 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTsetlin Machine Embedding: Representing Words Using Logical Expressions
Jan 02, 2023



Embedding words in vector space is a fundamental first step in state-of-the-art natural language processing (NLP). Typical NLP solutions employ pre-defined vector representations to improve generalization by co-locating similar words in vector space. For instance, Word2Vec is a self-supervised predictive model that captures the context of words using a neural network. Similarly, GLoVe is a popular unsupervised model incorporating corpus-wide word co-occurrence statistics. Such word embedding has significantly boosted important NLP tasks, including sentiment analysis, document classification, and machine translation. However, the embeddings are dense floating-point vectors, making them expensive to compute and difficult to interpret. In this paper, we instead propose to represent the semantics of words with a few defining words that are related using propositional logic. To produce such logical embeddings, we introduce a Tsetlin Machine-based autoencoder that learns logical clauses self-supervised. The clauses consist of contextual words like "black," "cup," and "hot" to define other words like "coffee," thus being human-understandable. We evaluate our embedding approach on several intrinsic and extrinsic benchmarks, outperforming GLoVe on six classification tasks. Furthermore, we investigate the interpretability of our embedding using the logical representations acquired during training. We also visualize word clusters in vector space, demonstrating how our logical embedding co-locate similar words.
On the Equivalence of the Weighted Tsetlin Machine and the Perceptron
Dec 27, 2022Tsetlin Machine (TM) has been gaining popularity as an inherently interpretable machine leaning method that is able to achieve promising performance with low computational complexity on a variety of applications. The interpretability and the low computational complexity of the TM are inherited from the Boolean expressions for representing various sub-patterns. Although possessing favorable properties, TM has not been the go-to method for AI applications, mainly due to its conceptual and theoretical differences compared with perceptrons and neural networks, which are more widely known and well understood. In this