 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoalesced Multi-Output Tsetlin Machines with Clause Sharing
Aug 17, 2021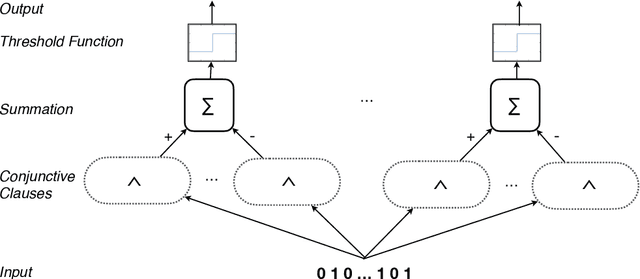

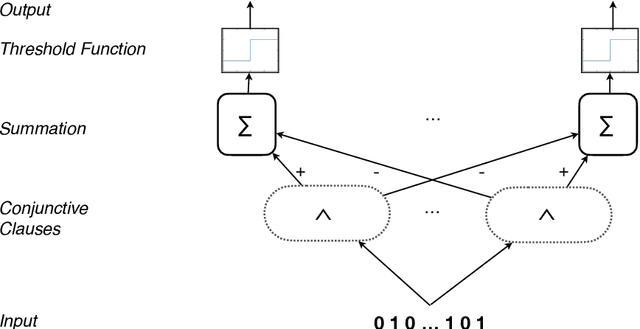
Using finite-state machines to learn patterns, Tsetlin machines (TMs) have obtained competitive accuracy and learning speed across several benchmarks, with frugal memory- and energy footprint. A TM represents patterns as conjunctive clauses in propositional logic (AND-rules), each clause voting for or against a particular output. While efficient for single-output problems, one needs a separate TM per output for multi-output problems. Employing multiple TMs hinders pattern reuse because each TM then operates in a silo. In this paper, we introduce clause sharing, merging multiple TMs into a single one. Each clause is related to each output by using a weight. A positive weight makes the clause vote for output $1$, while a negative weight makes the clause vote for output $0$. The clauses thus coalesce to produce multiple outputs. The resulting coalesced Tsetlin Machine (CoTM) simultaneously learns both the weights and the composition of each clause by employing interacting Stochastic Searching on the Line (SSL) and Tsetlin Automata (TA) teams. Our empirical results on MNIST, Fashion-MNIST, and Kuzushiji-MNIST show that CoTM obtains significantly higher accuracy than TM on $50$- to $1$K-clause configurations, indicating an ability to repurpose clauses. E.g., accuracy goes from $71.99$% to $89.66$% on Fashion-MNIST when employing $50$ clauses per class (22 Kb memory). While TM and CoTM accuracy is similar when using more than $1$K clauses per class, CoTM reaches peak accuracy $3\times$ faster on MNIST with $8$K clauses. We further investigate robustness towards imbalanced training data. Our evaluations on imbalanced versions of IMDb- and CIFAR10 data show that CoTM is robust towards high degrees of class imbalance. Being able to share clauses, we believe CoTM will enable new TM application domains that involve multiple outputs, such as learning language models and auto-encoding.
