 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Information Extraction without Token-Level Supervision
Jul 16, 2017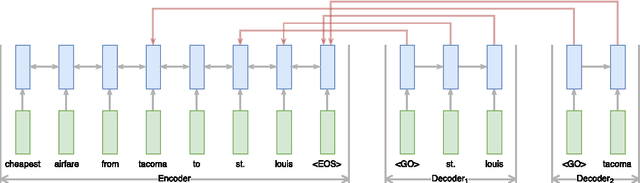
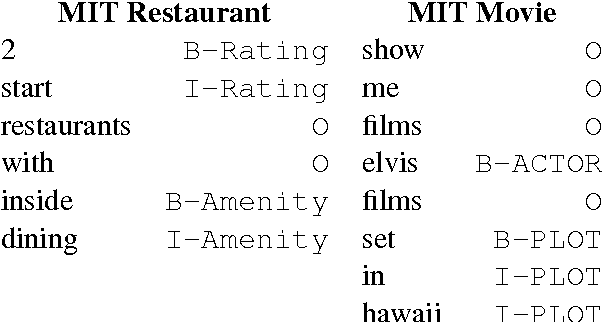

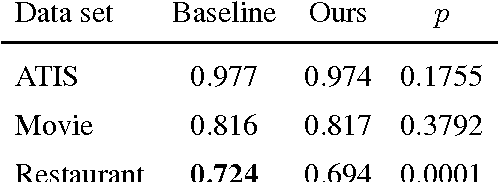
Most state-of-the-art information extraction approaches rely on token-level labels to find the areas of interest in text. Unfortunately, these labels are time-consuming and costly to create, and consequently, not available for many real-life IE tasks. To make matters worse, token-level labels are usually not the desired output, but just an intermediary step. End-to-end (E2E) models, which take raw text as input and produce the desired output directly, need not depend on token-level labels. We propose an E2E model based on pointer networks, which can be trained directly on pairs of raw input and output text. We evaluate our model on the ATIS data set, MIT restaurant corpus and the MIT movie corpus and compare to neural baselines that do use token-level labels. We achieve competitive results, within a few percentage points of the baselines, showing the feasibility of E2E information extraction without the need for token-level labels. This opens up new possibilities, as for many tasks currently addressed by human extractors, raw input and output data are available, but not token-level labels.
Semi-Supervised Generation with Cluster-aware Generative Models
Apr 03, 2017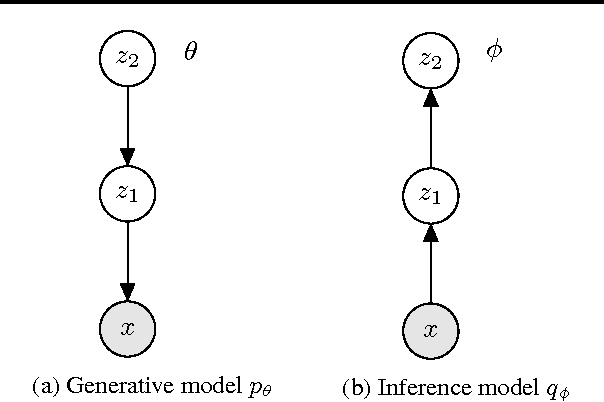
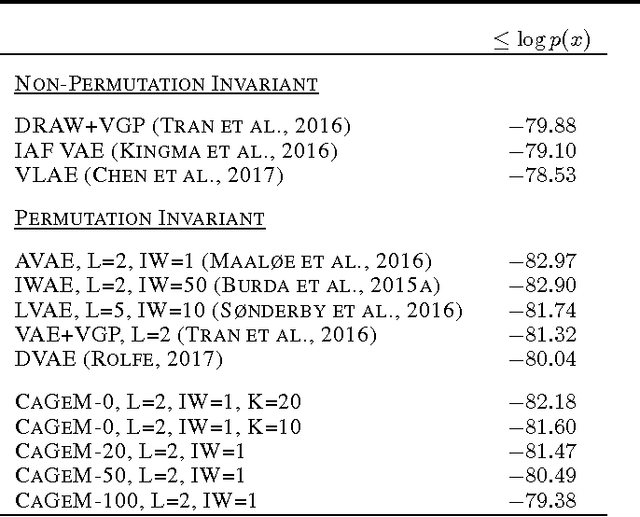
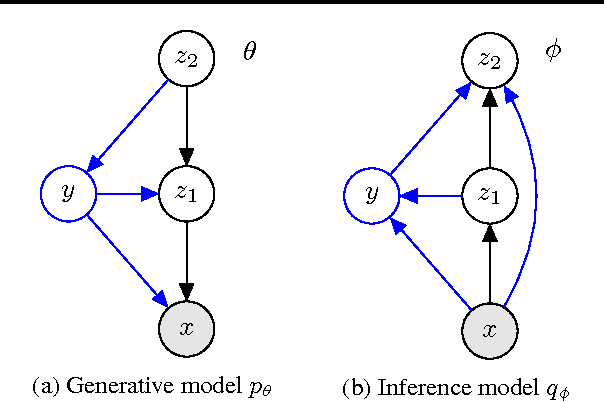

