 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive Deep Learning for Automated Spheno-Occipital Synchondrosis Maturation Assessment
Apr 13, 2026Accurate assessment of spheno-occipital synchondrosis (SOS) maturation is a key indicator of craniofacial growth and a critical determinant for orthodontic and surgical timing. However, SOS staging from cone-beam CT (CBCT) relies on subtle, continuously evolving morphological cues, leading to high inter-observer variability and poor reproducibility, especially at transitional fusion stages. We frame SOS assessment as a fine-grained visual recognition problem and propose a progressive representation-learning framework that explicitly mirrors how expert clinicians reason about synchondral fusion: from coarse anatomical structure to increasingly subtle patterns of closure. Rather than training a full-capacity network end-to-end, we sequentially grow the model by activating deeper blocks over time, allowing early layers to first encode stable cranial base morphology before higher-level layers specialize in discriminating adjacent maturation stages. This yields a curriculum over network depth that aligns deep feature learning with the biological continuum of SOS fusion. Extensive experiments across convolutional and transformer-based architectures show that this expert-inspired training strategy produces more stable optimization and consistently higher accuracy than standard training, particularly for ambiguous intermediate stages. Importantly, these gains are achieved without changing network architectures or loss functions, demonstrating that training dynamics alone can substantially improve anatomical representation learning. The proposed framework establishes a principled link between expert dental intuition and deep visual representations, enabling robust, data-efficient SOS staging from CBCT and offering a general strategy for modeling other continuous biological processes in medical imaging.
Knowledge Distillation Approach for SOS Fusion Staging: Towards Fully Automated Skeletal Maturity Assessment
May 27, 2025



We introduce a novel deep learning framework for the automated staging of spheno-occipital synchondrosis (SOS) fusion, a critical diagnostic marker in both orthodontics and forensic anthropology. Our approach leverages a dual-model architecture wherein a teacher model, trained on manually cropped images, transfers its precise spatial understanding to a student model that operates on full, uncropped images. This knowledge distillation is facilitated by a newly formulated loss function that aligns spatial logits as well as incorporates gradient-based attention spatial mapping, ensuring that the student model internalizes the anatomically relevant features without relying on external cropping or YOLO-based segmentation. By leveraging expert-curated data and feedback at each step, our framework attains robust diagnostic accuracy, culminating in a clinically viable end-to-end pipeline. This streamlined approach obviates the need for additional pre-processing tools and accelerates deployment, thereby enhancing both the efficiency and consistency of skeletal maturation assessment in diverse clinical settings.
Intelligent Incident Hypertension Prediction in Obstructive Sleep Apnea
May 27, 2025



Obstructive sleep apnea (OSA) is a significant risk factor for hypertension, primarily due to intermittent hypoxia and sleep fragmentation. Predicting whether individuals with OSA will develop hypertension within five years remains a complex challenge. This study introduces a novel deep learning approach that integrates Discrete Cosine Transform (DCT)-based transfer learning to enhance prediction accuracy. We are the first to incorporate all polysomnography signals together for hypertension prediction, leveraging their collective information to improve model performance. Features were extracted from these signals and transformed into a 2D representation to utilize pre-trained 2D neural networks such as MobileNet, EfficientNet, and ResNet variants. To further improve feature learning, we introduced a DCT layer, which transforms input features into a frequency-based representation, preserving essential spectral information, decorrelating features, and enhancing robustness to noise. This frequency-domain approach, coupled with transfer learning, is especially beneficial for limited medical datasets, as it leverages rich representations from pre-trained networks to improve generalization. By strategically placing the DCT layer at deeper truncation depths within EfficientNet, our model achieved a best area under the curve (AUC) of 72.88%, demonstrating the effectiveness of frequency-domain feature extraction and transfer learning in predicting hypertension risk in OSA patients over a five-year period.
Gradient Attention Map Based Verification of Deep Convolutional Neural Networks with Application to X-ray Image Datasets
Apr 29, 2025



Deep learning models have great potential in medical imaging, including orthodontics and skeletal maturity assessment. However, applying a model to data different from its training set can lead to unreliable predictions that may impact patient care. To address this, we propose a comprehensive verification framework that evaluates model suitability through multiple complementary strategies. First, we introduce a Gradient Attention Map (GAM)-based approach that analyzes attention patterns using Grad-CAM and compares them via similarity metrics such as IoU, Dice Similarity, SSIM, Cosine Similarity, Pearson Correlation, KL Divergence, and Wasserstein Distance. Second, we extend verification to early convolutional feature maps, capturing structural mis-alignments missed by attention alone. Finally, we incorporate an additional garbage class into the classification model to explicitly reject out-of-distribution inputs. Experimental results demonstrate that these combined methods effectively identify unsuitable models and inputs, promoting safer and more reliable deployment of deep learning in medical imaging.
Intelligent Service Selection in a Multi-dimensional Environment of Cloud Providers for IoT stream Data through cloudlets
Aug 14, 2020

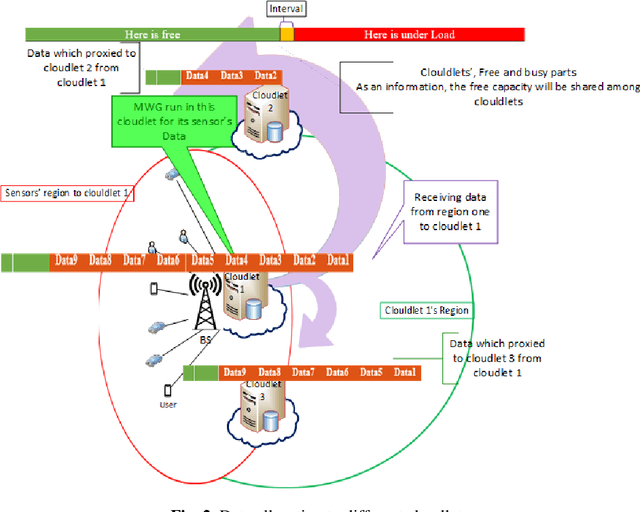

The expansion of the Internet of Things(IoT) services and a huge amount of data generated by different sensors, signify the importance of cloud computing services like Storage as a Service more than ever. IoT traffic imposes such extra constraints on the cloud storage service as sensor data preprocessing capability and load-balancing between data centers and servers in each data center. Also, it should be allegiant to the Quality of Service (QoS). The hybrid MWG algorithm has been proposed in this work, which considers different objectives such as energy, processing time, transmission time, and load balancing in both Fog and Cloud Layer. The MATLAB script is used to simulate and implement our algorithms, and services of different servers, e.g. Amazon, Dropbox, Google Drive, etc. have been considered. The MWG has 7%, 13%, and 25% improvement in comparison with MOWCA, KGA, and NSGAII in metric of spacing, respectively. Moreover, the MWG has 4%, 4.7%, and 7.3% optimization in metric of quality in comparison to MOWCA, KGA, and NSGAII, respectively. The overall optimization shows that the MWG algorithm has 7.8%, 17%, and 21.6% better performance in comparison with MOWCA, KGA, and NSGAII in the obtained best result by considering different objectives, respectively.