Human Interpretable AI: Enhancing Tsetlin Machine Stochasticity with Drop Clause
May 30, 2021


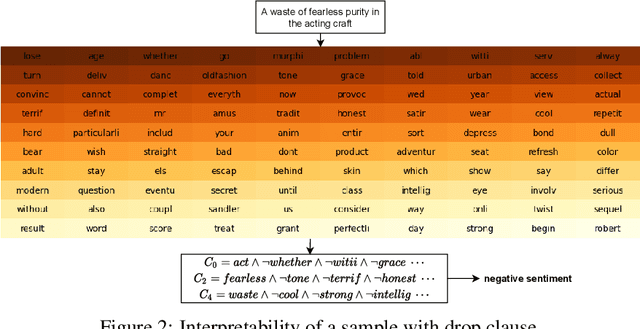
In this article, we introduce a novel variant of the Tsetlin machine (TM) that randomly drops clauses, the key learning elements of a TM. In effect, TM with drop clause ignores a random selection of the clauses in each epoch, selected according to a predefined probability. In this way, additional stochasticity is introduced in the learning phase of TM. Along with producing more distinct and well-structured patterns that improve the performance, we also show that dropping clauses increases learning robustness. To explore the effects clause dropping has on accuracy, training time, and interpretability, we conduct extensive experiments on various benchmark datasets in natural language processing (NLP) (IMDb and SST2) as well as computer vision (MNIST and CIFAR10). In brief, we observe from +2% to +4% increase in accuracy and 2x to 4x faster learning. We further employ the Convolutional TM to document interpretable results on the CIFAR10 dataset. To the best of our knowledge, this is the first time an interpretable machine learning algorithm has been used to produce pixel-level human-interpretable results on CIFAR10. Also, unlike previous interpretable methods that focus on attention visualisation or gradient interpretability, we show that the TM is a more general interpretable method. That is, by producing rule-based propositional logic expressions that are \emph{human}-interpretable, the TM can explain how it classifies a particular instance at the pixel level for computer vision and at the word level for NLP.
Explainable Tsetlin Machine framework for fake news detection with credibility score assessment
May 19, 2021The proliferation of fake news, i.e., news intentionally spread for misinformation, poses a threat to individuals and society. Despite various fact-checking websites such as PolitiFact, robust detection techniques are required to deal with the increase in fake news. Several deep learning models show promising results for fake news classification, however, their black-box nature makes it difficult to explain their classification decisions and quality-assure the models. We here address this problem by proposing a novel interpretable fake news detection framework based on the recently introduced Tsetlin Machine (TM). In brief, we utilize the conjunctive clauses of the TM to capture lexical and semantic properties of both true and fake news text. Further, we use the clause ensembles to calculate the credibility of fake news. For evaluation, we conduct experiments on two publicly available datasets, PolitiFact and GossipCop, and demonstrate that the TM framework significantly outperforms previously published baselines by at least $5\%$ in terms of accuracy, with the added benefit of an interpretable logic-based representation. Further, our approach provides higher F1-score than BERT and XLNet, however, we obtain slightly lower accuracy. We finally present a case study on our model's explainability, demonstrating how it decomposes into meaningful words and their negations.
Word-level Human Interpretable Scoring Mechanism for Novel Text Detection Using Tsetlin Machines
May 10, 2021Recent research in novelty detection focuses mainly on document-level classification, employing deep neural networks (DNN). However, the black-box nature of DNNs makes it difficult to extract an exact explanation of why a document is considered novel. In addition, dealing with novelty at the word-level is crucial to provide a more fine-grained analysis than what is available at the document level. In this work, we propose a Tsetlin machine (TM)-based architecture for scoring individual words according to their contribution to novelty. Our approach encodes a description of the novel documents using the linguistic patterns captured by TM clauses. We then adopt this description to measure how much a word contributes to making documents novel. Our experimental results demonstrate how our approach breaks down novelty into interpretable phrases, successfully measuring novelty.