paper, we provide detailed insights for the operational concept of the TM, and try to bridge the gap in the theoretical understanding between the perceptron and the TM. More specifically, we study the operational concept of the TM following the analytical structure of perceptrons, showing the resemblance between the perceptrons and the TM. Through the analysis, we indicated that the TM's weight update can be considered as a special case of the gradient weight update. We also perform an empirical analysis of TM by showing the flexibility in determining the clause length, visualization of decision boundaries and obtaining interpretable boolean expressions from TM. In addition, we also discuss the advantages of TM in terms of its structure and its ability to solve more complex problems.
CaiRL: A High-Performance Reinforcement Learning Environment Toolkit
Oct 03, 2022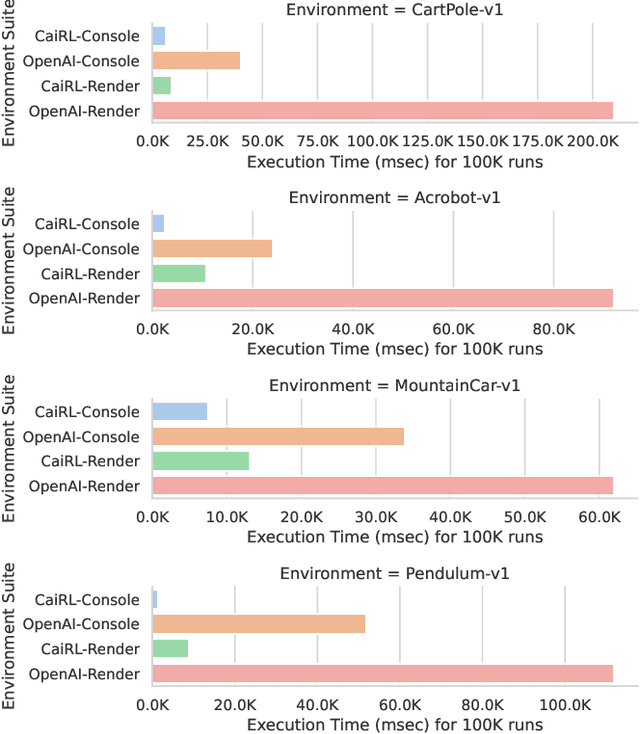
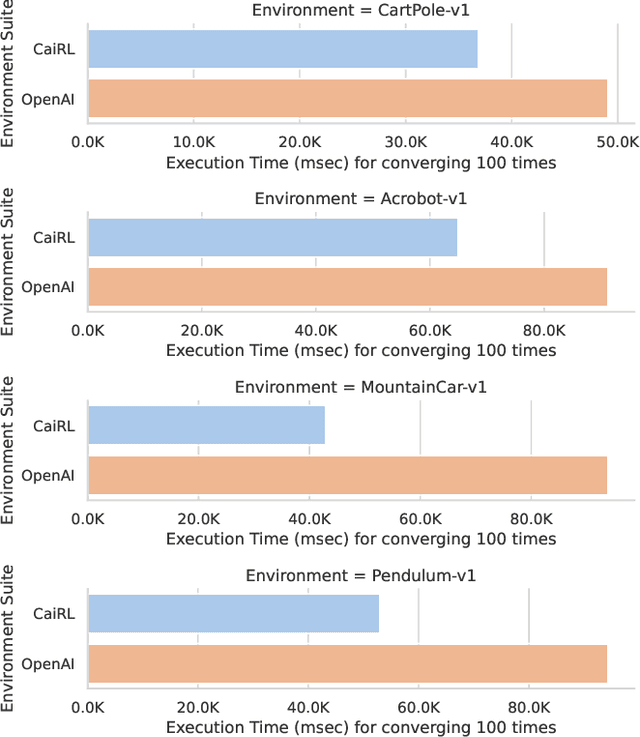
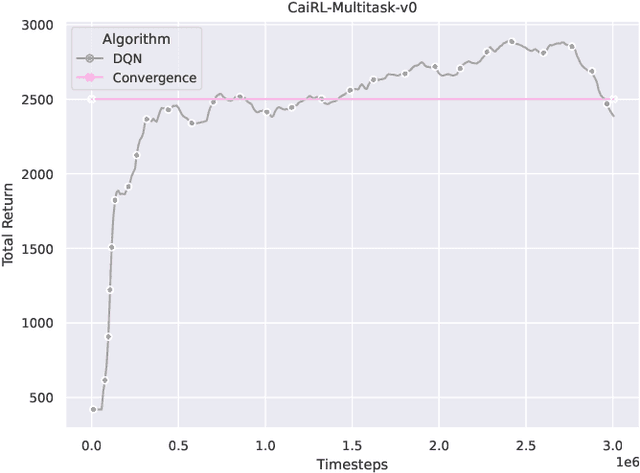
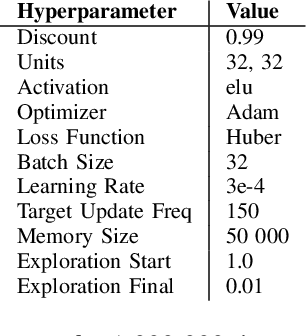
This paper addresses the dire need for a platform that efficiently provides a framework for running reinforcement learning (RL) experiments. We propose the CaiRL Environment Toolkit as an efficient, compatible, and more sustainable alternative for training learning agents and propose methods to develop more efficient environment simulations. There is an increasing focus on developing sustainable artificial intelligence. However, little effort has been made to improve the efficiency of running environment simulations. The most popular development toolkit for reinforcement learning, OpenAI Gym, is built using Python, a powerful but slow programming language. We propose a toolkit written in C++ with the same flexibility level but works orders of magnitude faster to make up for Python's inefficiency. This would drastically cut climate emissions. CaiRL also presents the first reinforcement learning toolkit with a built-in JVM and Flash support for running legacy flash games for reinforcement learning research. We demonstrate the effectiveness of CaiRL in the classic control benchmark, comparing the execution speed to OpenAI Gym. Furthermore, we illustrate that CaiRL can act as a drop-in replacement for OpenAI Gym to leverage significantly faster training speeds because of the reduced environment computation time.
