 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFog of Love: Engineering Virtuous Agent Behavior with Affinity-based Reinforcement Learning in a Game Environment
Jun 03, 2026Instilling virtuous behavior in artificial intelligence has seen increasing interest. One of the techniques proposed is known as affinity-based reinforcement learning, which uses policy regularization on the objective function to incentivize virtuous actions without being fully dependent on the reward function design. Thus far, this technique has been demonstrated to be effective in grid worlds and toy-problem environments with minimal state and action spaces. To expand this research to more sophisticated environments, we introduce a two-player multi-agent environment based on the role-playing board game known as Fog of Love. In this environment, two agents compete to fulfill their individual virtues, while also cooperating to satisfy their relationship. Given the multi-agent nature, this is a complex problem where multi-agent deep deterministic policy gradient agents neither compete nor cooperate successfully. We present evidence that localized affinities enhance agent performance in achieving both competitive and cooperative objectives, resulting from superior overall scores in both domains. This not only results in virtuous choices but also clarifies an agent's teleology and makes its behavior human-level interpretable.
Towards Artificial Virtuous Agents: Games, Dilemmas and Machine Learning
Aug 30, 2022
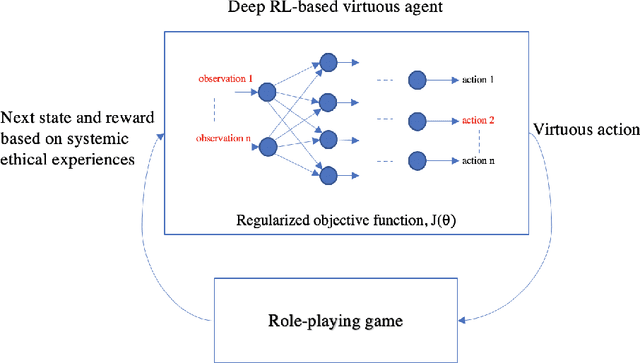
Machine ethics has received increasing attention over the past few years because of the need to ensure safe and reliable artificial intelligence (AI). The two dominantly used theories in machine ethics are deontological and utilitarian ethics. Virtue ethics, on the other hand, has often been mentioned as an alternative ethical theory. While this interesting approach has certain advantages over popular ethical theories, little effort has been put into engineering artificial virtuous agents due to challenges in their formalization, codifiability, and the resolution of ethical dilemmas to train virtuous agents. We propose to bridge this gap by using role-playing games riddled with moral dilemmas. There are several such games in existence, such as Papers, Please and Life is Strange, where the main character encounters situations where they must choose the right course of action by giving up something else dear to them. We draw inspiration from such games to show how a systemic role-playing game can be designed to develop virtues within an artificial agent. Using modern day AI techniques, such as affinity-based reinforcement learning and explainable AI, we motivate the implementation of virtuous agents that play such role-playing games, and the examination of their decisions through a virtue ethical lens. The development of such agents and environments is a first step towards practically formalizing and demonstrating the value of virtue ethics in the development of ethical agents.
Can Interpretable Reinforcement Learning Manage Assets Your Way?
