 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForce-Aware Neural Tangent Kernels for Scalable and Robust Active Learning of MLIPs
May 13, 2026Active learning for machine-learning interatomic potentials (MLIPs) must address several challenges to be practical: scaling to large candidate pools, leveraging energy-force supervision, and maintaining robustness when candidate pools are biased relative to the target distribution. In this work, we jointly address these challenges. We first introduce a linearly scaling acquisition framework based on chunked feature-space posterior-variance shortlisting. By avoiding materialisation of the candidate and train set kernels, this approach enables screening of ~200k structures within hours and applies broadly to acquisition strategies that score candidates based on molecular similarity metrics. We then extend the Neural Tangent Kernel (NTK) to a force-aware setting via mixed parameter-coordinate derivatives, yielding a force NTK and a joint energy-force NTK that provide natural similarity metrics for vector-field prediction. We demonstrate the effectiveness of the joint energy-force NTK on the OC20 dataset, where force-aware acquisition is crucial: it achieves the lowest energy and force MAE and RMSE across all metrics and distribution splits. Across T1x, PMechDB, and RGD benchmarks, our force NTK methods remain competitive with established baselines while being significantly more efficient than committee-based approaches. Under a controlled candidate-pool shift case study on T1x, acquisition based on pretrained MLIP embeddings and NTKs remains robust, whereas committee-based methods exhibit higher variance. Overall, these results show that a single pretrained MLIP can enable scalable, force-aware, and distribution-robust active learning for foundation-model fine-tuning.
Pretrained Model Representations as Acquisition Signals for Active Learning of MLIPs
May 05, 2026Training machine learning interatomic potentials (MLIPs) for reactive chemistry is often bottlenecked by the high cost of quantum chemical labels and the scarcity of transition state configurations in candidate pools. Active learning (AL) can mitigate these costs, but its effectiveness hinges on the acquisition rule. We investigate whether the latent space of a pretrained MLIP already contains the information necessary for effective acquisition, eliminating the need for auxiliary uncertainty heads, Bayesian training and fine-tuning, or committee ensembles. We introduce two acquisition signals derived directly from a pretrained MACE potential: a finite-width neural tangent kernel (NTK) and an activation kernel built from hidden latent space features. On reactive-chemistry benchmarks, both kernels consistently outperform fixed-descriptor baselines, committee disagreement, and random acquisition, reducing the data required to reach performance targets by an average of 38% for energy error and 28% for force error. We further show that the pretrained model induces similarity spaces that preserve chemically meaningful structure and provide more reliable residual uncertainty estimates than randomly initialised or fixed-descriptor-based kernels. Our results suggest that pretraining aligns latent-space geometry with model error, yielding a practical and sufficient acquisition signal for reactive MLIP fine-tuning.
Local Max-Entropy and Free Energy Principles, Belief Diffusions and their Singularities
Oct 04, 2023



A comprehensive picture of three Bethe-Kikuchi variational principles including their relationship to belief propagation (BP) algorithms on hypergraphs is given. The structure of BP equations is generalized to define continuous-time diffusions, solving localized versions of the max-entropy principle (A), the variational free energy principle (B), and a less usual equilibrium free energy principle (C), Legendre dual to A. Both critical points of Bethe-Kikuchi functionals and stationary beliefs are shown to lie at the non-linear intersection of two constraint surfaces, enforcing energy conservation and marginal consistency respectively. The hypersurface of singular beliefs, accross which equilibria become unstable as the constraint surfaces meet tangentially, is described by polynomial equations in the convex polytope of consistent beliefs. This polynomial is expressed by a loop series expansion for graphs of binary variables.
Equivariant Message Passing Neural Network for Crystal Material Discovery
Feb 01, 2023