* Published in 2022 IEEE Conference on Games (CoG)
Interpretable Option Discovery using Deep Q-Learning and Variational Autoencoders
Oct 03, 2022Deep Reinforcement Learning (RL) is unquestionably a robust framework to train autonomous agents in a wide variety of disciplines. However, traditional deep and shallow model-free RL algorithms suffer from low sample efficiency and inadequate generalization for sparse state spaces. The options framework with temporal abstractions is perhaps the most promising method to solve these problems, but it still has noticeable shortcomings. It only guarantees local convergence, and it is challenging to automate initiation and termination conditions, which in practice are commonly hand-crafted. Our proposal, the Deep Variational Q-Network (DVQN), combines deep generative- and reinforcement learning. The algorithm finds good policies from a Gaussian distributed latent-space, which is especially useful for defining options. The DVQN algorithm uses MSE with KL-divergence as regularization, combined with traditional Q-Learning updates. The algorithm learns a latent-space that represents good policies with state clusters for options. We show that the DVQN algorithm is a promising approach for identifying initiation and termination conditions for option-based reinforcement learning. Experiments show that the DVQN algorithm, with automatic initiation and termination, has comparable performance to Rainbow and can maintain stability when trained for extended periods after convergence.
* 12 pages, 5 figures, Proceedings of the 3rd International Conference on Intelligent Technologies and Applications
CostNet: An End-to-End Framework for Goal-Directed Reinforcement Learning
Oct 03, 2022Reinforcement Learning (RL) is a general framework concerned with an agent that seeks to maximize rewards in an environment. The learning typically happens through trial and error using explorative methods, such as epsilon-greedy. There are two approaches, model-based and model-free reinforcement learning, that show concrete results in several disciplines. Model-based RL learns a model of the environment for learning the policy while model-free approaches are fully explorative and exploitative without considering the underlying environment dynamics. Model-free RL works conceptually well in simulated environments, and empirical evidence suggests that trial and error lead to a near-optimal behavior with enough training. On the other hand, model-based RL aims to be sample efficient, and studies show that it requires far less training in the real environment for learning a good policy. A significant challenge with RL is that it relies on a well-defined reward function to work well for complex environments and such a reward function is challenging to define. Goal-Directed RL is an alternative method that learns an intrinsic reward function with emphasis on a few explored trajectories that reveals the path to the goal state. This paper introduces a novel reinforcement learning algorithm for predicting the distance between two states in a Markov Decision Process. The learned distance function works as an intrinsic reward that fuels the agent's learning. Using the distance-metric as a reward, we show that the algorithm performs comparably to model-free RL while having significantly better sample-efficiently in several test environments.
* 14 pages, 5 figures, In Proceedings of the International Conference on Innovative Techniques and Applications of Artificial Intelligence, SGAI2020
Towards Artificial Virtuous Agents: Games, Dilemmas and Machine Learning
Aug 30, 2022
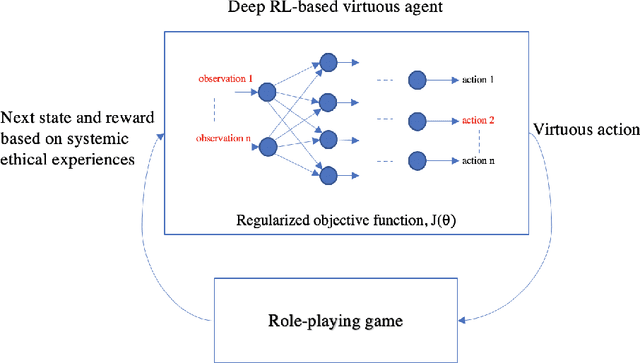
Machine ethics has received increasing attention over the past few years because of the need to ensure safe and reliable artificial intelligence (AI). The two dominantly used theories in machine ethics are deontological and utilitarian ethics. Virtue ethics, on the other hand, has often been mentioned as an alternative ethical theory. While this interesting approach has certain advantages over popular ethical theories, little effort has been put into engineering artificial virtuous agents due to challenges in their formalization, codifiability, and the resolution of ethical dilemmas to train virtuous agents. We propose to bridge this gap by using role-playing games riddled with moral dilemmas. There are several such games in existence, such as Papers, Please and Life is Strange, where the main character encounters situations where they must choose the right course of action by giving up something else dear to them. We draw inspiration from such games to show how a systemic role-playing game can be designed to develop virtues within an artificial agent. Using modern day AI techniques, such as affinity-based reinforcement learning and explainable AI, we motivate the implementation of virtuous agents that play such role-playing games, and the examination of their decisions through a virtue ethical lens. The development of such agents and environments is a first step towards practically formalizing and demonstrating the value of virtue ethics in the development of ethical agents.
