 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEXSCLAIM! -- An automated pipeline for the construction of labeled materials imaging datasets from literature
Mar 19, 2021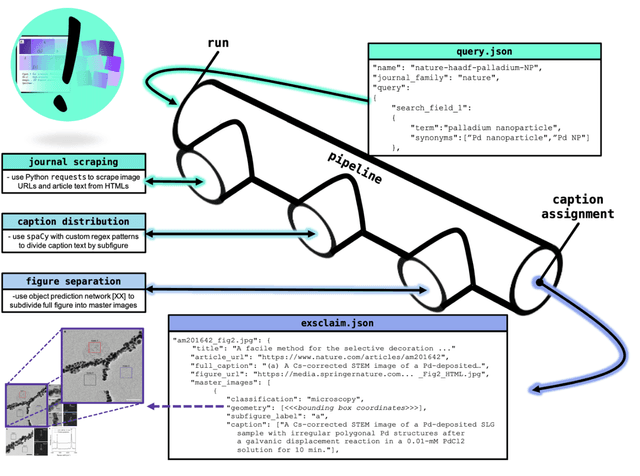
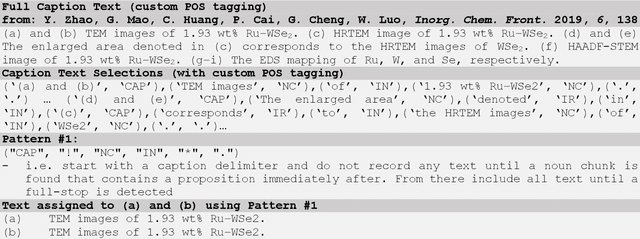
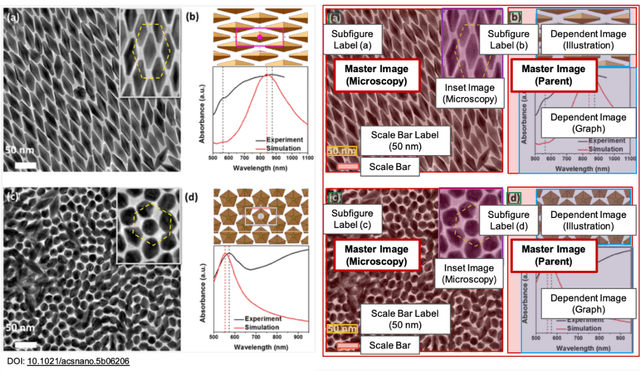
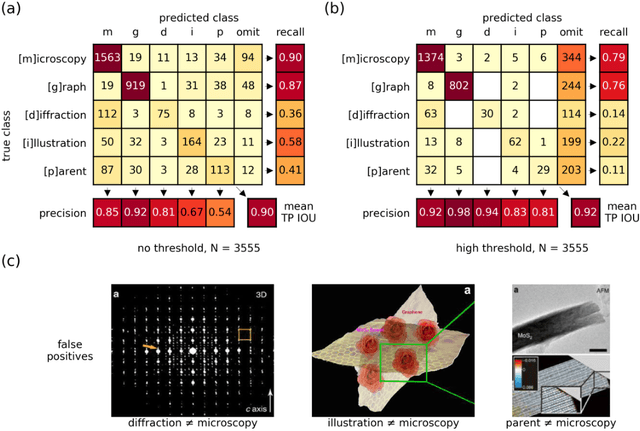
Due to recent improvements in image resolution and acquisition speed, materials microscopy is experiencing an explosion of published imaging data. The standard publication format, while sufficient for traditional data ingestion scenarios where a select number of images can be critically examined and curated manually, is not conducive to large-scale data aggregation or analysis, hindering data sharing and reuse. Most images in publications are presented as components of a larger figure with their explicit context buried in the main body or caption text, so even if aggregated, collections of images with weak or no digitized contextual labels have limited value. To solve the problem of curating labeled microscopy data from literature, this work introduces the EXSCLAIM! Python toolkit for the automatic EXtraction, Separation, and Caption-based natural Language Annotation of IMages from scientific literature. We highlight the methodology behind the construction of EXSCLAIM! and demonstrate its ability to extract and label open-source scientific images at high volume.
