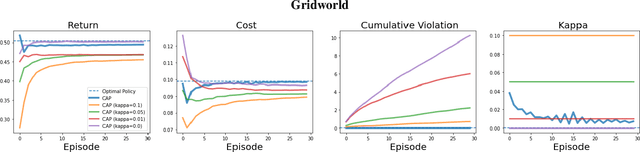
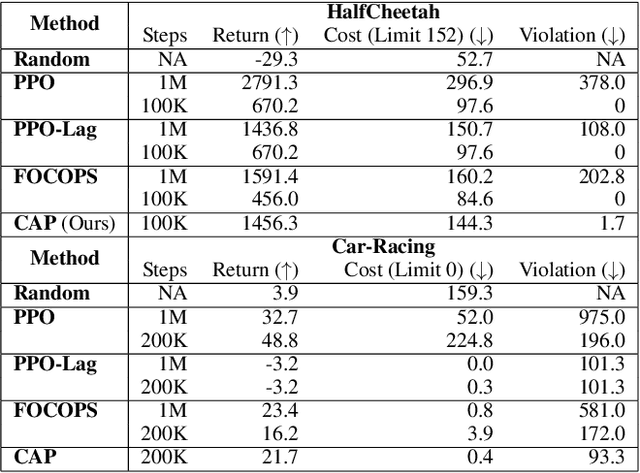
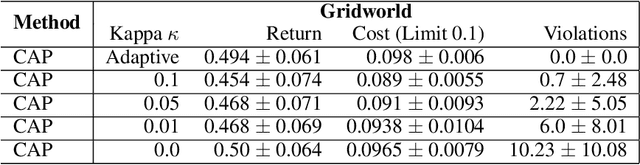
Reinforcement Learning (RL) agents in the real world must satisfy safety constraints in addition to maximizing a reward objective. Model-based RL algorithms hold promise for reducing unsafe real-world actions: they may synthesize policies that obey all constraints using simulated samples from a learned model. However, imperfect models can result in real-world constraint violations even for actions that are predicted to satisfy all constraints. We propose Conservative and Adaptive Penalty (CAP), a model-based safe RL framework that accounts for potential modeling errors by capturing model uncertainty and adaptively exploiting it to balance the reward and the cost objectives. First, CAP inflates predicted costs using an uncertainty-based penalty. Theoretically, we show that policies that satisfy this conservative cost constraint are guaranteed to also be feasible in the true environment. We further show that this guarantees the safety of all intermediate solutions during RL training. Further, CAP adaptively tunes this penalty during training using true cost feedback from the environment. We evaluate this conservative and adaptive penalty-based approach for model-based safe RL extensively on state and image-based environments. Our results demonstrate substantial gains in sample-efficiency while incurring fewer violations than prior safe RL algorithms. Code is available at: https://github.com/Redrew/CAP
Safely Bridging Offline and Online Reinforcement Learning
Oct 25, 2021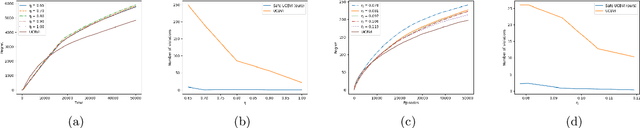
A key challenge to deploying reinforcement learning in practice is exploring safely. We propose a natural safety property -- \textit{uniformly} outperforming a conservative policy (adaptively estimated from all data observed thus far), up to a per-episode exploration budget. We then design an algorithm that uses a UCB reinforcement learning policy for exploration, but overrides it as needed to ensure safety with high probability. We experimentally validate our results on a sepsis treatment task, demonstrating that our algorithm can learn while ensuring good performance compared to the baseline policy for every patient.
Safe Human-Interactive Control via Shielding
Oct 11, 2021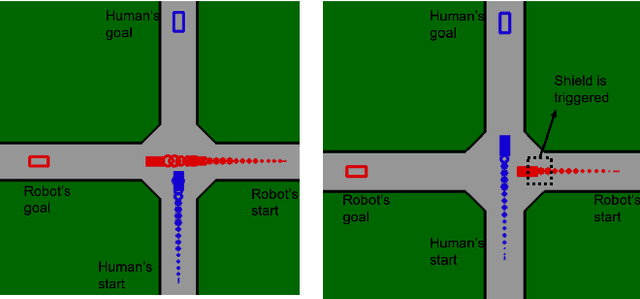
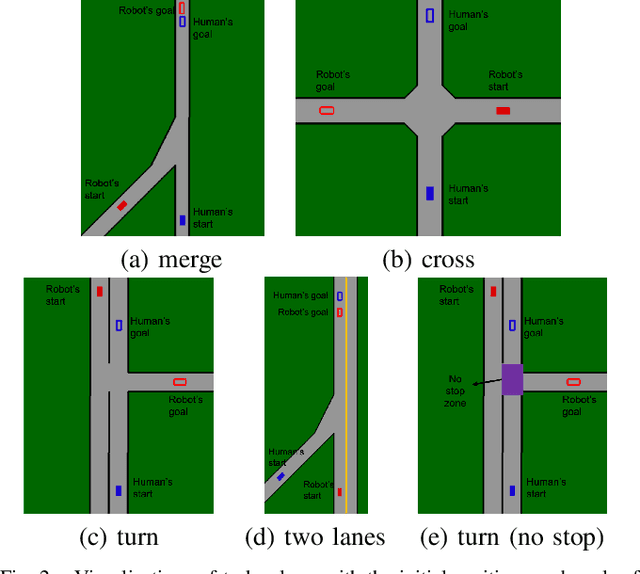
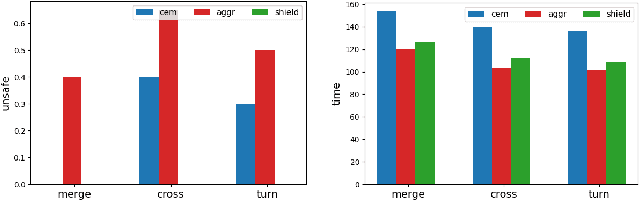
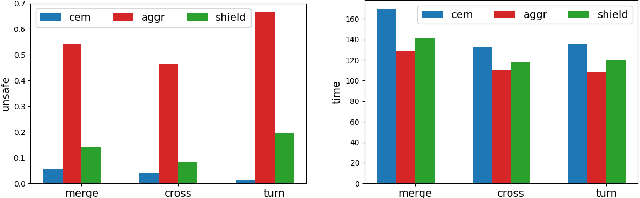
Ensuring safety for human-interactive robotics is important due to the potential for human injury. The key challenge is defining safety in a way that accounts for the complex range of human behaviors without modeling the human as an unconstrained adversary. We propose a novel approach to ensuring safety in these settings. Our approach focuses on defining backup actions that we believe human always considers taking to avoid an accident -- e.g., brake to avoid rear-ending the other agent. Given such a definition, we consider a safety constraint that guarantees safety as long as the human takes the appropriate backup actions when necessary to ensure safety. Then, we propose an algorithm that overrides an arbitrary given controller as needed to ensure that the robot is safe. We evaluate our approach in a simulated environment, interacting with both real and simulated humans.