Feb 18, 2022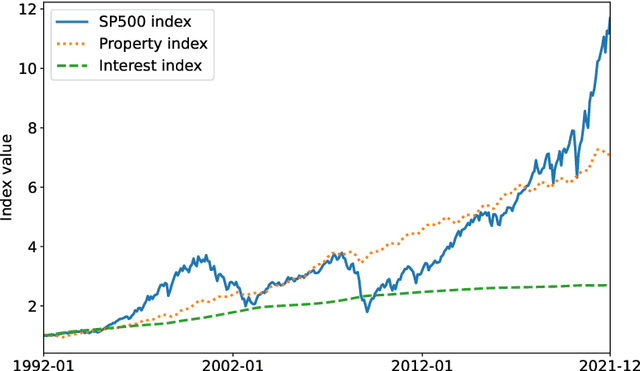
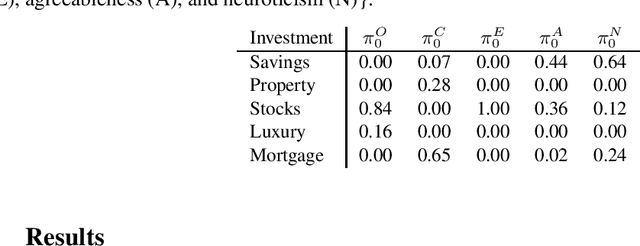
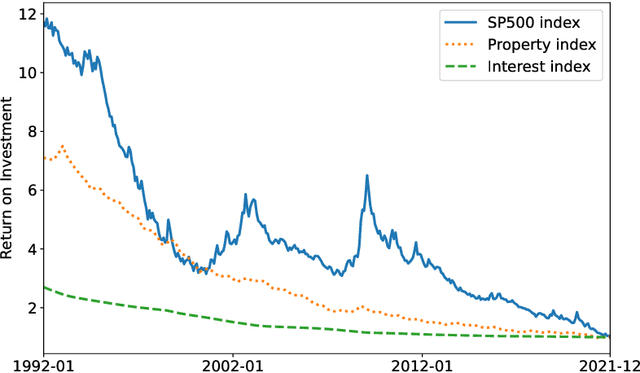
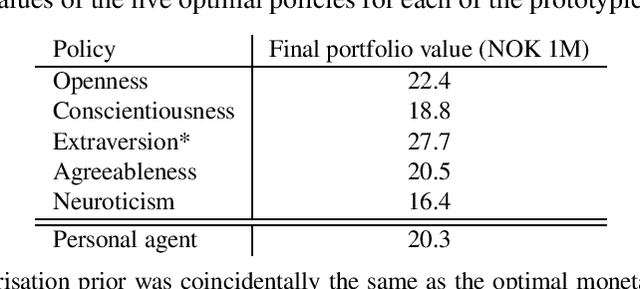
Personalisation of products and services is fast becoming the driver of success in banking and commerce. Machine learning holds the promise of gaining a deeper understanding of and tailoring to customers' needs and preferences. Whereas traditional solutions to financial decision problems frequently rely on model assumptions, reinforcement learning is able to exploit large amounts of data to improve customer modelling and decision-making in complex financial environments with fewer assumptions. Model explainability and interpretability present challenges from a regulatory perspective which demands transparency for acceptance; they also offer the opportunity for improved insight into and understanding of customers. Post-hoc approaches are typically used for explaining pretrained reinforcement learning models. Based on our previous modeling of customer spending behaviour, we adapt our recent reinforcement learning algorithm that intrinsically characterizes desirable behaviours and we transition to the problem of asset management. We train inherently interpretable reinforcement learning agents to give investment advice that is aligned with prototype financial personality traits which are combined to make a final recommendation. We observe that the trained agents' advice adheres to their intended characteristics, they learn the value of compound growth, and, without any explicit reference, the notion of risk as well as improved policy convergence.
Reinforcement Learning Your Way: Agent Characterization through Policy Regularization
Jan 21, 2022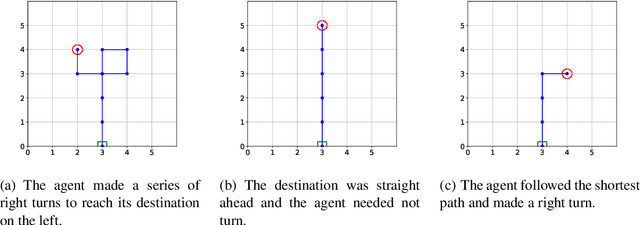
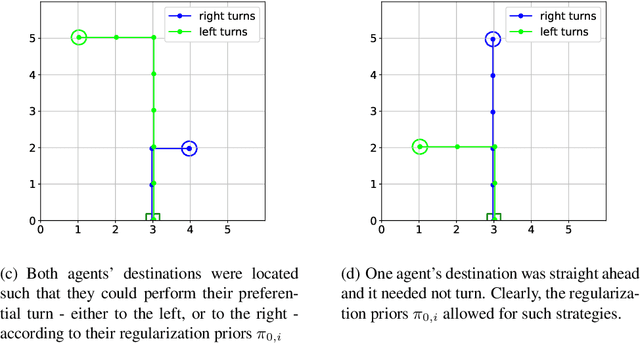
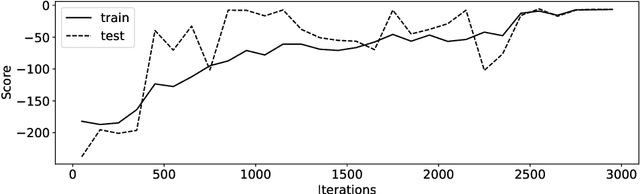
The increased complexity of state-of-the-art reinforcement learning (RL) algorithms have resulted in an opacity that inhibits explainability and understanding. This has led to the development of several post-hoc explainability methods that aim to extract information from learned policies thus aiding explainability. These methods rely on empirical observations of the policy and thus aim to generalize a characterization of agents' behaviour. In this study, we have instead developed a method to imbue a characteristic behaviour into agents' policies through regularization of their objective functions. Our method guides the agents' behaviour during learning which results in an intrinsic characterization; it connects the learning process with model explanation. We provide a formal argument and empirical evidence for the viability of our method. In future work, we intend to employ it to develop agents that optimize individual financial customers' investment portfolios based on their spending personalities.