An Adaptive Video Acquisition Scheme for Object Tracking and its Performance Optimization
Feb 24, 2021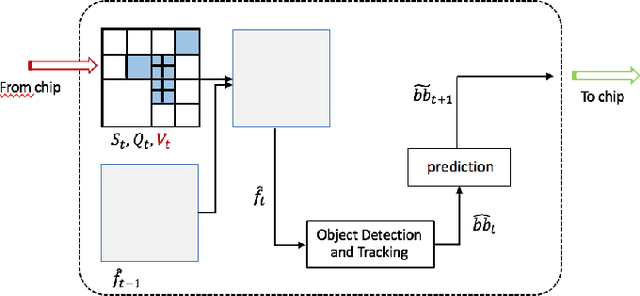
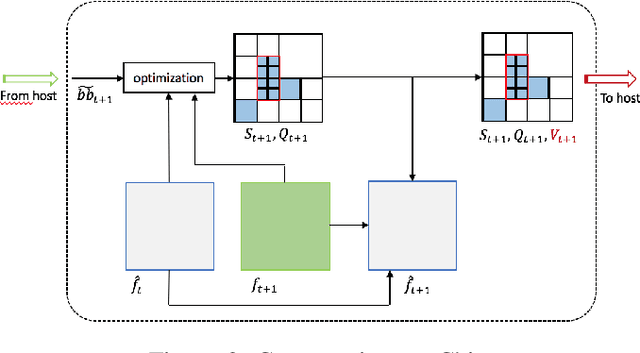


We present a novel adaptive host-chip modular architecture for video acquisition to optimize an overall objective task constrained under a given bit rate. The chip is a high resolution imaging sensor such as gigapixel focal plane array (FPA) with low computational power deployed on the field remotely, while the host is a server with high computational power. The communication channel data bandwidth between the chip and host is constrained to accommodate transfer of all captured data from the chip. The host performs objective task specific computations and also intelligently guides the chip to optimize (compress) the data sent to host. This proposed system is modular and highly versatile in terms of flexibility in re-orienting the objective task. In this work, object tracking is the objective task. While our architecture supports any form of compression/distortion, in this paper we use quadtree (QT)-segmented video frames. We use Viterbi (Dynamic Programming) algorithm to minimize the area normalized weighted rate-distortion allocation of resources. The host receives only these degraded frames for analysis. An object detector is used to detect objects, and a Kalman Filter based tracker is used to track those objects. Evaluation of system performance is done in terms of Multiple Object Tracking Accuracy (MOTA) metric. In this proposed novel architecture, performance gains in MOTA is obtained by twice training the object detector with different system generated distortions as a novel 2-step process. Additionally, object detector is assisted by tracker to upscore the region proposals in the detector to further improve the performance.
SkinScan: Low-Cost 3D-Scanning for Dermatologic Diagnosis and Documentation
Jan 31, 2021
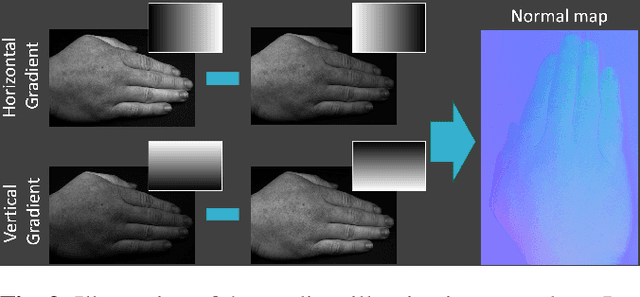
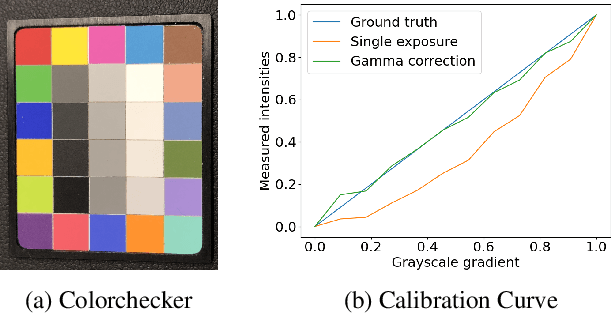

The utilization of computational photography becomes increasingly essential in the medical field. Today, imaging techniques for dermatology range from two-dimensional (2D) color imagery with a mobile device to professional clinical imaging systems measuring additional detailed three-dimensional (3D) data. The latter are commonly expensive and not accessible to a broad audience. In this work, we propose a novel system and software framework that relies only on low-cost (and even mobile) commodity devices present in every household to measure detailed 3D information of the human skin with a 3D-gradient-illumination-based method. We believe that our system has great potential for early-stage diagnosis and monitoring of skin diseases, especially in vastly populated or underdeveloped areas.