Socially Fair Mitigation of Misinformation on Social Networks via Constraint Stochastic Optimization
Mar 23, 2022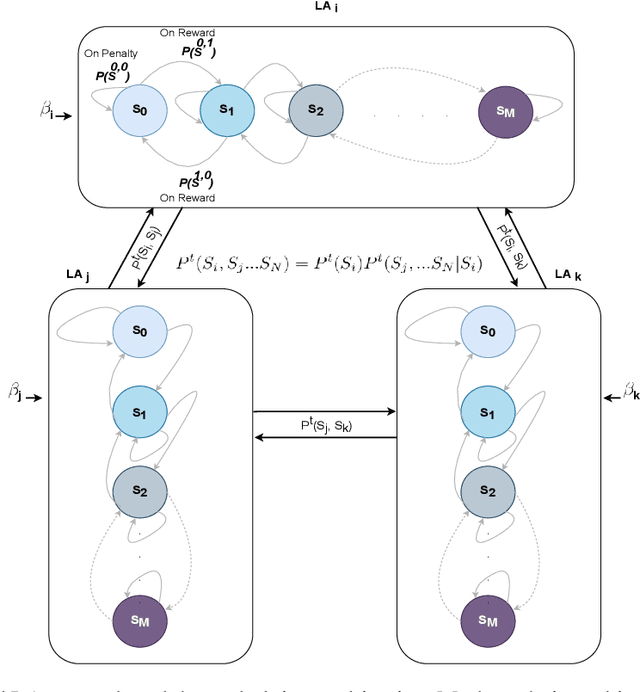
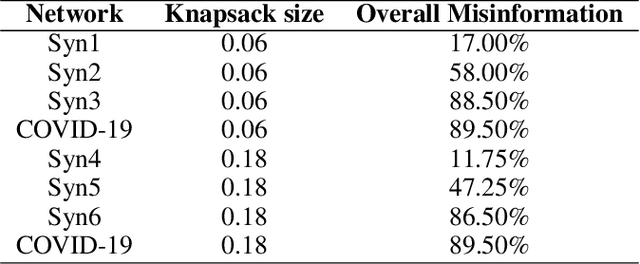
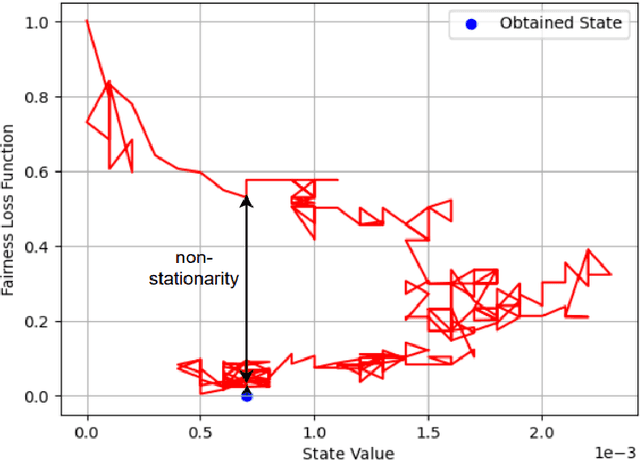
Recent social networks' misinformation mitigation approaches tend to investigate how to reduce misinformation by considering a whole-network statistical scale. However, unbalanced misinformation exposures among individuals urge to study fair allocation of mitigation resources. Moreover, the network has random dynamics which change over time. Therefore, we introduce a stochastic and non-stationary knapsack problem, and we apply its resolution to mitigate misinformation in social network campaigns. We further propose a generic misinformation mitigation algorithm that is robust to different social networks' misinformation statistics, allowing a promising impact in real-world scenarios. A novel loss function ensures fair mitigation among users. We achieve fairness by intelligently allocating a mitigation incentivization budget to the knapsack, and optimizing the loss function. To this end, a team of Learning Automata (LA) drives the budget allocation. Each LA is associated with a user and learns to minimize its exposure to misinformation by performing a non-stationary and stochastic walk over its state space. Our results show how our LA-based method is robust and outperforms similar misinformation mitigation methods in how the mitigation is fairly influencing the network users.