Explainable AI : A Systematic Meta-Survey of Current Challenges and Future Opportunities
Nov 11, 2021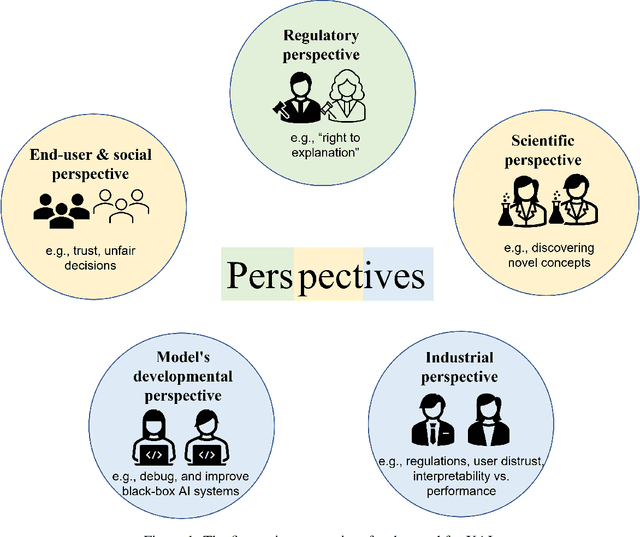
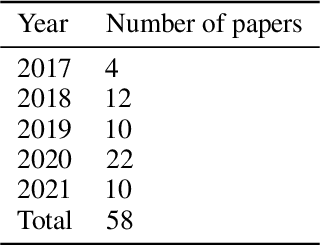
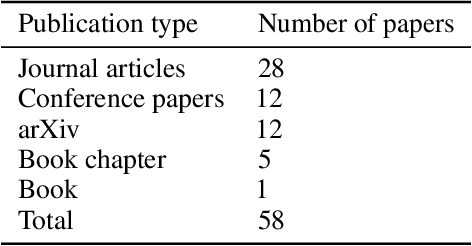
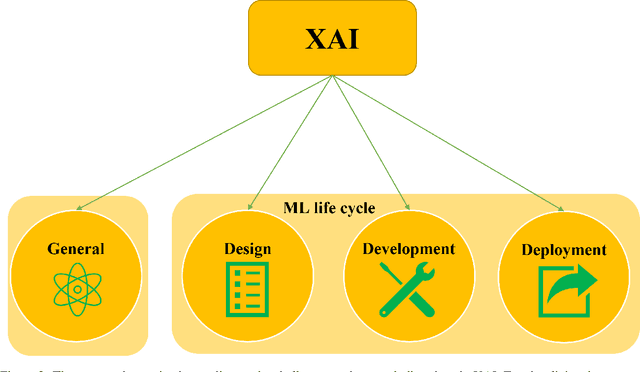
The past decade has seen significant progress in artificial intelligence (AI), which has resulted in algorithms being adopted for resolving a variety of problems. However, this success has been met by increasing model complexity and employing black-box AI models that lack transparency. In response to this need, Explainable AI (XAI) has been proposed to make AI more transparent and thus advance the adoption of AI in critical domains. Although there are several reviews of XAI topics in the literature that identified challenges and potential research directions in XAI, these challenges and research directions are scattered. This study, hence, presents a systematic meta-survey for challenges and future research directions in XAI organized in two themes: (1) general challenges and research directions in XAI and (2) challenges and research directions in XAI based on machine learning life cycle's phases: design, development, and deployment. We believe that our meta-survey contributes to XAI literature by providing a guide for future exploration in the XAI area.