A Two-stage Framework for Compound Figure Separation
Jan 25, 2021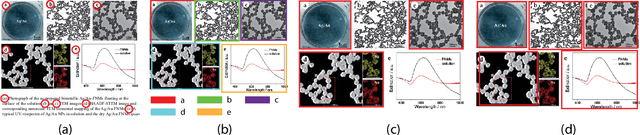
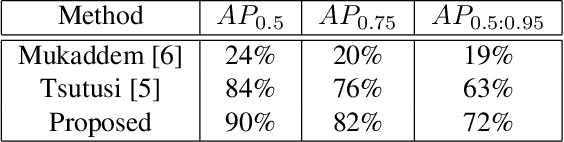
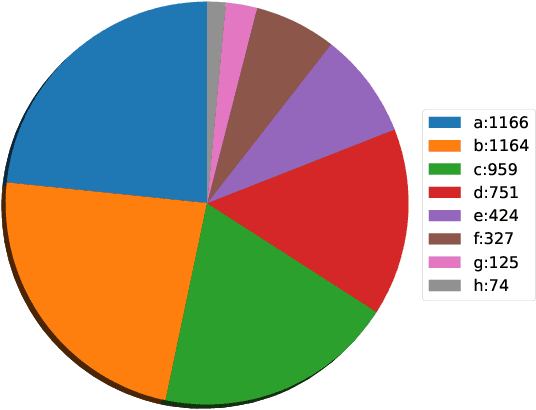
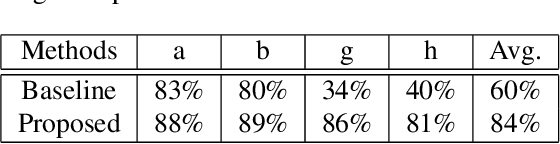
Scientific literature contains large volumes of complex, unstructured figures that are compound in nature (i.e. composed of multiple images, graphs, and drawings). Separation of these compound figures is critical for information retrieval from these figures. In this paper, we propose a new strategy for compound figure separation, which decomposes the compound figures into constituent subfigures while preserving the association between the subfigures and their respective caption components. We propose a two-stage framework to address the proposed compound figure separation problem. In particular, the subfigure label detection module detects all subfigure labels in the first stage. Then, in the subfigure detection module, the detected subfigure labels help to detect the subfigures by optimizing the feature selection process and providing the global layout information as extra features. Extensive experiments are conducted to validate the effectiveness and superiority of the proposed framework, which improves the detection precision by 9%.