Deep generative models trained with large amounts of unlabelled data have proven to be powerful within the domain of unsupervised learning. Many real life data sets contain a small amount of labelled data points, that are typically disregarded when training generative models. We propose the Cluster-aware Generative Model, that uses unlabelled information to infer a latent representation that models the natural clustering of the data, and additional labelled data points to refine this clustering. The generative performances of the model significantly improve when labelled information is exploited, obtaining a log-likelihood of -79.38 nats on permutation invariant MNIST, while also achieving competitive semi-supervised classification accuracies. The model can also be trained fully unsupervised, and still improve the log-likelihood performance with respect to related methods.
Sequential Neural Models with Stochastic Layers
Nov 13, 2016
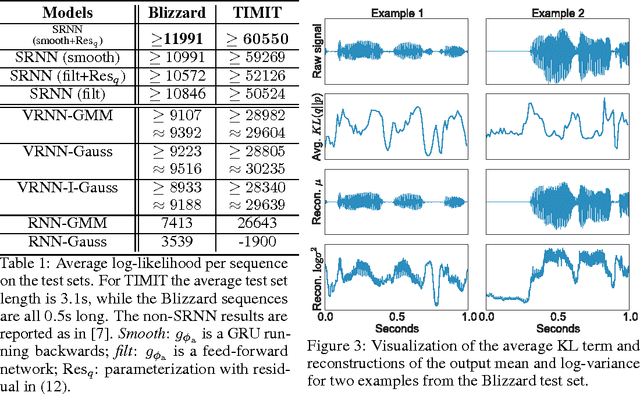
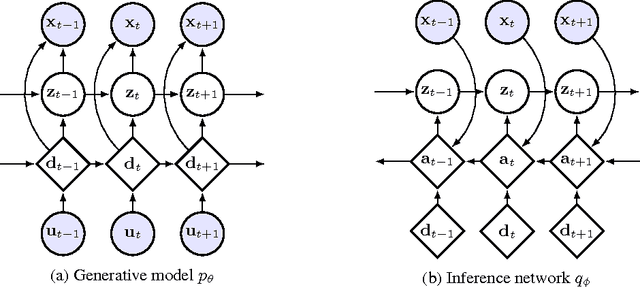

How can we efficiently propagate uncertainty in a latent state representation with recurrent neural networks? This paper introduces stochastic recurrent neural networks which glue a deterministic recurrent neural network and a state space model together to form a stochastic and sequential neural generative model. The clear separation of deterministic and stochastic layers allows a structured variational inference network to track the factorization of the model's posterior distribution. By retaining both the nonlinear recursive structure of a recurrent neural network and averaging over the uncertainty in a latent path, like a state space model, we improve the state of the art results on the Blizzard and TIMIT speech modeling data sets by a large margin, while achieving comparable performances to competing methods on polyphonic music modeling.
