 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Probabilistic Tsetlin Machine: A Novel Approach to Uncertainty Quantification
Oct 23, 2024



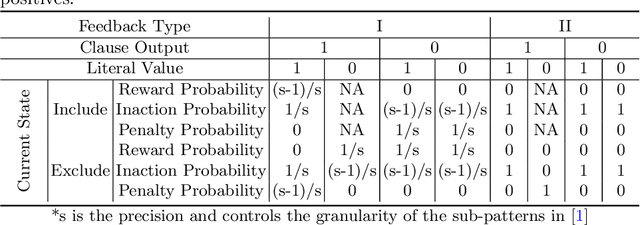
Tsetlin Machines (TMs) have emerged as a compelling alternative to conventional deep learning methods, offering notable advantages such as smaller memory footprint, faster inference, fault-tolerant properties, and interpretability. Although various adaptations of TMs have expanded their applicability across diverse domains, a fundamental gap remains in understanding how TMs quantify uncertainty in their predictions. In response, this paper introduces the Probabilistic Tsetlin Machine (PTM) framework, aimed at providing a robust, reliable, and interpretable approach for uncertainty quantification. Unlike the original TM, the PTM learns the probability of staying on each state of each Tsetlin Automaton (TA) across all clauses. These probabilities are updated using the feedback tables that are part of the TM framework: Type I and Type II feedback. During inference, TAs decide their actions by sampling states based on learned probability distributions, akin to Bayesian neural networks when generating weight values. In our experimental analysis, we first illustrate the spread of the probabilities across TA states for the noisy-XOR dataset. Then we evaluate the PTM alongside benchmark models using both simulated and real-world datasets. The experiments on the simulated dataset reveal the PTM's effectiveness in uncertainty quantification, particularly in delineating decision boundaries and identifying regions of high uncertainty. Moreover, when applied to multiclass classification tasks using the Iris dataset, the PTM demonstrates competitive performance in terms of predictive entropy and expected calibration error, showcasing its potential as a reliable tool for uncertainty estimation. Our findings underscore the importance of selecting appropriate models for accurate uncertainty quantification in predictive tasks, with the PTM offering a particularly interpretable and effective solution.
Building Concise Logical Patterns by Constraining Tsetlin Machine Clause Size
Jan 19, 2023Tsetlin machine (TM) is a logic-based machine learning approach with the crucial advantages of being transparent and hardware-friendly. While TMs match or surpass deep learning accuracy for an increasing number of applications, large clause pools tend to produce clauses with many literals (long clauses). As such, they become less interpretable. Further, longer clauses increase the switching activity of the clause logic in hardware, consuming more power. This paper introduces a novel variant of TM learning - Clause Size Constrained TMs (CSC-TMs) - where one can set a soft constraint on the clause size. As soon as a clause includes more literals than the constraint allows, it starts expelling literals. Accordingly, oversized clauses only appear transiently. To evaluate CSC-TM, we conduct classification, clustering, and regression experiments on tabular data, natural language text, images, and board games. Our results show that CSC-TM maintains accuracy with up to 80 times fewer literals. Indeed, the accuracy increases with shorter clauses for TREC, IMDb, and BBC Sports. After the accuracy peaks, it drops gracefully as the clause size approaches a single literal. We finally analyze CSC-TM power consumption and derive new convergence properties.
