 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial Implicit Neural Representations for Global-Scale Species Mapping
Jun 05, 2023



Estimating the geographical range of a species from sparse observations is a challenging and important geospatial prediction problem. Given a set of locations where a species has been observed, the goal is to build a model to predict whether the species is present or absent at any location. This problem has a long history in ecology, but traditional methods struggle to take advantage of emerging large-scale crowdsourced datasets which can include tens of millions of records for hundreds of thousands of species. In this work, we use Spatial Implicit Neural Representations (SINRs) to jointly estimate the geographical range of 47k species simultaneously. We find that our approach scales gracefully, making increasingly better predictions as we increase the number of species and the amount of data per species when training. To make this problem accessible to machine learning researchers, we provide four new benchmarks that measure different aspects of species range estimation and spatial representation learning. Using these benchmarks, we demonstrate that noisy and biased crowdsourced data can be combined with implicit neural representations to approximate expert-developed range maps for many species.
VL-Fields: Towards Language-Grounded Neural Implicit Spatial Representations
May 25, 2023



We present Visual-Language Fields (VL-Fields), a neural implicit spatial representation that enables open-vocabulary semantic queries. Our model encodes and fuses the geometry of a scene with vision-language trained latent features by distilling information from a language-driven segmentation model. VL-Fields is trained without requiring any prior knowledge of the scene object classes, which makes it a promising representation for the field of robotics. Our model outperformed the similar CLIP-Fields model in the task of semantic segmentation by almost 10%.
Virtual Occlusions Through Implicit Depth
May 11, 2023



For augmented reality (AR), it is important that virtual assets appear to `sit among' real world objects. The virtual element should variously occlude and be occluded by real matter, based on a plausible depth ordering. This occlusion should be consistent over time as the viewer's camera moves. Unfortunately, small mistakes in the estimated scene depth can ruin the downstream occlusion mask, and thereby the AR illusion. Especially in real-time settings, depths inferred near boundaries or across time can be inconsistent. In this paper, we challenge the need for depth-regression as an intermediate step. We instead propose an implicit model for depth and use that to predict the occlusion mask directly. The inputs to our network are one or more color images, plus the known depths of any virtual geometry. We show how our occlusion predictions are more accurate and more temporally stable than predictions derived from traditional depth-estimation models. We obtain state-of-the-art occlusion results on the challenging ScanNetv2 dataset and superior qualitative results on real scenes.
Incremental Generalized Category Discovery
Apr 27, 2023We explore the problem of Incremental Generalized Category Discovery (IGCD). This is a challenging category incremental learning setting where the goal is to develop models that can correctly categorize images from previously seen categories, in addition to discovering novel ones. Learning is performed over a series of time steps where the model obtains new labeled and unlabeled data, and discards old data, at each iteration. The difficulty of the problem is compounded in our generalized setting as the unlabeled data can contain images from categories that may or may not have been observed before. We present a new method for IGCD which combines non-parametric categorization with efficient image sampling to mitigate catastrophic forgetting. To quantify performance, we propose a new benchmark dataset named iNatIGCD that is motivated by a real-world fine-grained visual categorization task. In our experiments we outperform existing related methods
Self-Supervised Multimodal Learning: A Survey
Mar 31, 2023Multimodal learning, which aims to understand and analyze information from multiple modalities, has achieved substantial progress in the supervised regime in recent years. However, the heavy dependence on data paired with expensive human annotations impedes scaling up models. Meanwhile, given the availability of large-scale unannotated data in the wild, self-supervised learning has become an attractive strategy to alleviate the annotation bottleneck. Building on these two directions, self-supervised multimodal learning (SSML) provides ways to leverage supervision from raw multimodal data. In this survey, we provide a comprehensive review of the state-of-the-art in SSML, which we categorize along three orthogonal axes: objective functions, data alignment, and model architectures. These axes correspond to the inherent characteristics of self-supervised learning methods and multimodal data. Specifically, we classify training objectives into instance discrimination, clustering, and masked prediction categories. We also discuss multimodal input data pairing and alignment strategies during training. Finally, we review model architectures including the design of encoders, fusion modules, and decoders, which are essential components of SSML methods. We review downstream multimodal application tasks, reporting the concrete performance of the state-of-the-art image-text models and multimodal video models, and also review real-world applications of SSML algorithms in diverse fields such as healthcare, remote sensing, and machine translation. Finally, we discuss challenges and future directions for SSML. A collection of related resources can be found at: https://github.com/ys-zong/awesome-self-supervised-multimodal-learning.
