 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Domain Frame Semantic Parsing Using Transformers
Oct 23, 2020
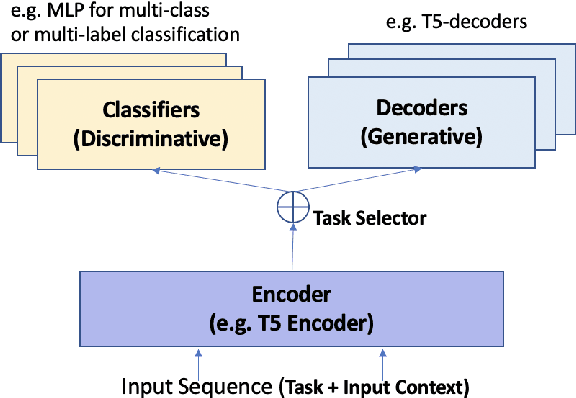
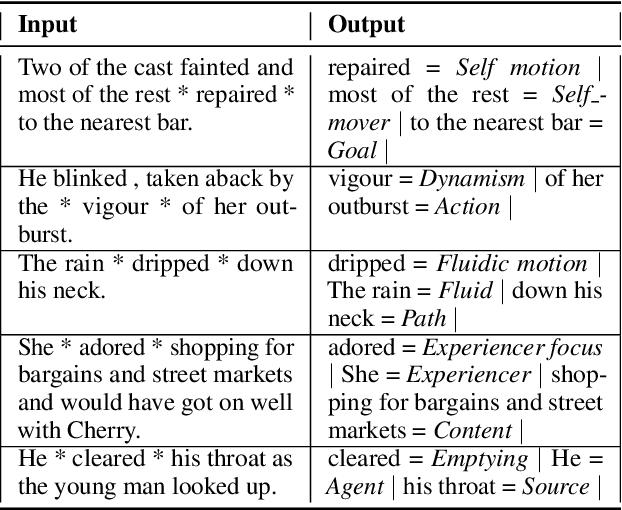
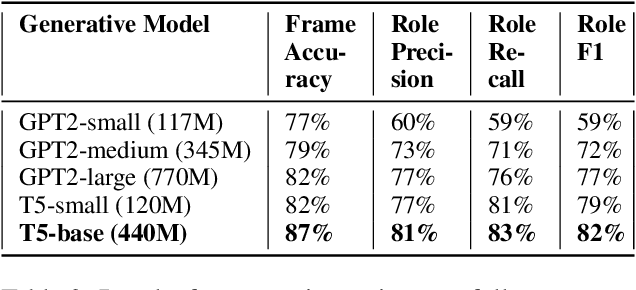
Frame semantic parsing is a complex problem which includes multiple underlying subtasks. Recent approaches have employed joint learning of subtasks (such as predicate and argument detection), and multi-task learning of related tasks (such as syntactic and semantic parsing). In this paper, we explore multi-task learning of all subtasks with transformer-based models. We show that a purely generative encoder-decoder architecture handily beats the previous state of the art in FrameNet 1.7 parsing, and that a mixed decoding multi-task approach achieves even better performance. Finally, we show that the multi-task model also outperforms recent state of the art systems for PropBank SRL parsing on the CoNLL 2012 benchmark.