Automatic material discovery with desired properties is a fundamental challenge for material sciences. Considerable attention has recently been devoted to generating stable crystal structures. While existing work has shown impressive success on supervised tasks such as property prediction, the progress on unsupervised tasks such as material generation is still hampered by the limited extent to which the equivalent geometric representations of the same crystal are considered. To address this challenge, we propose EMPNN a periodic equivariant message-passing neural network that learns crystal lattice deformation in an unsupervised fashion. Our model equivalently acts on lattice according to the deformation action that must be performed, making it suitable for crystal generation, relaxation and optimisation. We present experimental evaluations that demonstrate the effectiveness of our approach.
Local Max-Entropy and Free Energy Principles Solved by Belief Propagation
Jul 02, 2022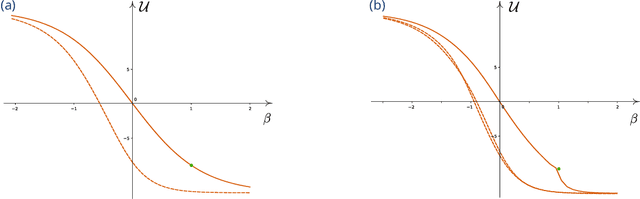
A statistical system is classically defined on a set of microstates $E$ by a global energy function $H : E \to \mathbb{R}$, yielding Gibbs probability measures (softmins) $\rho^\beta(H)$ for every inverse temperature $\beta = T^{-1}$. Gibbs states are simultaneously characterized by free energy principles and the max-entropy principle, with dual constraints on inverse temperature $\beta$ and mean energy ${\cal U}(\beta) = \mathbb{E}_{\rho^\beta}[H]$ respectively. The Legendre transform relates these diverse variational principles which are unfortunately not tractable in high dimension. The global energy is generally given as a sum $H(x) = \sum_{\rm a \subset \Omega} h_{\rm a}(x_{|\rm a})$ of local short-range interactions $h_{\rm a} : E_{\rm a} \to \mathbb{R}$ indexed by bounded subregions ${\rm a} \subset \Omega$, and this local structure can be used to design good approximation schemes on thermodynamic functionals. We show that the generalized belief propagation (GBP) algorithm solves a collection of local variational principles, by converging to critical points of Bethe-Kikuchi approximations of the free energy $F(\beta)$, the Shannon entropy $S(\cal U)$, and the variational free energy ${\cal F}(\beta) = {\cal U} - \beta^{-1} S(\cal U)$, extending an initial correspondence by Yedidia et al. This local form of Legendre duality yields a possible degenerate relationship between mean energy ${\cal U}$ and $\beta$.
Belief Propagation as Diffusion
Jul 26, 2021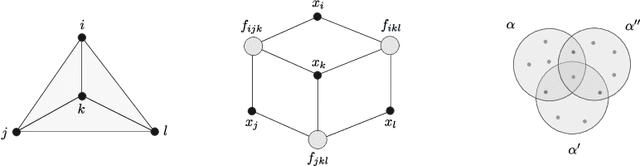
We introduce novel belief propagation algorithms to estimate the marginals of a high dimensional probability distribution. They involve natural (co)homological constructions relevant for a localised description of statistical systems.
* 10 pages, 3 figures, GSI'21 conference
Geomstats: A Python Package for Riemannian Geometry in Machine Learning
Apr 07, 2020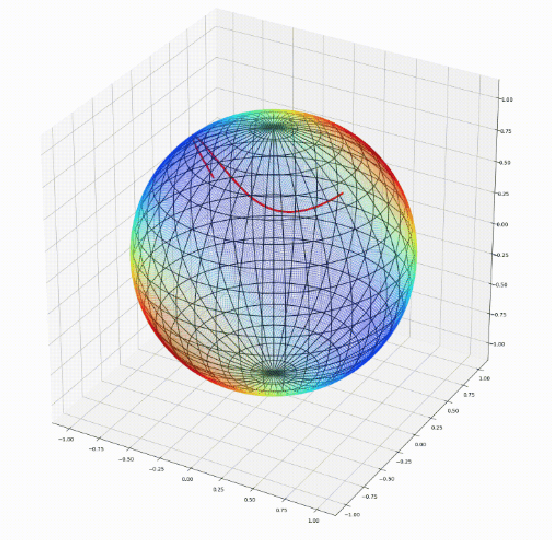
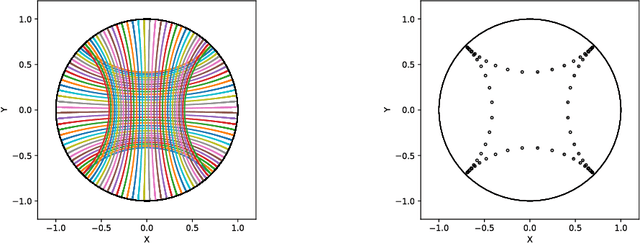

We introduce Geomstats, an open-source Python toolbox for computations and statistics on nonlinear manifolds, such as hyperbolic spaces, spaces of symmetric positive definite matrices, Lie groups of transformations, and many more. We provide object-oriented and extensively unit-tested implementations. Among others, manifolds come equipped with families of Riemannian metrics, with associated exponential and logarithmic maps, geodesics and parallel transport. Statistics and learning algorithms provide methods for estimation, clustering and dimension reduction on manifolds. All associated operations are vectorized for batch computation and provide support for different execution backends, namely NumPy, PyTorch and TensorFlow, enabling GPU acceleration. This paper presents the package, compares it with related libraries and provides relevant code examples. We show that Geomstats provides reliable building blocks to foster research in differential geometry and statistics, and to democratize the use of Riemannian geometry in machine learning applications. The source code is freely available under the MIT license at \url{geomstats.ai}.