Neural Machine Translation with Characters and Hierarchical Encoding
Oct 20, 2016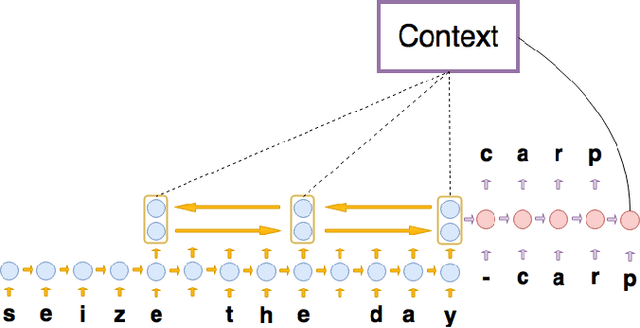
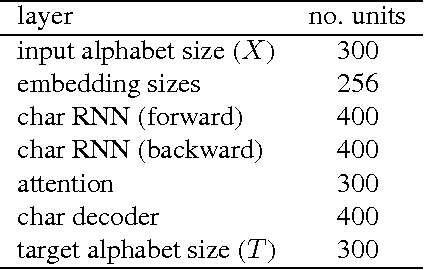
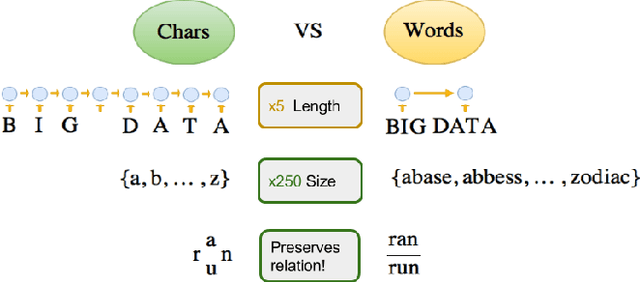
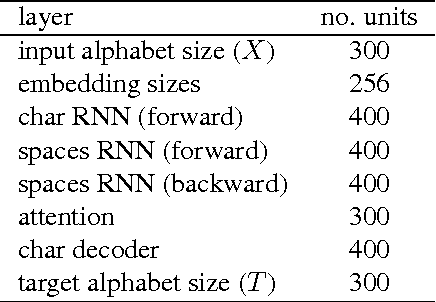
Most existing Neural Machine Translation models use groups of characters or whole words as their unit of input and output. We propose a model with a hierarchical char2word encoder, that takes individual characters both as input and output. We first argue that this hierarchical representation of the character encoder reduces computational complexity, and show that it improves translation performance. Secondly, by qualitatively studying attention plots from the decoder we find that the model learns to compress common words into a single embedding whereas rare words, such as names and places, are represented character by character.
Self-Averaging Expectation Propagation
Aug 23, 2016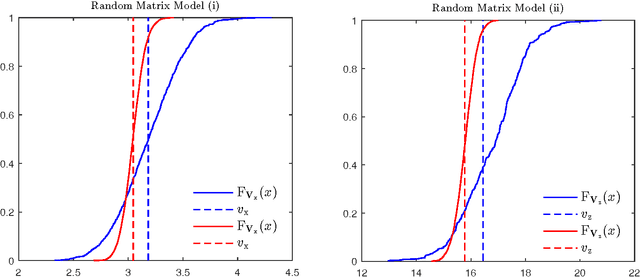
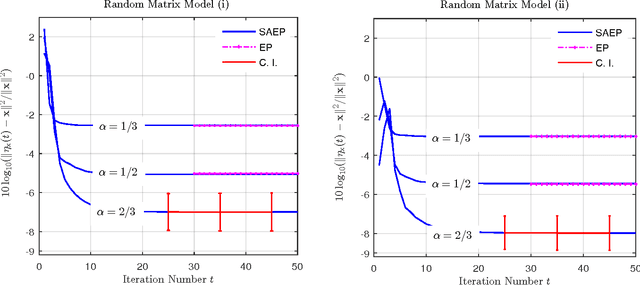
We investigate the problem of approximate Bayesian inference for a general class of observation models by means of the expectation propagation (EP) framework for large systems under some statistical assumptions. Our approach tries to overcome the numerical bottleneck of EP caused by the inversion of large matrices. Assuming that the measurement matrices are realizations of specific types of ensembles we use the concept of freeness from random matrix theory to show that the EP cavity variances exhibit an asymptotic self-averaging property. They can be pre-computed using specific generating functions, i.e. the R- and/or S-transforms in free probability, which do not require matrix inversions. Our approach extends the framework of (generalized) approximate message passing -- assumes zero-mean iid entries of the measurement matrix -- to a general class of random matrix ensembles. The generalization is via a simple formulation of the R- and/or S-transforms of the limiting eigenvalue distribution of the Gramian of the measurement matrix. We demonstrate the performance of our approach on a signal recovery problem of nonlinear compressed sensing and compare it with that of EP.