GLUCOSE: GeneraLized and COntextualized Story Explanations
Sep 16, 2020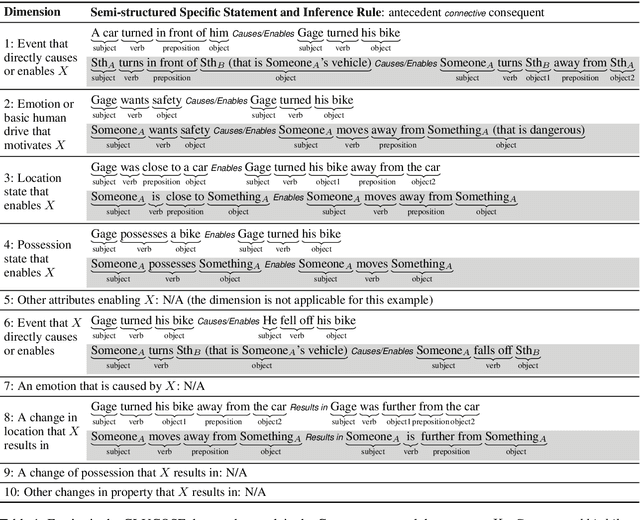



When humans read or listen, they make implicit commonsense inferences that frame their understanding of what happened and why. As a step toward AI systems that can build similar mental models, we introduce GLUCOSE, a large-scale dataset of implicit commonsense causal knowledge, encoded as causal mini-theories about the world, each grounded in a narrative context. To construct GLUCOSE, we drew on cognitive psychology to identify ten dimensions of causal explanation, focusing on events, states, motivations, and emotions. Each GLUCOSE entry includes a story-specific causal statement paired with an inference rule generalized from the statement. This paper details two concrete contributions: First, we present our platform for effectively crowdsourcing GLUCOSE data at scale, which uses semi-structured templates to elicit causal explanations. Using this platform, we collected 440K specific statements and general rules that capture implicit commonsense knowledge about everyday situations. Second, we show that existing knowledge resources and pretrained language models do not include or readily predict GLUCOSE's rich inferential content. However, when state-of-the-art neural models are trained on this knowledge, they can start to make commonsense inferences on unseen stories that match humans' mental models.
Siamese Networks for Semantic Pattern Similarity
Dec 17, 2018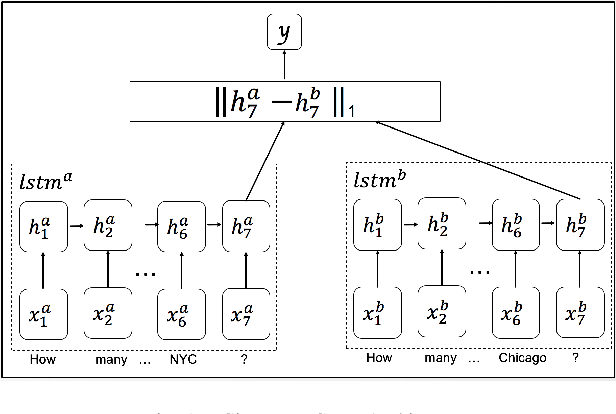
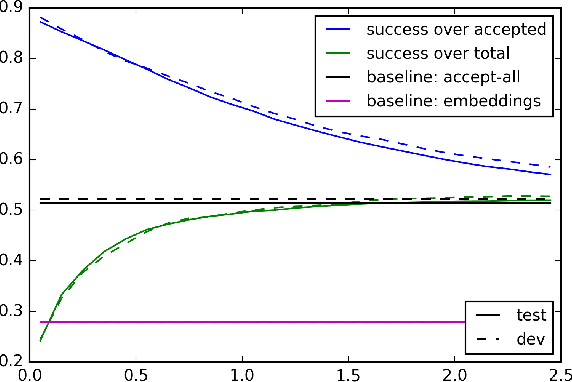
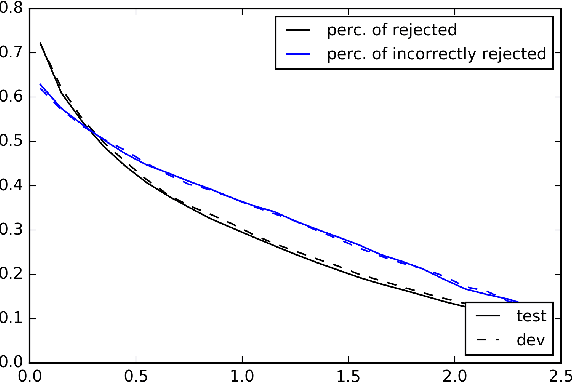

Semantic Pattern Similarity is an interesting, though not often encountered NLP task where two sentences are compared not by their specific meaning, but by their more abstract semantic pattern (e.g., preposition or frame). We utilize Siamese Networks to model this task, and show its usefulness in determining SQL patterns for unseen questions in a database-backed question answering scenario. Our approach achieves high accuracy and contains a built-in proxy for confidence, which can be used to keep precision arbitrarily high.