Distributed Word Representation in Tsetlin Machine
Apr 14, 2021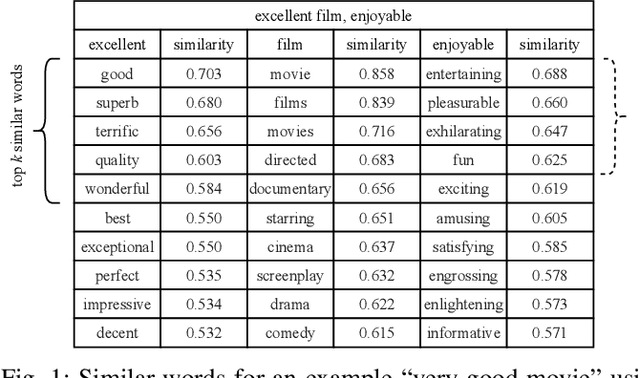
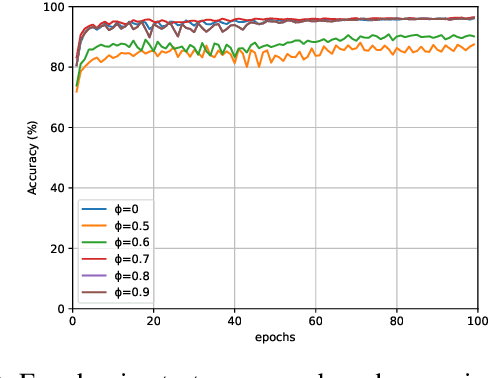
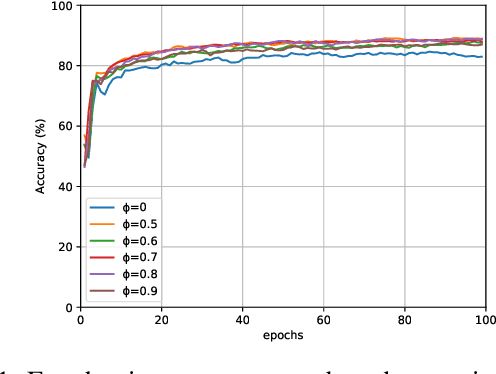
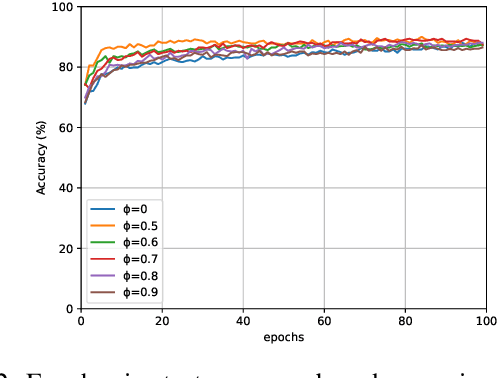
Tsetlin Machine (TM) is an interpretable pattern recognition algorithm based on propositional logic. The algorithm has demonstrated competitive performance in many Natural Language Processing (NLP) tasks, including sentiment analysis, text classification, and Word Sense Disambiguation (WSD). To obtain human-level interpretability, legacy TM employs Boolean input features such as bag-of-words (BOW). However, the BOW representation makes it difficult to use any pre-trained information, for instance, word2vec and GloVe word representations. This restriction has constrained the performance of TM compared to deep neural networks (DNNs) in NLP. To reduce the performance gap, in this paper, we propose a novel way of using pre-trained word representations for TM. The approach significantly enhances the TM performance and maintains interpretability at the same time. We achieve this by extracting semantically related words from pre-trained word representations as input features to the TM. Our experiments show that the accuracy of the proposed approach is significantly higher than the previous BOW-based TM, reaching the level of DNN-based models.
A Relational Tsetlin Machine with Applications to Natural Language Understanding
Feb 22, 2021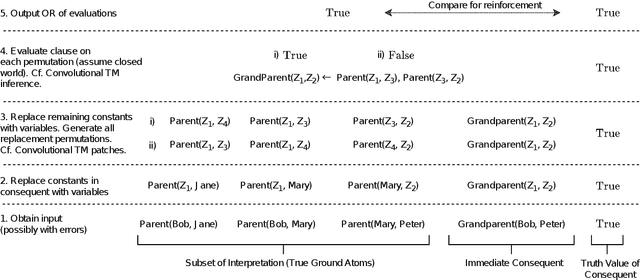


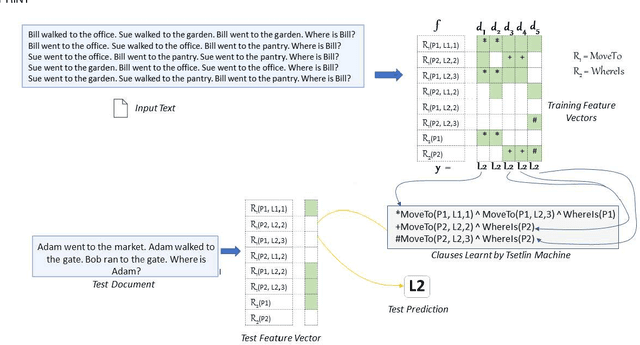
TMs are a pattern recognition approach that uses finite state machines for learning and propositional logic to represent patterns. In addition to being natively interpretable, they have provided competitive accuracy for various tasks. In this paper, we increase the computing power of TMs by proposing a first-order logic-based framework with Herbrand semantics. The resulting TM is relational and can take advantage of logical structures appearing in natural language, to learn rules that represent how actions and consequences are related in the real world. The outcome is a logic program of Horn clauses, bringing in a structured view of unstructured data. In closed-domain question-answering, the first-order representation produces 10x more compact KBs, along with an increase in answering accuracy from 94.83% to 99.48%. The approach is further robust towards erroneous, missing, and superfluous information, distilling the aspects of a text that are important for real-world understanding.