An Adaptive Resample-Move Algorithm for Estimating Normalizing Constants
Aug 15, 2016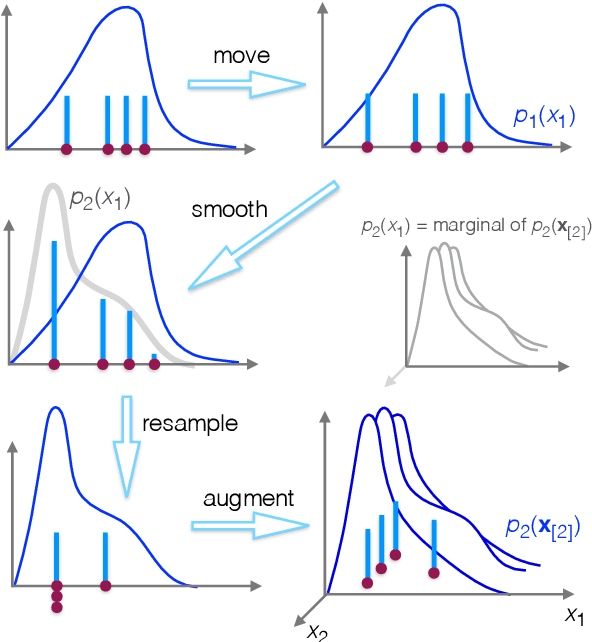
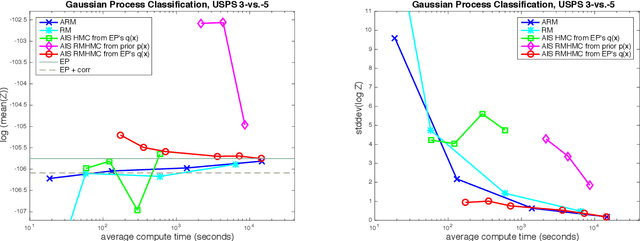
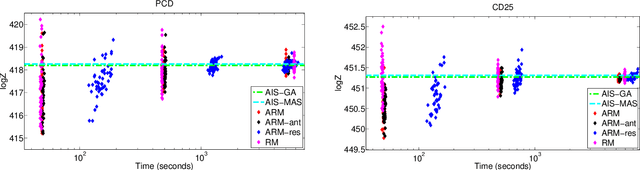
The estimation of normalizing constants is a fundamental step in probabilistic model comparison. Sequential Monte Carlo methods may be used for this task and have the advantage of being inherently parallelizable. However, the standard choice of using a fixed number of particles at each iteration is suboptimal because some steps will contribute disproportionately to the variance of the estimate. We introduce an adaptive version of the Resample-Move algorithm, in which the particle set is adaptively expanded whenever a better approximation of an intermediate distribution is needed. The algorithm builds on the expression for the optimal number of particles and the corresponding minimum variance found under ideal conditions. Benchmark results on challenging Gaussian Process Classification and Restricted Boltzmann Machine applications show that Adaptive Resample-Move (ARM) estimates the normalizing constant with a smaller variance, using less computational resources, than either Resample-Move with a fixed number of particles or Annealed Importance Sampling. A further advantage over Annealed Importance Sampling is that ARM is easier to tune.
