 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreventing Data Leakage in EEG-Based Survival Prediction: A Two-Stage Embedding and Transformer Framework
Mar 26, 2026Deep learning models have shown promise in EEG-based outcome prediction for comatose patients after cardiac arrest, but their reliability is often compromised by subtle forms of data leakage. In particular, when long EEG recordings are segmented into short windows and reused across multiple training stages, models may implicitly encode and propagate label information, leading to overly optimistic validation performance and poor generalization. In this study, we identify a previously overlooked form of data leakage in multi-stage EEG modeling pipelines. We demonstrate that violating strict patient-level separation can significantly inflate validation metrics while causing substantial degradation on independent test data. To address this issue, we propose a leakage-aware two-stage framework. In the first stage, short EEG segments are transformed into embedding representations using a convolutional neural network with an ArcFace objective. In the second stage, a Transformer-based model aggregates these embeddings to produce patient-level predictions, with strict isolation between training cohorts to eliminate leakage pathways. Experiments on a large-scale EEG dataset of post-cardiac-arrest patients show that the proposed framework achieves stable and generalizable performance under clinically relevant constraints, particularly in maintaining high sensitivity at stringent specificity thresholds. These results highlight the importance of rigorous data partitioning and provide a practical solution for reliable EEG-based outcome prediction.
Knowledge-Informed Automatic Feature Extraction via Collaborative Large Language Model Agents
Nov 19, 2025The performance of machine learning models on tabular data is critically dependent on high-quality feature engineering. While Large Language Models (LLMs) have shown promise in automating feature extraction (AutoFE), existing methods are often limited by monolithic LLM architectures, simplistic quantitative feedback, and a failure to systematically integrate external domain knowledge. This paper introduces Rogue One, a novel, LLM-based multi-agent framework for knowledge-informed automatic feature extraction. Rogue One operationalizes a decentralized system of three specialized agents-Scientist, Extractor, and Tester-that collaborate iteratively to discover, generate, and validate predictive features. Crucially, the framework moves beyond primitive accuracy scores by introducing a rich, qualitative feedback mechanism and a "flooding-pruning" strategy, allowing it to dynamically balance feature exploration and exploitation. By actively incorporating external knowledge via an integrated retrieval-augmented (RAG) system, Rogue One generates features that are not only statistically powerful but also semantically meaningful and interpretable. We demonstrate that Rogue One significantly outperforms state-of-the-art methods on a comprehensive suite of 19 classification and 9 regression datasets. Furthermore, we show qualitatively that the system surfaces novel, testable hypotheses, such as identifying a new potential biomarker in the myocardial dataset, underscoring its utility as a tool for scientific discovery.
A Methodology for Transparent Logic-Based Classification Using a Multi-Task Convolutional Tsetlin Machine
Oct 02, 2025



The Tsetlin Machine (TM) is a novel machine learning paradigm that employs finite-state automata for learning and utilizes propositional logic to represent patterns. Due to its simplistic approach, TMs are inherently more interpretable than learning algorithms based on Neural Networks. The Convolutional TM has shown comparable performance on various datasets such as MNIST, K-MNIST, F-MNIST and CIFAR-2. In this paper, we explore the applicability of the TM architecture for large-scale multi-channel (RGB) image classification. We propose a methodology to generate both local interpretations and global class representations. The local interpretations can be used to explain the model predictions while the global class representations aggregate important patterns for each class. These interpretations summarize the knowledge captured by the convolutional clauses, which can be visualized as images. We evaluate our methods on MNIST and CelebA datasets, using models that achieve 98.5\% accuracy on MNIST and 86.56\% F1-score on CelebA (compared to 88.07\% for ResNet50) respectively. We show that the TM performs competitively to this deep learning model while maintaining its interpretability, even in large-scale complex training environments. This contributes to a better understanding of TM clauses and provides insights into how these models can be applied to more complex and diverse datasets.
Efficient Data Fusion using the Tsetlin Machine
Oct 26, 2023



We propose a novel way of assessing and fusing noisy dynamic data using a Tsetlin Machine. Our approach consists in monitoring how explanations in form of logical clauses that a TM learns changes with possible noise in dynamic data. This way TM can recognize the noise by lowering weights of previously learned clauses, or reflect it in the form of new clauses. We also perform a comprehensive experimental study using notably different datasets that demonstrated high performance of the proposed approach.
A Relational Tsetlin Machine with Applications to Natural Language Understanding
Feb 22, 2021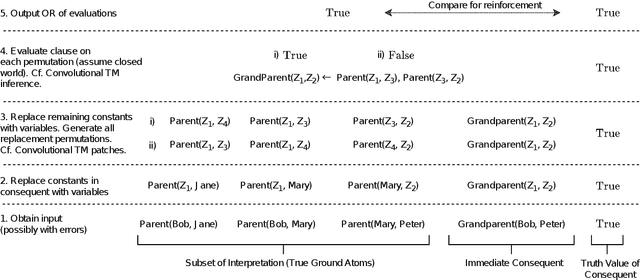


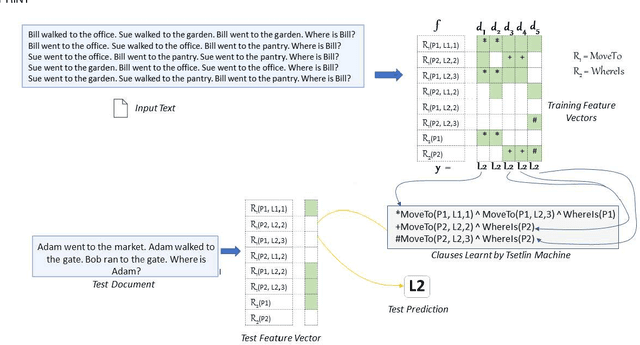
TMs are a pattern recognition approach that uses finite state machines for learning and propositional logic to represent patterns. In addition to being natively interpretable, they have provided competitive accuracy for various tasks. In this paper, we increase the computing power of TMs by proposing a first-order logic-based framework with Herbrand semantics. The resulting TM is relational and can take advantage of logical structures appearing in natural language, to learn rules that represent how actions and consequences are related in the real world. The outcome is a logic program of Horn clauses, bringing in a structured view of unstructured data. In closed-domain question-answering, the first-order representation produces 10x more compact KBs, along with an increase in answering accuracy from 94.83% to 99.48%. The approach is further robust towards erroneous, missing, and superfluous information, distilling the aspects of a text that are important for real-world understanding.