SAOR: Single-View Articulated Object Reconstruction
Mar 23, 2023We introduce SAOR, a novel approach for estimating the 3D shape, texture, and viewpoint of an articulated object from a single image captured in the wild. Unlike prior approaches that rely on pre-defined category-specific 3D templates or tailored 3D skeletons, SAOR learns to articulate shapes from single-view image collections with a skeleton-free part-based model without requiring any 3D object shape priors. To prevent ill-posed solutions, we propose a cross-instance consistency loss that exploits disentangled object shape deformation and articulation. This is helped by a new silhouette-based sampling mechanism to enhance viewpoint diversity during training. Our method only requires estimated object silhouettes and relative depth maps from off-the-shelf pre-trained networks during training. At inference time, given a single-view image, it efficiently outputs an explicit mesh representation. We obtain improved qualitative and quantitative results on challenging quadruped animals compared to relevant existing work.
ViewNeRF: Unsupervised Viewpoint Estimation Using Category-Level Neural Radiance Fields
Dec 01, 2022We introduce ViewNeRF, a Neural Radiance Field-based viewpoint estimation method that learns to predict category-level viewpoints directly from images during training. While NeRF is usually trained with ground-truth camera poses, multiple extensions have been proposed to reduce the need for this expensive supervision. Nonetheless, most of these methods still struggle in complex settings with large camera movements, and are restricted to single scenes, i.e. they cannot be trained on a collection of scenes depicting the same object category. To address these issues, our method uses an analysis by synthesis approach, combining a conditional NeRF with a viewpoint predictor and a scene encoder in order to produce self-supervised reconstructions for whole object categories. Rather than focusing on high fidelity reconstruction, we target efficient and accurate viewpoint prediction in complex scenarios, e.g. 360{\deg} rotation on real data. Our model shows competitive results on synthetic and real datasets, both for single scenes and multi-instance collections.
ViewNet: Unsupervised Viewpoint Estimation from Conditional Generation
Dec 01, 2022



Understanding the 3D world without supervision is currently a major challenge in computer vision as the annotations required to supervise deep networks for tasks in this domain are expensive to obtain on a large scale. In this paper, we address the problem of unsupervised viewpoint estimation. We formulate this as a self-supervised learning task, where image reconstruction provides the supervision needed to predict the camera viewpoint. Specifically, we make use of pairs of images of the same object at training time, from unknown viewpoints, to self-supervise training by combining the viewpoint information from one image with the appearance information from the other. We demonstrate that using a perspective spatial transformer allows efficient viewpoint learning, outperforming existing unsupervised approaches on synthetic data, and obtains competitive results on the challenging PASCAL3D+ dataset.