Logic-based AI for Interpretable Board Game Winner Prediction with Tsetlin Machine
Mar 08, 2022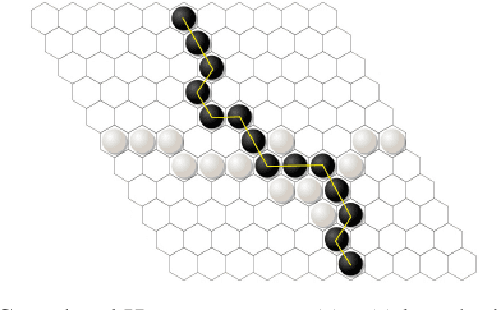
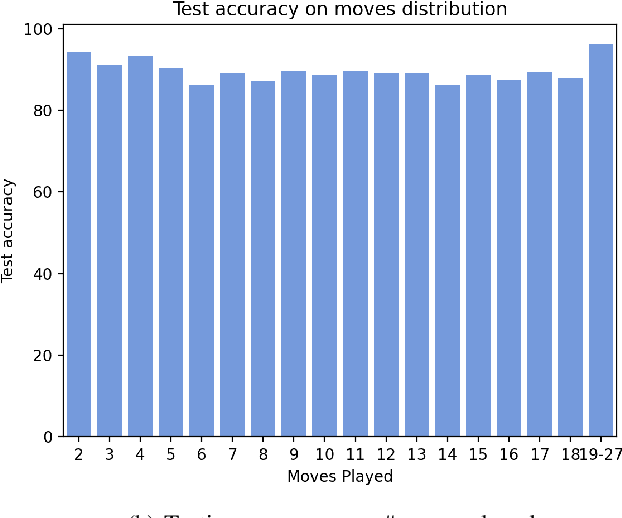
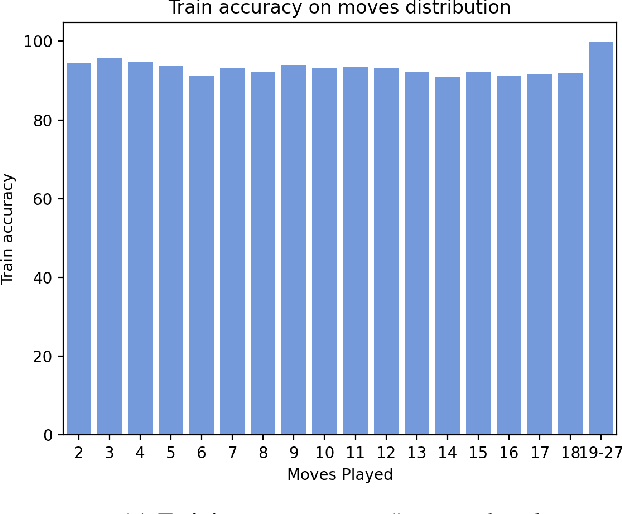
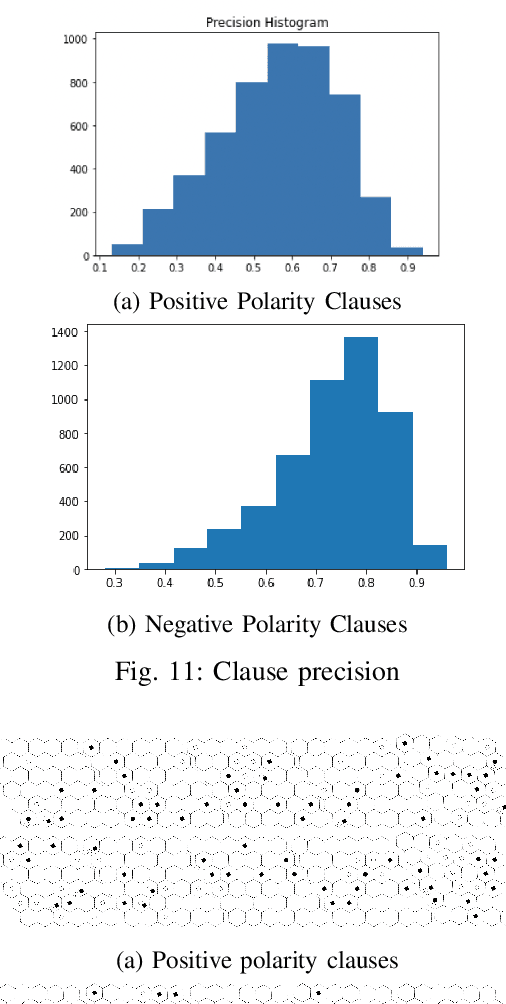
Hex is a turn-based two-player connection game with a high branching factor, making the game arbitrarily complex with increasing board sizes. As such, top-performing algorithms for playing Hex rely on accurate evaluation of board positions using neural networks. However, the limited interpretability of neural networks is problematic when the user wants to understand the reasoning behind the predictions made. In this paper, we propose to use propositional logic expressions to describe winning and losing board game positions, facilitating precise visual interpretation. We employ a Tsetlin Machine (TM) to learn these expressions from previously played games, describing where pieces must be located or not located for a board position to be strong. Extensive experiments on $6\times6$ boards compare our TM-based solution with popular machine learning algorithms like XGBoost, InterpretML, decision trees, and neural networks, considering various board