Low-Power Audio Keyword Spotting using Tsetlin Machines
Jan 27, 2021The emergence of Artificial Intelligence (AI) driven Keyword Spotting (KWS) technologies has revolutionized human to machine interaction. Yet, the challenge of end-to-end energy efficiency, memory footprint and system complexity of current Neural Network (NN) powered AI-KWS pipelines has remained ever present. This paper evaluates KWS utilizing a learning automata powered machine learning algorithm called the Tsetlin Machine (TM). Through significant reduction in parameter requirements and choosing logic over arithmetic based processing, the TM offers new opportunities for low-power KWS while maintaining high learning efficacy. In this paper we explore a TM based keyword spotting (KWS) pipeline to demonstrate low complexity with faster rate of convergence compared to NNs. Further, we investigate the scalability with increasing keywords and explore the potential for enabling low-power on-chip KWS.
* 20 pp
On the Convergence of Tsetlin Machines for the XOR Operator
Jan 07, 2021
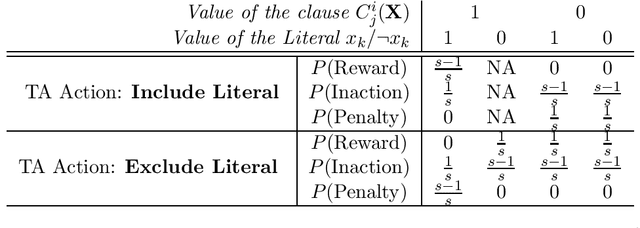
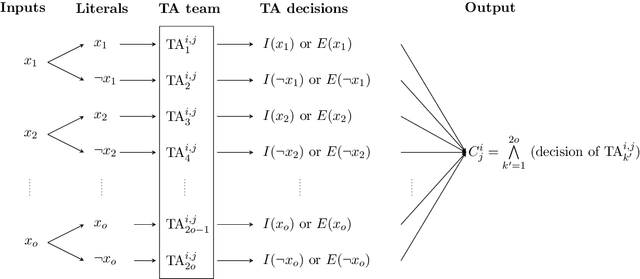

The Tsetlin Machine (TM) is a novel machine learning algorithm with several distinct properties, including transparent inference and learning using hardware-near building blocks. Although numerous papers explore the TM empirically, many of its properties have not yet been analyzed mathematically. In this article, we analyze the convergence of the TM when input is non-linearly related to output by the XOR-operator. Our analysis reveals that the TM, with just two conjunctive clauses, can converge almost surely to reproducing XOR, learning from training data over an infinite time horizon. Furthermore, the analysis shows how the hyper-parameter T guides clause construction so that the clauses capture the distinct sub-patterns in the data. Our analysis of convergence for XOR thus lays the foundation for analyzing other more complex logical expressions. These analyses altogether, from a mathematical perspective, provide new insights on why TMs have obtained state-of-the-art performance on several pattern recognition problems
Measuring the Novelty of Natural Language Text Using the Conjunctive Clauses of a Tsetlin Machine Text Classifier
Nov 17, 2020Most supervised text classification approaches assume a closed world, counting on all classes being present in the data at training time. This assumption can lead to unpredictable behaviour during operation, whenever novel, previously unseen, classes appear. Although deep learning-based methods have recently been used for novelty detection, they are challenging to interpret due to their black-box nature. This paper addresses \emph{interpretable} open-world text classification, where the trained classifier must deal with novel classes during operation. To this end, we extend the recently introduced Tsetlin machine (TM) with a novelty scoring mechanism. The mechanism uses the conjunctive clauses of the TM to measure to what degree a text matches the classes covered by the training data. We demonstrate that the clauses provide a succinct interpretable description of known topics, and that our scoring mechanism makes it possible to discern novel topics from the known ones. Empirically, our TM-based approach outperforms seven other novelty detection schemes on three out of five datasets, and performs second and third best on the remaining, with the added benefit of an interpretable propositional logic-based representation.