On the Convergence of Tsetlin Machines for the XOR Operator
Jan 07, 2021
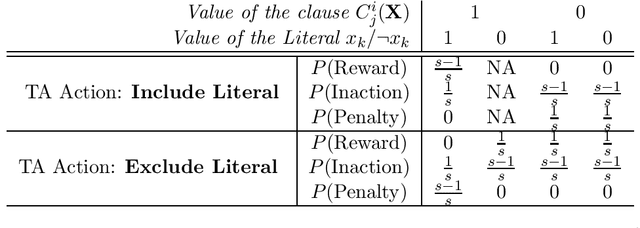

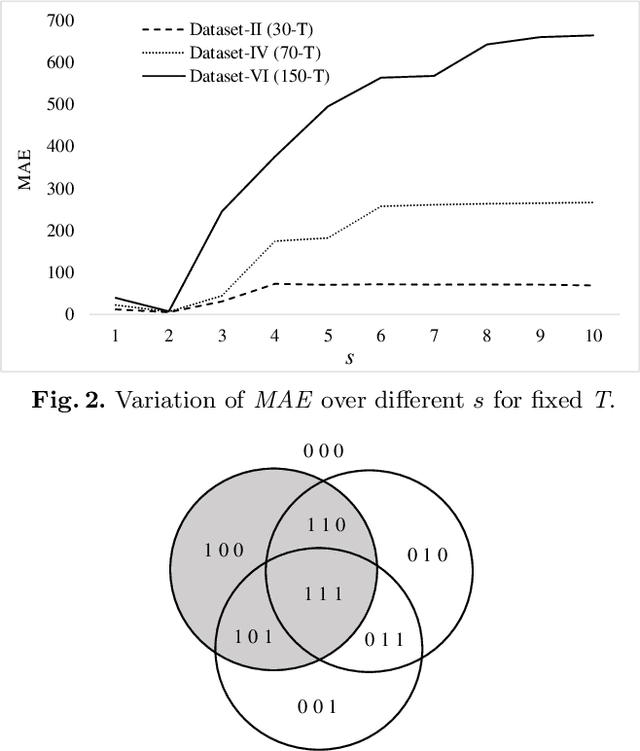
The Tsetlin Machine (TM) is a novel machine learning algorithm with several distinct properties, including transparent inference and learning using hardware-near building blocks. Although numerous papers explore the TM empirically, many of its properties have not yet been analyzed mathematically. In this article, we analyze the convergence of the TM when input is non-linearly related to output by the XOR-operator. Our analysis reveals that the TM, with just two conjunctive clauses, can converge almost surely to reproducing XOR, learning from training data over an infinite time horizon. Furthermore, the analysis shows how the hyper-parameter T guides clause construction so that the clauses capture the distinct sub-patterns in the data. Our analysis of convergence for XOR thus lays the foundation for analyzing other more complex logical expressions. These analyses altogether, from a mathematical perspective, provide new insights on why TMs have obtained state-of-the-art performance on several pattern recognition problems
Massively Parallel and Asynchronous Tsetlin Machine Architecture Supporting Almost Constant-Time Scaling
Sep 13, 2020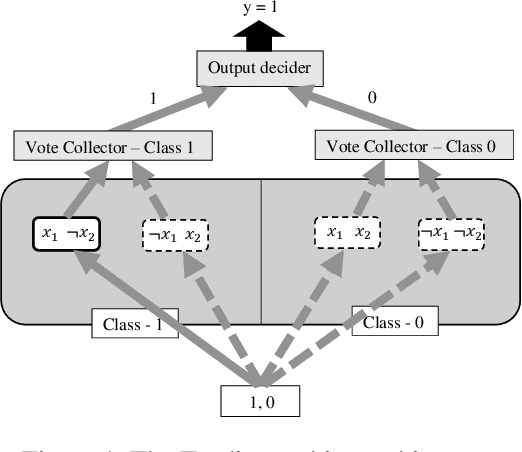
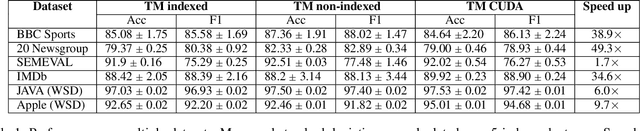
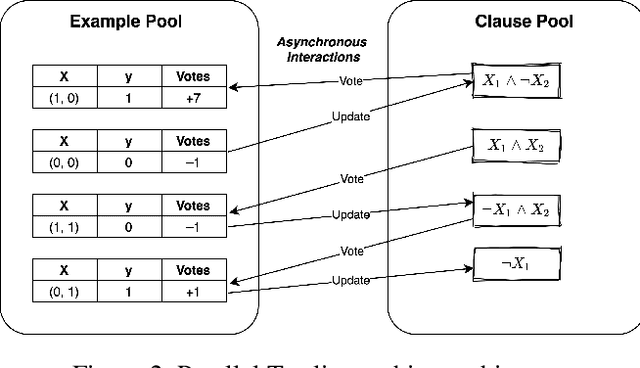
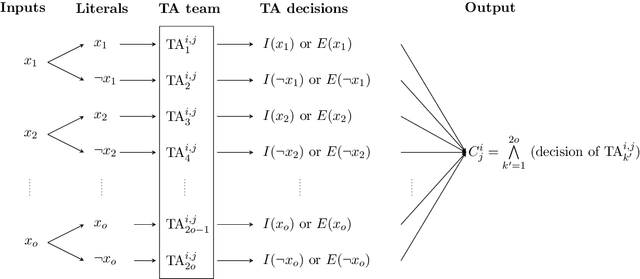
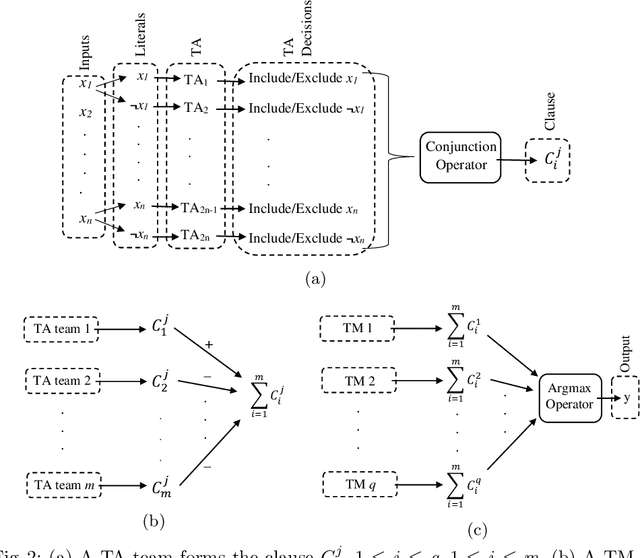