Auxiliary Deep Generative Models
Jun 16, 2016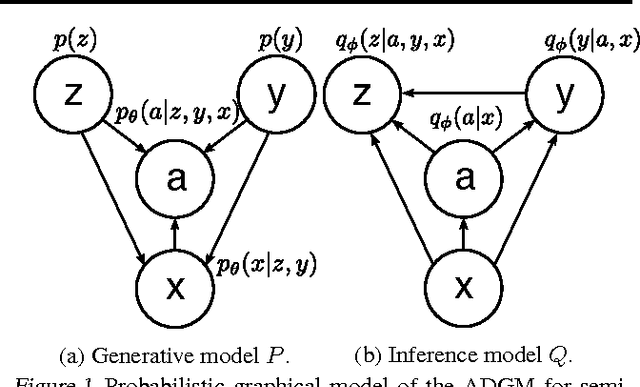
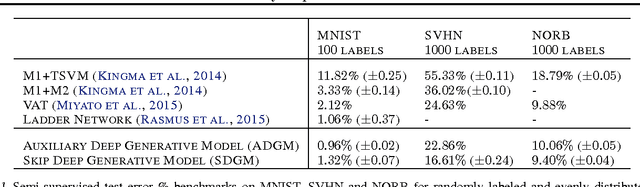
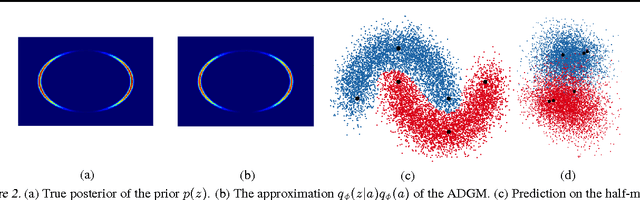

Deep generative models parameterized by neural networks have recently achieved state-of-the-art performance in unsupervised and semi-supervised learning. We extend deep generative models with auxiliary variables which improves the variational approximation. The auxiliary variables leave the generative model unchanged but make the variational distribution more expressive. Inspired by the structure of the auxiliary variable we also propose a model with two stochastic layers and skip connections. Our findings suggest that more expressive and properly specified deep generative models converge faster with better results. We show state-of-the-art performance within semi-supervised learning on MNIST, SVHN and NORB datasets.
Ladder Variational Autoencoders
May 27, 2016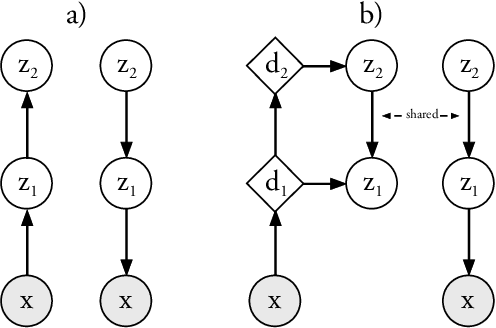

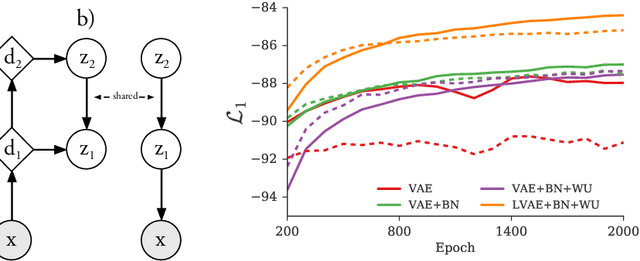
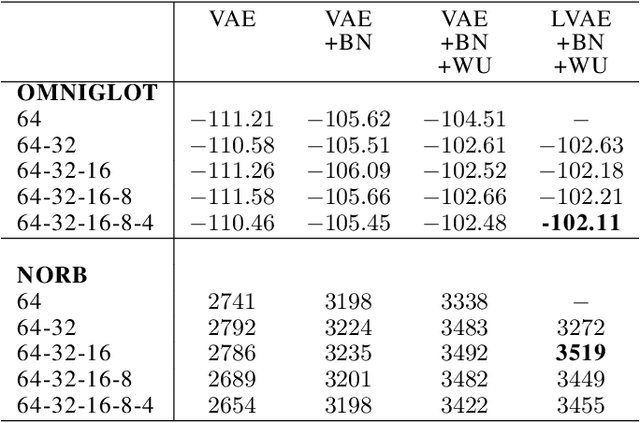
Variational Autoencoders are powerful models for unsupervised learning. However deep models with several layers of dependent stochastic variables are difficult to train which limits the improvements obtained using these highly expressive models. We propose a new inference model, the Ladder Variational Autoencoder, that recursively corrects the generative distribution by a data dependent approximate likelihood in a process resembling the recently proposed Ladder Network. We show that this model provides state of the art predictive log-likelihood and tighter log-likelihood lower bound compared to the purely bottom-up inference in layered Variational Autoencoders and other generative models. We provide a detailed analysis of the learned hierarchical latent representation and show that our new inference model is qualitatively different and utilizes a deeper more distributed hierarchy of latent variables. Finally, we observe that batch normalization and deterministic warm-up (gradually turning on the KL-term) are crucial for training variational models with many stochastic layers.