E3D: Event-Based 3D Shape Reconstruction
Dec 10, 2020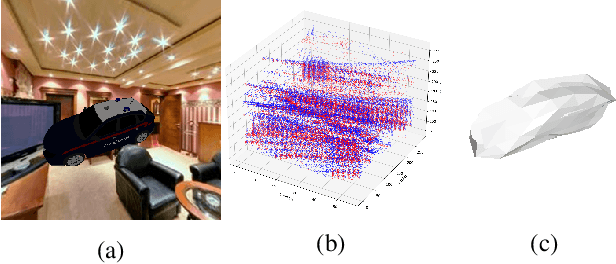
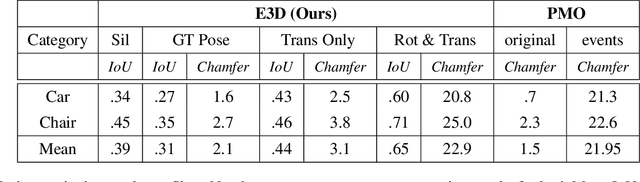

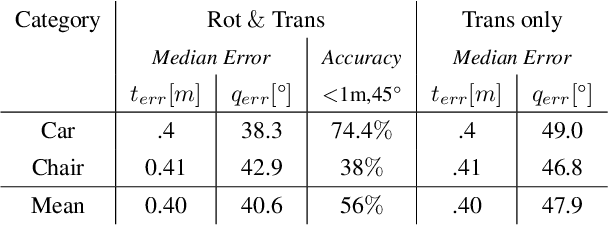
3D shape reconstruction is a primary component of augmented/virtual reality. Despite being highly advanced, existing solutions based on RGB, RGB-D and Lidar sensors are power and data intensive, which introduces challenges for deployment in edge devices. We approach 3D reconstruction with an event camera, a sensor with significantly lower power, latency and data expense while enabling high dynamic range. While previous event-based 3D reconstruction methods are primarily based on stereo vision, we cast the problem as multi-view shape from silhouette using a monocular event camera. The output from a moving event camera is a sparse point set of space-time gradients, largely sketching scene/object edges and contours. We first introduce an event-to-silhouette (E2S) neural network module to transform a stack of event frames to the corresponding silhouettes, with additional neural branches for camera pose regression. Second, we introduce E3D, which employs a 3D differentiable renderer (PyTorch3D) to enforce cross-view 3D mesh consistency and fine-tune the E2S and pose network. Lastly, we introduce a 3D-to-events simulation pipeline and apply it to publicly available object datasets and generate synthetic event/silhouette training pairs for supervised learning.
2-Step Sparse-View CT Reconstruction with a Domain-Specific Perceptual Network
Dec 08, 2020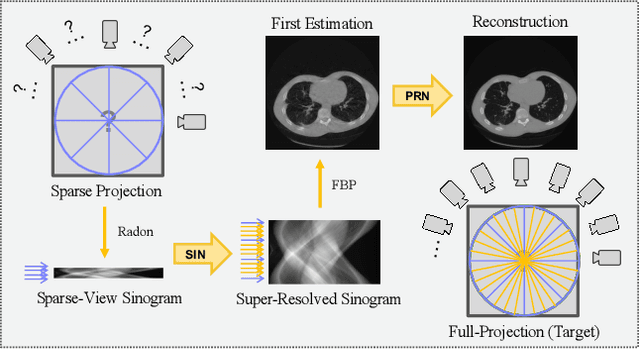
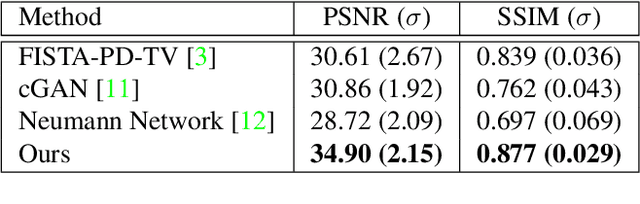
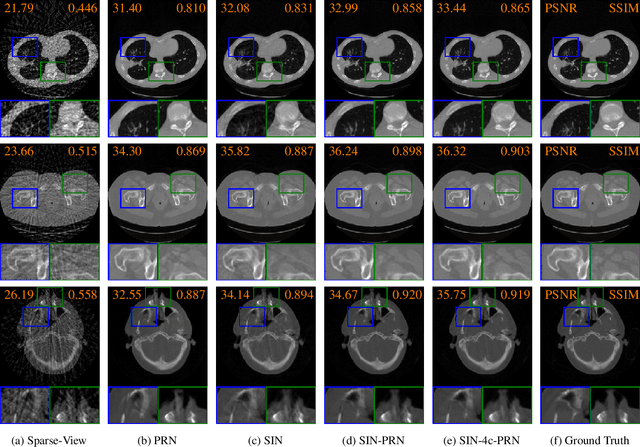
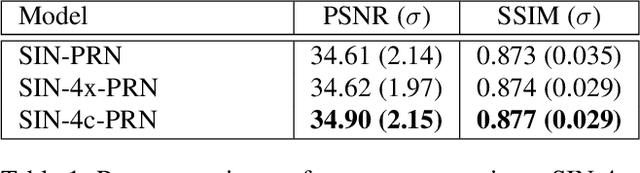
Computed tomography is widely used to examine internal structures in a non-destructive manner. To obtain high-quality reconstructions, one typically has to acquire a densely sampled trajectory to avoid angular undersampling. However, many scenarios require a sparse-view measurement leading to streak-artifacts if unaccounted for. Current methods do not make full use of the domain-specific information, and hence fail to provide reliable reconstructions for highly undersampled data. We present a novel framework for sparse-view tomography by decoupling the reconstruction into two steps: First, we overcome its ill-posedness using a super-resolution network, SIN, trained on the sparse projections. The intermediate result allows for a closed-form tomographic reconstruction with preserved details and highly reduced streak-artifacts. Second, a refinement network, PRN, trained on the reconstructions reduces any remaining artifacts. We further propose a light-weight variant of the perceptual-loss that enhances domain-specific information, boosting restoration accuracy. Our experiments demonstrate an improvement over current solutions by 4 dB.