Using logical clauses to represent patterns, Tsetlin machines (TMs) have recently obtained competitive performance in terms of accuracy, memory footprint, energy, and learning speed on several benchmarks. A team of Tsetlin automata (TAs) composes each clause, thus driving the entire learning process. These are rewarded/penalized according to three local rules that optimize global behaviour. Each clause votes for or against a particular class, with classification resolved using a majority vote. In the parallel and asynchronous architecture that we propose here, every clause runs in its own thread for massive parallelism. For each training example, we keep track of the class votes obtained from the clauses in local voting tallies. The local voting tallies allow us to detach the processing of each clause from the rest of the clauses, supporting decentralized learning. Thus, rather than processing training examples one-by-one as in the original TM, the clauses access the training examples simultaneously, updating themselves and the local voting tallies in parallel. There is no synchronization among the clause threads, apart from atomic adds to the local voting tallies. Operating asynchronously, each team of TA will most of the time operate on partially calculated or outdated voting tallies. However, across diverse learning tasks, it turns out that our decentralized TM learning algorithm copes well with working on outdated data, resulting in no significant loss in learning accuracy. Further, we show that the approach provides up to 50 times faster learning. Finally, learning time is almost constant for reasonable clause amounts. For sufficiently large clause numbers, computation time increases approximately proportionally. Our parallel and asynchronous architecture thus allows processing of more massive datasets and operating with more clauses for higher accuracy.