Bayesian leave-one-out cross-validation approximations for Gaussian latent variable models
May 23, 2016
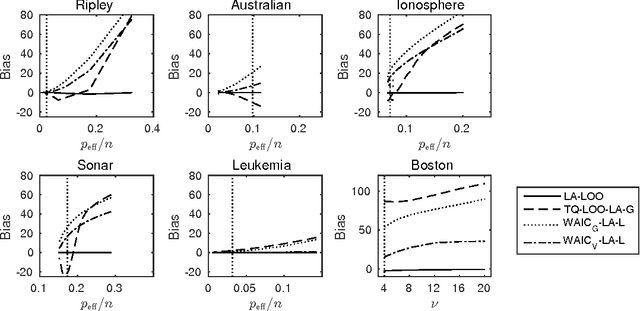

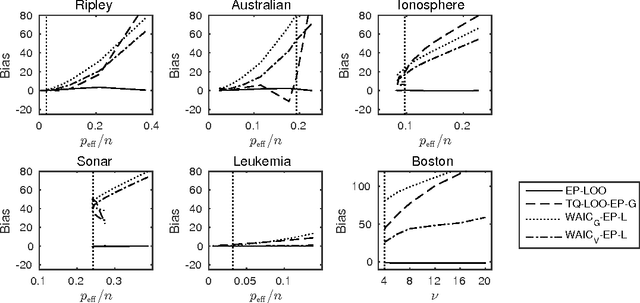
The future predictive performance of a Bayesian model can be estimated using Bayesian cross-validation. In this article, we consider Gaussian latent variable models where the integration over the latent values is approximated using the Laplace method or expectation propagation (EP). We study the properties of several Bayesian leave-one-out (LOO) cross-validation approximations that in most cases can be computed with a small additional cost after forming the posterior approximation given the full data. Our main objective is to assess the accuracy of the approximative LOO cross-validation estimators. That is, for each method (Laplace and EP) we compare the approximate fast computation with the exact brute force LOO computation. Secondarily, we evaluate the accuracy of the Laplace and EP approximations themselves against a ground truth established through extensive Markov chain Monte Carlo simulation. Our empirical results show that the approach based upon a Gaussian approximation to the LOO marginal distribution (the so-called cavity distribution) gives the most accurate and reliable results among the fast methods.
Autoencoding beyond pixels using a learned similarity metric
Feb 10, 2016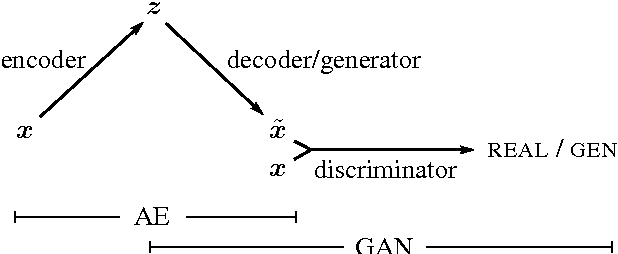

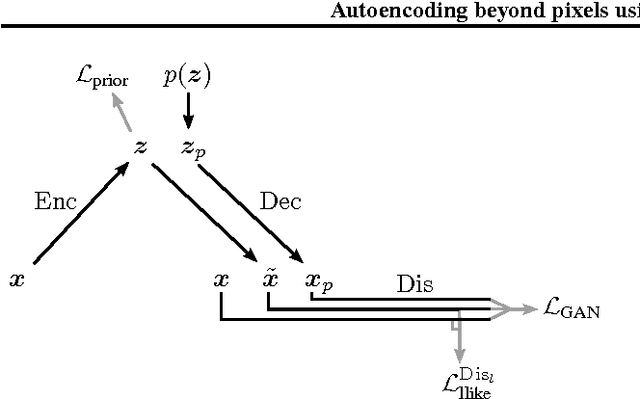

We present an autoencoder that leverages learned representations to better measure similarities in data space. By combining a variational autoencoder with a generative adversarial network we can use learned feature representations in the GAN discriminator as basis for the VAE reconstruction objective. Thereby, we replace element-wise errors with feature-wise errors to better capture the data distribution while offering invariance towards e.g. translation. We apply our method to images of faces and show that it outperforms VAEs with element-wise similarity measures in terms of visual fidelity. Moreover, we show that the method learns an embedding in which high-level abstract visual features (e.g. wearing glasses) can be modified using simple arithmetic.