Disassemblable Fieldwork CT Scanner Using a 3D-printed Calibration Phantom
Nov 12, 2020


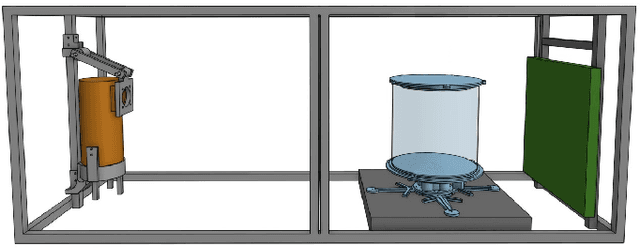
The use of computed tomography (CT) imaging has become of increasing interest to academic areas outside of the field of medical imaging and industrial inspection, e.g., to biology and cultural heritage research. The pecularities of these fields, however, sometimes require that objects need to be imaged on-site, e.g., in field-work conditions or in museum collections. Under these circumstances, it is often not possible to use a commercial device and a custom solution is the only viable option. In order to achieve high image quality under adverse conditions, reliable calibration and trajectory reproduction are usually key requirements for any custom CT scanning system. Here, we introduce the construction of a low-cost disassemblable CT scanner that allows calibration even when trajectory reproduction is not possible due to the limitations imposed by the project conditions. Using 3D-printed in-image calibration phantoms, we compute a projection matrix directly from each captured X-ray projection. We describe our method in detail and show successful tomographic reconstructions of several specimen as proof of concept.
* This paper was originally published at the 6th International Conference on Image Formation in X-Ray Computed Tomography (CTmeeting 2020)
Quadtree Driven Lossy Event Compression
May 03, 2020

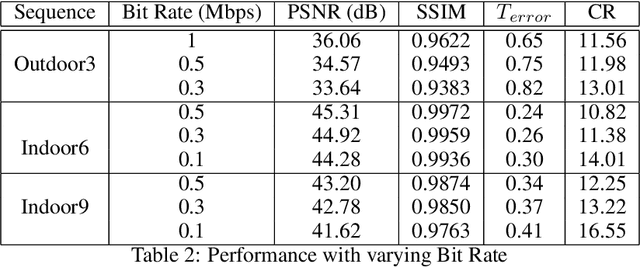
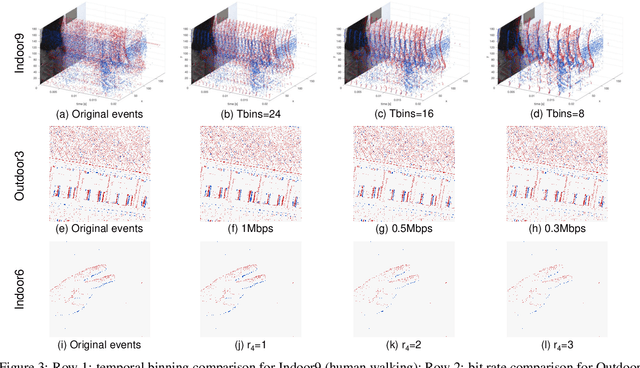
Event cameras are emerging bio-inspired sensors that offer salient benefits over traditional cameras. With high speed, high dynamic range, and low power consumption, event cameras have been increasingly employed to solve existing as well as novel visual and robotics tasks. Despite rapid advancement in event-based vision, event data compression is facing growing demand, yet remains elusively challenging and not effectively addressed. The major challenge is the unique data form, \emph{i.e.}, a stream of four-attribute events, encoding the spatial locations and the timestamp of each event, with a polarity representing the brightness increase/decrease. While events encode temporal variations at high speed, they omit rich spatial information, which is critical for image/video compression. In this paper, we perform lossy event compression (LEC) based on a quadtree (QT) segmentation map derived from an adjacent image. The QT structure provides a priority map for the 3D space-time volume, albeit in a 2D manner. LEC is performed by first quantizing the events over time, and then variably compressing the events within each QT block via Poisson Disk Sampling in 2D space for each quantized time. Our QT-LEC has flexibility in accordance with the bit-rate requirement. Experimentally, we show results with state-of-the-art coding performance. We further evaluate the performance in event-based applications such as image reconstruction and corner detection.