A Novel Multi-Step Finite-State Automaton for Arbitrarily Deterministic Tsetlin Machine Learning
Jul 04, 2020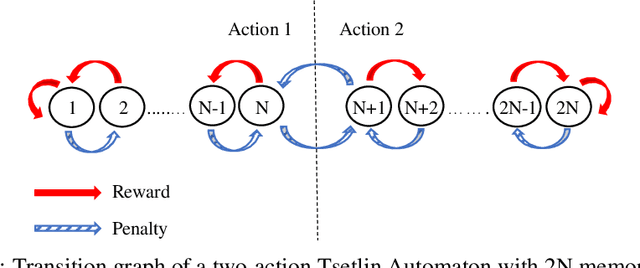
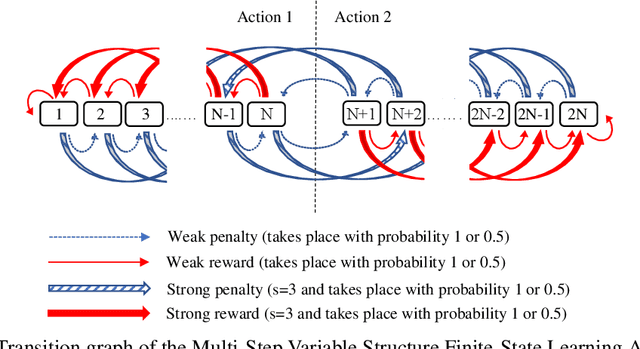
Due to the high energy consumption and scalability challenges of deep learning, there is a critical need to shift research focus towards dealing with energy consumption constraints. Tsetlin Machines (TMs) are a recent approach to machine learning that has demonstrated significantly reduced energy usage compared to neural networks alike, while performing competitively accuracy-wise on several benchmarks. However, TMs rely heavily on energy-costly random number generation to stochastically guide a team of Tsetlin Automata to a Nash Equilibrium of the TM game. In this paper, we propose a novel finite-state learning automaton that can replace the Tsetlin Automata in TM learning, for increased determinism. The new automaton uses multi-step deterministic state jumps to reinforce sub-patterns. Simultaneously, flipping a coin to skip every $d$'th state update ensures diversification by randomization. The $d$-parameter thus allows the degree of randomization to be finely controlled. E.g., $d=1$ makes every update random and $d=\infty$ makes the automaton completely deterministic. Our empirical results show that, overall, only substantial degrees of determinism reduces accuracy. Energy-wise, random number generation constitutes switching energy consumption of the TM, saving up to 11 mW power for larger datasets with high $d$ values. We can thus use the new $d$-parameter to trade off accuracy against energy consumption, to facilitate low-energy machine learning.
Extending the Tsetlin Machine With Integer-Weighted Clauses for Increased Interpretability
May 11, 2020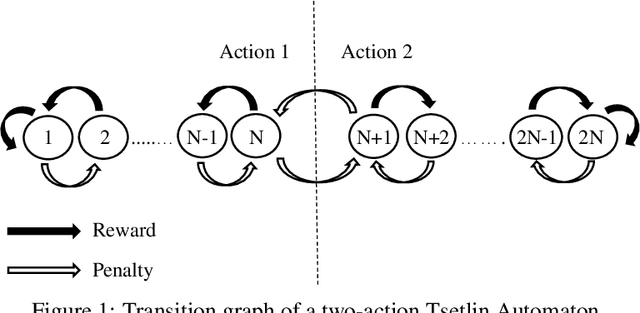

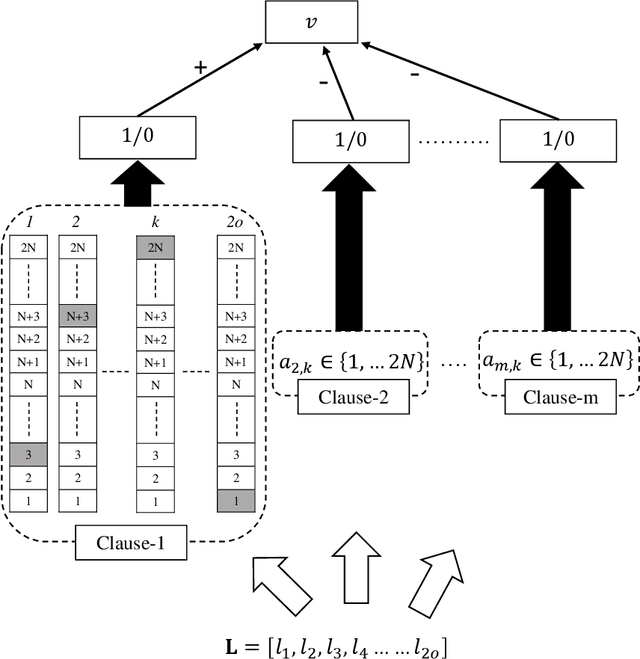
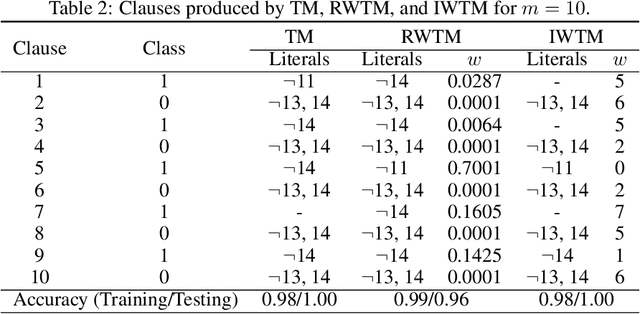