An Action Is Worth Multiple Words: Handling Ambiguity in Action Recognition
Oct 10, 2022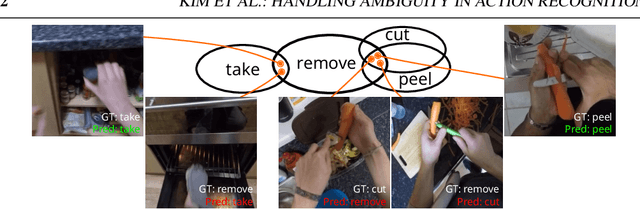
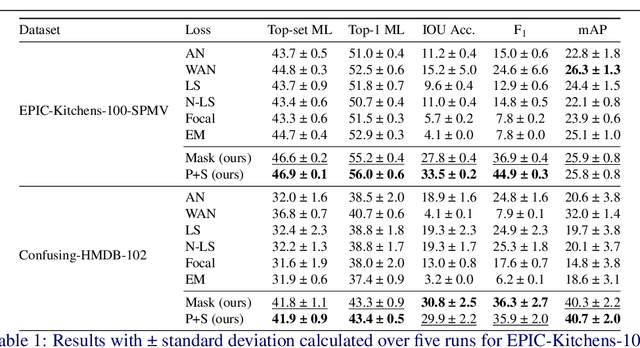
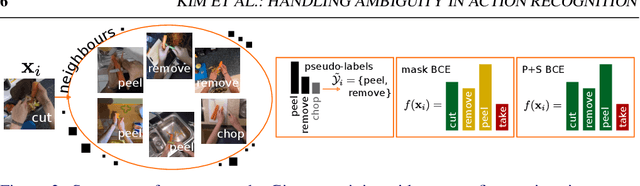
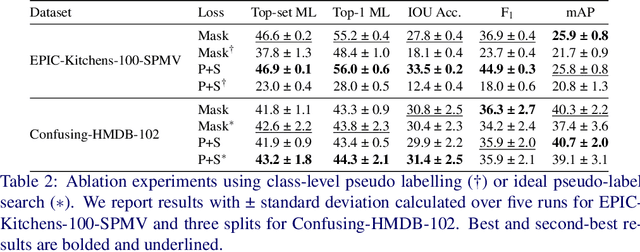
Precisely naming the action depicted in a video can be a challenging and oftentimes ambiguous task. In contrast to object instances represented as nouns (e.g. dog, cat, chair, etc.), in the case of actions, human annotators typically lack a consensus as to what constitutes a specific action (e.g. jogging versus running). In practice, a given video can contain multiple valid positive annotations for the same action. As a result, video datasets often contain significant levels of label noise and overlap between the atomic action classes. In this work, we address the challenge of training multi-label action recognition models from only single positive training labels. We propose two approaches that are based on generating pseudo training examples sampled from similar instances within the train set. Unlike other approaches that use model-derived pseudo-labels, our pseudo-labels come from human annotations and are selected based on feature similarity. To validate our approaches, we create a new evaluation benchmark by manually annotating a subset of EPIC-Kitchens-100's validation set with multiple verb labels. We present results on this new test set along with additional results on a new version of HMDB-51, called Confusing-HMDB-102, where we outperform existing methods in both cases. Data and code are available at https://github.com/kiyoon/verb_ambiguity
SVL-Adapter: Self-Supervised Adapter for Vision-Language Pretrained Models
Oct 07, 2022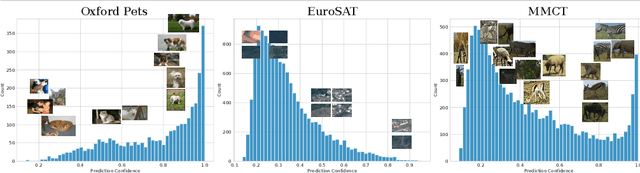
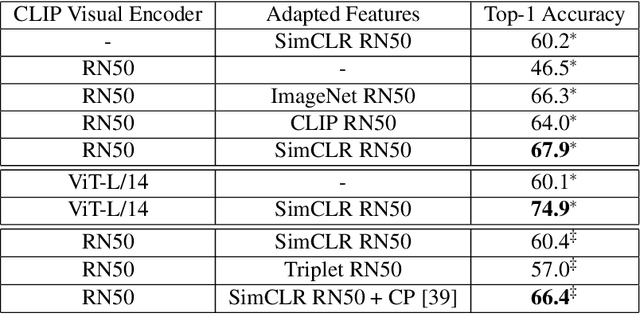
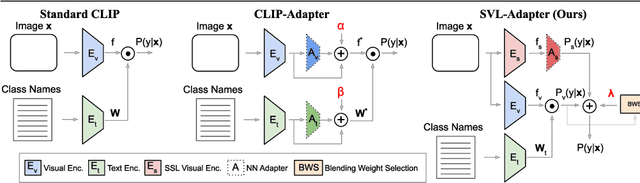
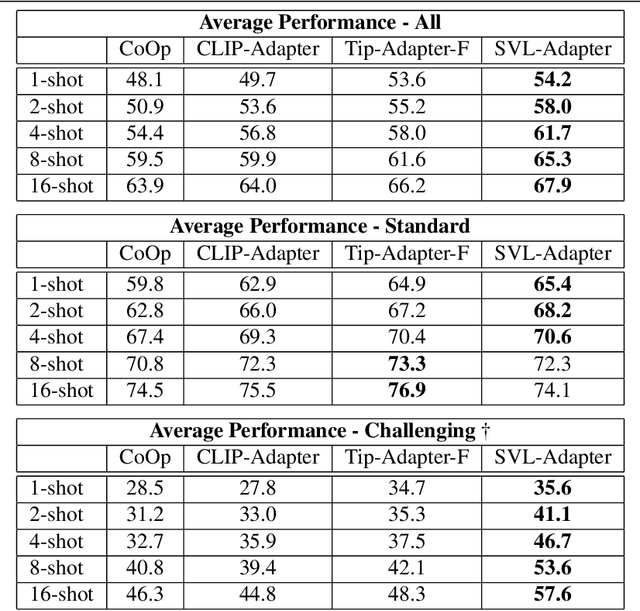
Vision-language models such as CLIP are pretrained on large volumes of internet sourced image and text pairs, and have been shown to sometimes exhibit impressive zero- and low-shot image classification performance. However, due to their size, fine-tuning these models on new datasets can be prohibitively expensive, both in terms of the supervision and compute required. To combat this, a series of light-weight adaptation methods have been proposed to efficiently adapt such models when limited supervision is available. In this work, we show that while effective on internet-style datasets, even those remedies under-deliver on classification tasks with images that differ significantly from those commonly found online. To address this issue, we present a new approach called SVL-Adapter that combines the complementary strengths of both vision-language pretraining and self-supervised representation learning. We report an average classification accuracy improvement of 10% in the low-shot setting when compared to existing methods, on a set of challenging visual classification tasks. Further, we present a fully automatic way of selecting an important blending hyperparameter for our model that does not require any held-out labeled validation data. Code for our project is available here: https://github.com/omipan/svl_adapter.