Massively Parallel and Asynchronous Tsetlin Machine Architecture Supporting Almost Constant-Time Scaling
Sep 13, 2020
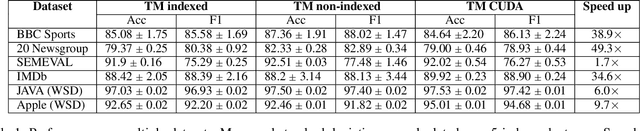
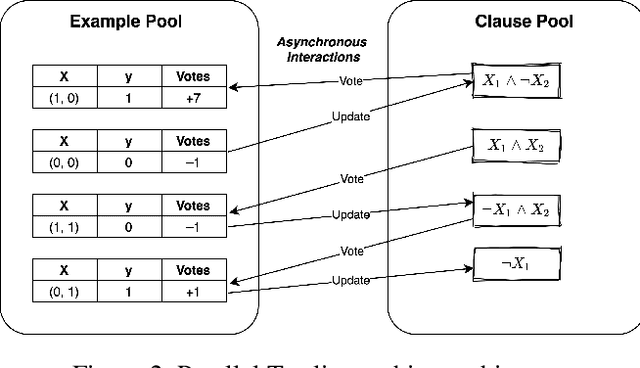
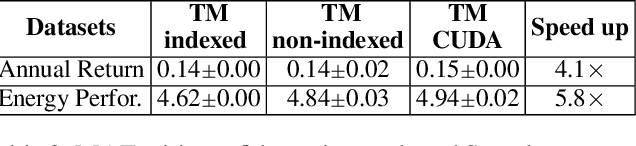
Using logical clauses to represent patterns, Tsetlin machines (TMs) have recently obtained competitive performance in terms of accuracy, memory footprint, energy, and learning speed on several benchmarks. A team of Tsetlin automata (TAs) composes each clause, thus driving the entire learning process. These are rewarded/penalized according to three local rules that optimize global behaviour. Each clause votes for or against a particular class, with classification resolved using a majority vote. In the parallel and asynchronous architecture that we propose here, every clause runs in its own thread for massive parallelism. For each training example, we keep track of the class votes obtained from the clauses in local voting tallies. The local voting tallies allow us to detach the processing of each clause from the rest of the clauses, supporting decentralized learning. Thus, rather than processing training examples one-by-one as in the original TM, the clauses access the training examples simultaneously, updating themselves and the local voting tallies in parallel. There is no synchronization among the clause threads, apart from atomic adds to the local voting tallies. Operating asynchronously, each team of TA will most of the time operate on partially calculated or outdated voting tallies. However, across diverse learning tasks, it turns out that our decentralized TM learning algorithm copes well with working on outdated data, resulting in no significant loss in learning accuracy. Further, we show that the approach provides up to 50 times faster learning. Finally, learning time is almost constant for reasonable clause amounts. For sufficiently large clause numbers, computation time increases approximately proportionally. Our parallel and asynchronous architecture thus allows processing of more massive datasets and operating with more clauses for higher accuracy.