Despite significant effort, building models that are both interpretable and accurate is an unresolved challenge for many pattern recognition problems. In general, rule-based and linear models lack accuracy, while deep learning interpretability is based on rough approximations of the underlying inference. Using a linear combination of conjunctive clauses in propositional logic, Tsetlin Machines (TMs) have shown competitive performance on diverse benchmarks. However, to do so, many clauses are needed, which impacts interpretability. Here, we address the accuracy-interpretability challenge in machine learning by equipping the TM clauses with integer weights. The resulting Integer Weighted TM (IWTM) deals with the problem of learning which clauses are inaccurate and thus must team up to obtain high accuracy as a team (low weight clauses), and which clauses are sufficiently accurate to operate more independently (high weight clauses). Since each TM clause is formed adaptively by a team of Tsetlin Automata, identifying effective weights becomes a challenging online learning problem. We address this problem by extending each team of Tsetlin Automata with a stochastic searching on the line (SSL) automaton. In our novel scheme, the SSL automaton learns the weight of its clause in interaction with the corresponding Tsetlin Automata team, which, in turn, adapts the composition of the clause by the adjusting weight. We evaluate IWTM empirically using five datasets, including a study of interpetability. On average, IWTM uses 6.5 times fewer literals than the vanilla TM and 120 times fewer literals than a TM with real-valued weights. Furthermore, in terms of average F1-Score, IWTM outperforms simple Multi-Layered Artificial Neural Networks, Decision Trees, Support Vector Machines, K-Nearest Neighbor, Random Forest, XGBoost, Explainable Boosting Machines, and standard and real-value weighted TMs.