configurations with $2$ to $22$ moves played. On average, the TM testing accuracy is $92.1\%$, outperforming all the other evaluated algorithms. We further demonstrate the global interpretation of the logical expressions and map them down to particular board game configurations to investigate local interpretability. We believe the resulting interpretability establishes building blocks for accurate assistive AI and human-AI collaboration, also for more complex prediction tasks.
Tsetlin Machine for Solving Contextual Bandit Problems
Feb 04, 2022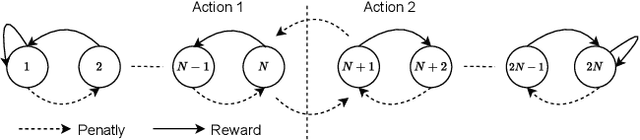
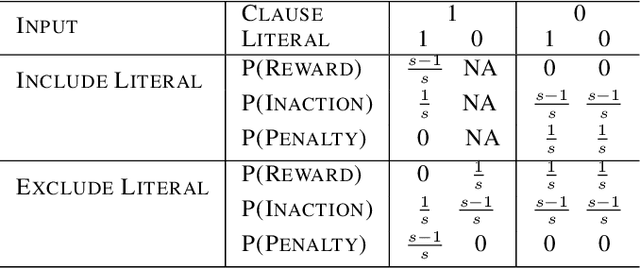
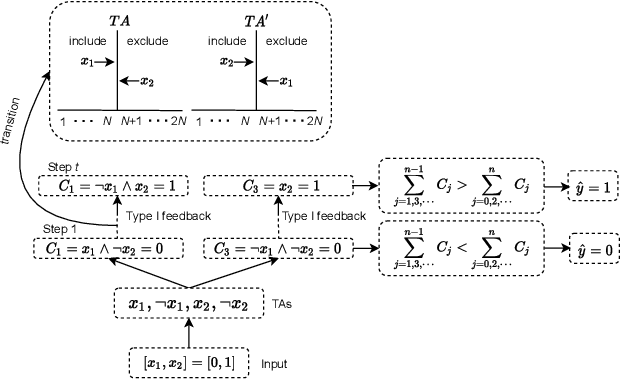
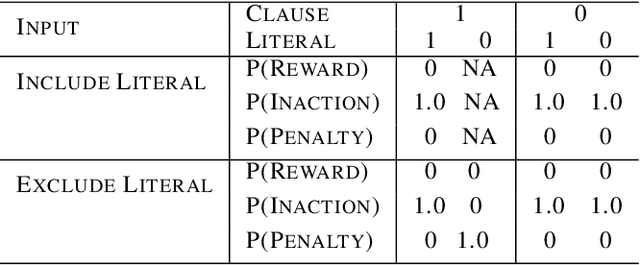
This paper introduces an interpretable contextual bandit algorithm using Tsetlin Machines, which solves complex pattern recognition tasks using propositional logic. The proposed bandit learning algorithm relies on straightforward bit manipulation, thus simplifying computation and interpretation. We then present a mechanism for performing Thompson sampling with Tsetlin Machine, given its non-parametric nature. Our empirical analysis shows that Tsetlin Machine as a base contextual bandit learner outperforms