Semantic Segmentation for Compound figures
Dec 16, 2019

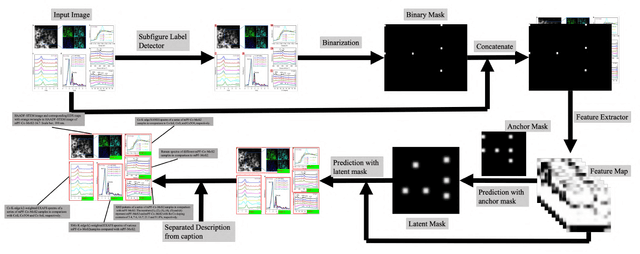

Scientific literature contains large volumes of unstructured data,with over 30\% of figures constructed as a combination of multiple images, these compound figures cannot be analyzed directly with existing information retrieval tools. In this paper, we propose a semantic segmentation approach for compound figure separation, decomposing the compound figures into "master images". Each master image is one part of a compound figure governed by a subfigure label (typically "(a), (b), (c), etc"). In this way, the separated subfigures can be easily associated with the description information in the caption. In particular, we propose an anchor-based master image detection algorithm, which leverages the correlation between master images and subfigure labels and locates the master images in a two-step manner. First, a subfigure label detector is built to extract the global layout information of the compound figure. Second, the layout information is combined with local features to locate the master images. We validate the effectiveness of proposed method on our labeled testing dataset both quantitatively and qualitatively.
Uncalibrated Deflectometry with a Mobile Device on Extended Specular Surfaces
Jul 24, 2019
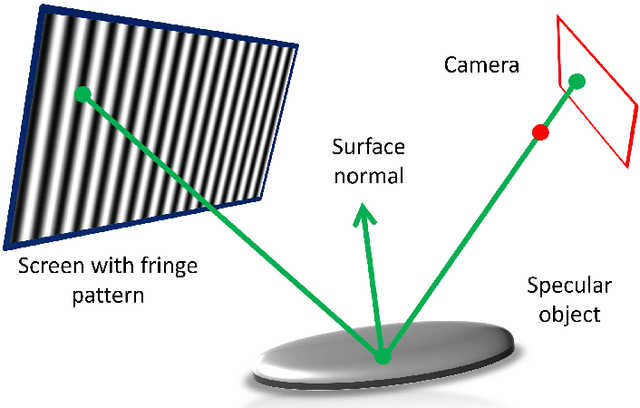


We introduce a system and methods for the three-dimensional measurement of extended specular surfaces with high surface normal variations. Our system consists only of a mobile hand held device and exploits screen and front camera for Deflectometry-based surface measurements. We demonstrate high quality measurements without the need for an offline calibration procedure. In addition, we develop a multi-view technique to compensate for the small screen of a mobile device so that large surfaces can be densely reconstructed in their entirety. This work is a first step towards developing a self-calibrating Deflectometry procedure capable of taking 3D surface measurements of specular objects in the wild and accessible to users with little to no technical imaging experience.