A Regression Tsetlin Machine with Integer Weighted Clauses for Compact Pattern Representation
Feb 04, 2020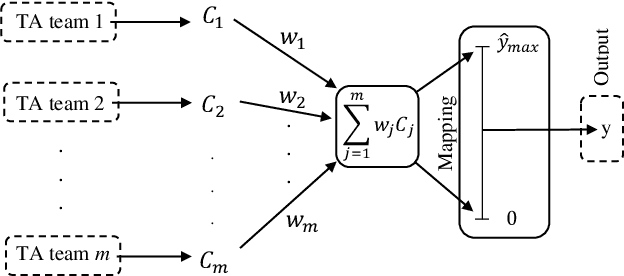
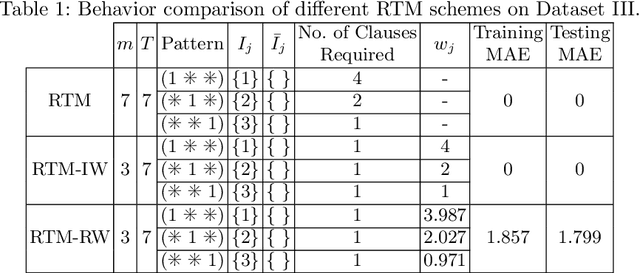
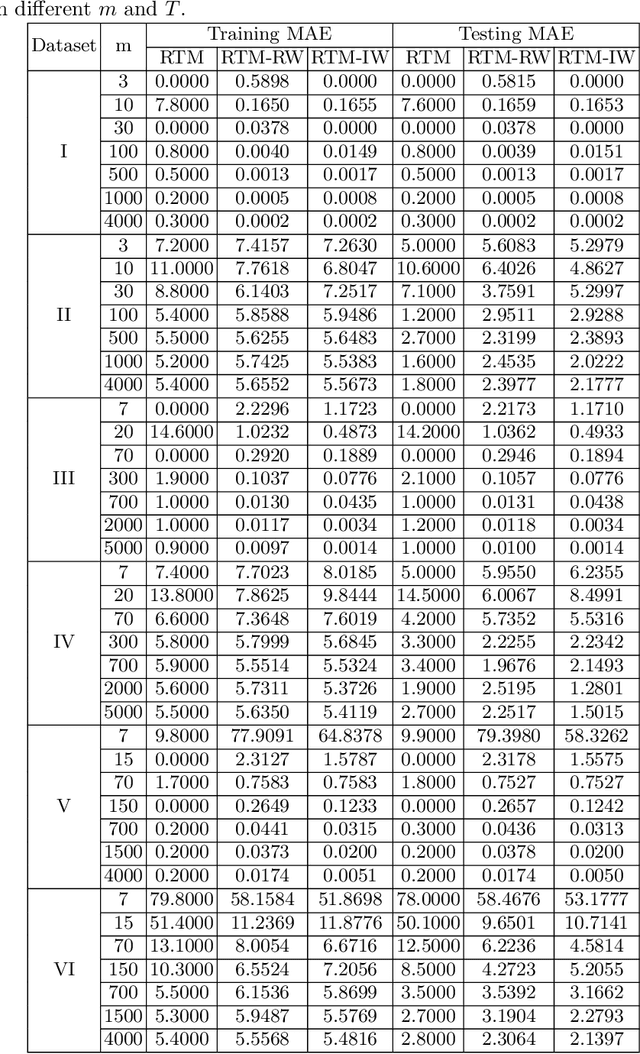
The Regression Tsetlin Machine (RTM) addresses the lack of interpretability impeding state-of-the-art nonlinear regression models. It does this by using conjunctive clauses in propositional logic to capture the underlying non-linear frequent patterns in the data. These, in turn, are combined into a continuous output through summation, akin to a linear regression function, however, with non-linear components and unity weights. Although the RTM has solved non-linear regression problems with competitive accuracy, the resolution of the output is proportional to the number of clauses employed. This means that computation cost increases with resolution. To reduce this problem, we here introduce integer weighted RTM clauses. Our integer weighted clause is a compact representation of multiple clauses that capture the same sub-pattern-N repeating clauses are turned into one, with an integer weight N. This reduces computation cost N times, and increases interpretability through a sparser representation. We further introduce a novel learning scheme that allows us to simultaneously learn both the clauses and their weights, taking advantage of so-called stochastic searching on the line. We evaluate the potential of the integer weighted RTM empirically using six artificial datasets. The results show that the integer weighted RTM is able to acquire on par or better accuracy using significantly less computational resources compared to regular RTMs. We further show that integer weights yield improved accuracy over real-valued ones.