other popular base learners on eight out of nine datasets. We further analyze the interpretability of our learner, investigating how arms are selected based on propositional expressions that model the context.
On the Convergence of Tsetlin Machines for the AND and the OR Operators
Sep 17, 2021
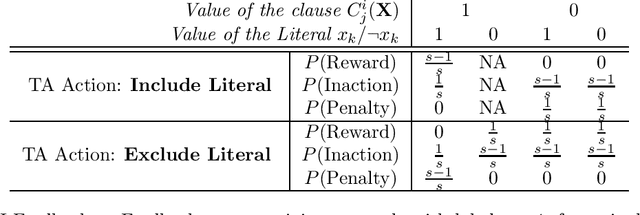
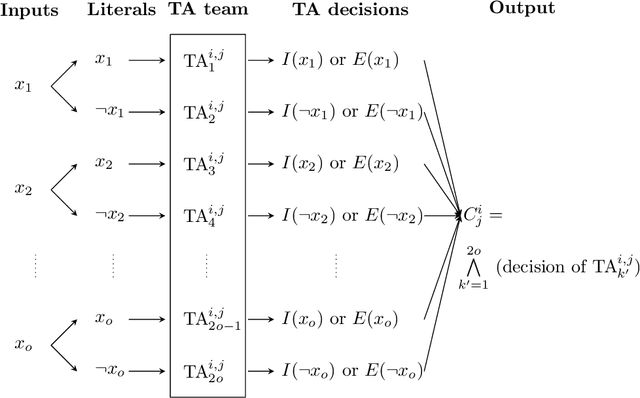
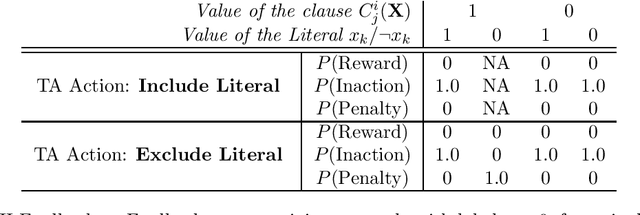
The Tsetlin Machine (TM) is a novel machine-learning algorithm based on propositional logic, which has obtained state-of-the-art performance on several pattern recognition problems. In previous studies, the convergence properties of TM for 1-bit operation and XOR operation have been analyzed. To make the analyses for the basic digital operations complete, in this article, we analyze the convergence when input training samples follow AND and OR operators respectively. Our analyses reveal that the TM can converge almost surely to reproduce AND and OR operators, which are learnt from training data over an infinite time horizon. The analyses on AND and OR operators, together with the previously analysed 1-bit and XOR operations, complete the convergence analyses on basic operators in Boolean algebra.