The Regression Tsetlin Machine: A Tsetlin Machine for Continuous Output Problems
May 10, 2019
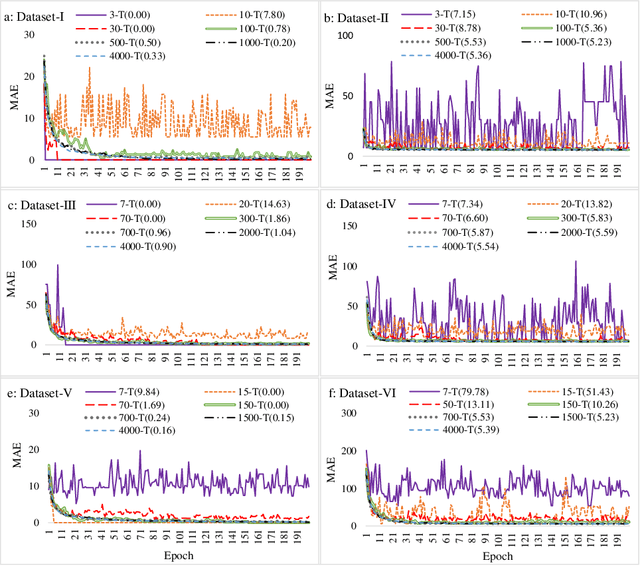
The recently introduced Tsetlin Machine (TM) has provided competitive pattern classification accuracy in several benchmarks, composing patterns with easy-to-interpret conjunctive clauses in propositional logic. In this paper, we go beyond pattern classification by introducing a new type of TMs, namely, the Regression Tsetlin Machine (RTM). In all brevity, we modify the inner inference mechanism of the TM so that input patterns are transformed into a single continuous output, rather than to distinct categories. We achieve this by: (1) using the conjunctive clauses of the TM to capture arbitrarily complex patterns; (2) mapping these patterns to a continuous output through a novel voting and normalization mechanism; and (3) employing a feedback scheme that updates the TM clauses to minimize the regression error. The feedback scheme uses a new activation probability function that stabilizes the updating of clauses, while the overall system converges towards an accurate input-output mapping. The performance of the proposed approach is evaluated using six different artificial datasets with and without noise. The performance of the RTM is compared with the Classical Tsetlin Machine (CTM) and the Multiclass Tsetlin Machine (MTM). Our empirical results indicate that the RTM obtains the best training and testing results for both noisy and noise-free datasets, with a smaller number of clauses. This, in turn, translates to higher regression accuracy, using significantly less computational resources.
A Scheme for Continuous Input to the Tsetlin Machine with Applications to Forecasting Disease Outbreaks
May 10, 2019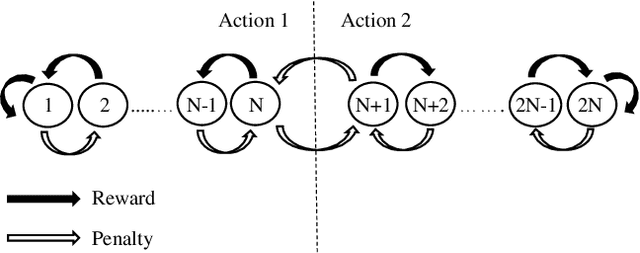
In this paper, we apply a new promising tool for pattern classification, namely, the Tsetlin Machine (TM), to the field of disease forecasting. The TM is interpretable because it is based on manipulating expressions in propositional logic, leveraging a large team of Tsetlin Automata (TA). Apart from being interpretable, this approach is attractive due to its low computational cost and its capacity to handle noise. To attack the problem of forecasting, we introduce a preprocessing method that extends the TM so that it can handle continuous input. Briefly stated, we convert continuous input into a binary representation based on thresholding. The resulting extended TM is evaluated and analyzed using an artificial dataset. The TM is further applied to forecast dengue outbreaks of all the seventeen regions in Philippines using the spatio-temporal properties of the data. Experimental results show that dengue outbreak forecasts made by the TM are more accurate than those obtained by a Support Vector Machine (SVM), Decision Trees (DTs), and several multi-layered Artificial Neural Networks (ANNs), both in terms of forecasting precision and F1-score.