 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistribution-Specific Hardness of Learning Neural Networks
Mar 09, 2017
Although neural networks are routinely and successfully trained in practice using simple gradient-based methods, most existing theoretical results are negative, showing that learning such networks is difficult, in a worst-case sense over all data distributions. In this paper, we take a more nuanced view, and consider whether specific assumptions on the "niceness" of the input distribution, or "niceness" of the target function (e.g. in terms of smoothness, non-degeneracy, incoherence, random choice of parameters etc.), are sufficient to guarantee learnability using gradient-based methods. We provide evidence that neither class of assumptions alone is sufficient: On the one hand, for any member of a class of "nice" target functions, there are difficult input distributions. On the other hand, we identify a family of simple target functions, which are difficult to learn even if the input distribution is "nice". To prove our results, we develop some tools which may be of independent interest, such as extending Fourier-based hardness techniques developed in the context of statistical queries \cite{blum1994weakly}, from the Boolean cube to Euclidean space and to more general classes of functions.
Oracle Complexity of Second-Order Methods for Finite-Sum Problems
Mar 08, 2017Finite-sum optimization problems are ubiquitous in machine learning, and are commonly solved using first-order methods which rely on gradient computations. Recently, there has been growing interest in \emph{second-order} methods, which rely on both gradients and Hessians. In principle, second-order methods can require much fewer iterations than first-order methods, and hold the promise for more efficient algorithms. Although computing and manipulating Hessians is prohibitive for high-dimensional problems in general, the Hessians of individual functions in finite-sum problems can often be efficiently computed, e.g. because they possess a low-rank structure. Can second-order information indeed be used to solve such problems more efficiently? In this paper, we provide evidence that the answer -- perhaps surprisingly -- is negative, at least in terms of worst-case guarantees. However, we also discuss what additional assumptions and algorithmic approaches might potentially circumvent this negative result.
Communication-efficient Algorithms for Distributed Stochastic Principal Component Analysis
Feb 27, 2017
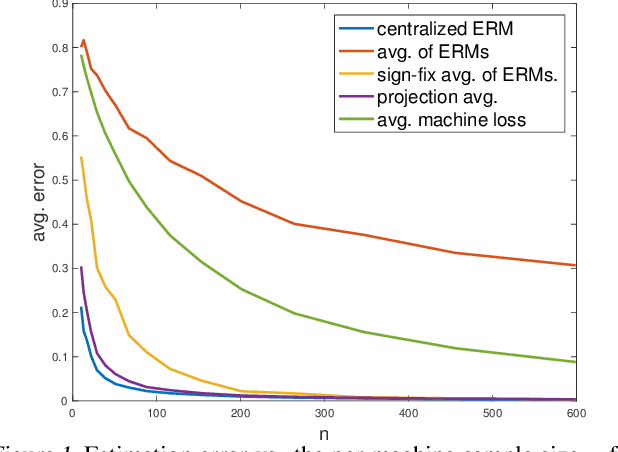
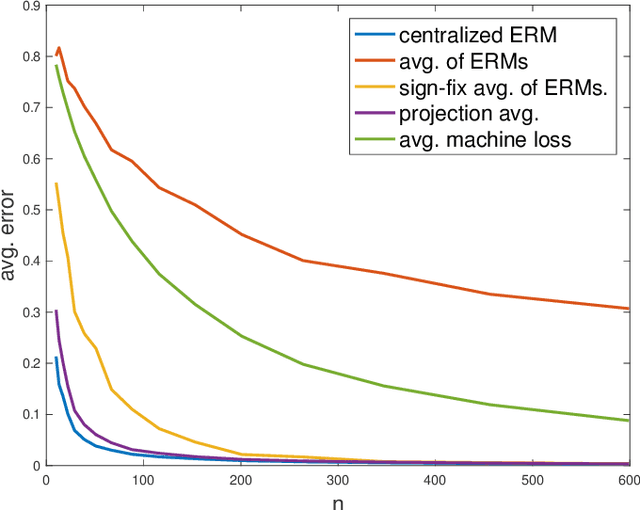
We study the fundamental problem of Principal Component Analysis in a statistical distributed setting in which each machine out of $m$ stores a sample of $n$ points sampled i.i.d. from a single unknown distribution. We study algorithms for estimating the leading principal component of the population covariance matrix that are both communication-efficient and achieve estimation error of the order of the centralized ERM solution that uses all $mn$ samples. On the negative side, we show that in contrast to results obtained for distributed estimation under convexity assumptions, for the PCA objective, simply averaging the local ERM solutions cannot guarantee error that is consistent with the centralized ERM. We show that this unfortunate phenomena can be remedied by performing a simple correction step which correlates between the individual solutions, and provides an estimator that is consistent with the centralized ERM for sufficiently-large $n$. We also introduce an iterative distributed algorithm that is applicable in any regime of $n$, which is based on distributed matrix-vector products. The algorithm gives significant acceleration in terms of communication rounds over previous distributed algorithms, in a wide regime of parameters.
Without-Replacement Sampling for Stochastic Gradient Methods: Convergence Results and Application to Distributed Optimization
Oct 17, 2016Stochastic gradient methods for machine learning and optimization problems are usually analyzed assuming data points are sampled \emph{with} replacement. In practice, however, sampling \emph{without} replacement is very common, easier to implement in many cases, and often performs better. In this paper, we provide competitive convergence guarantees for without-replacement sampling, under various scenarios, for three types of algorithms: Any algorithm with online regret guarantees, stochastic gradient descent, and SVRG. A useful application of our SVRG analysis is a nearly-optimal algorithm for regularized least squares in a distributed setting, in terms of both communication complexity and runtime complexity, when the data is randomly partitioned and the condition number can be as large as the data size per machine (up to logarithmic factors). Our proof techniques combine ideas from stochastic optimization, adversarial online learning, and transductive learning theory, and can potentially be applied to other stochastic optimization and learning problems.
Dimension-Free Iteration Complexity of Finite Sum Optimization Problems
Jun 30, 2016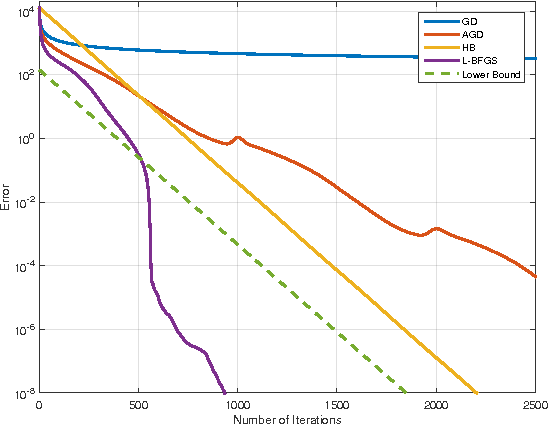
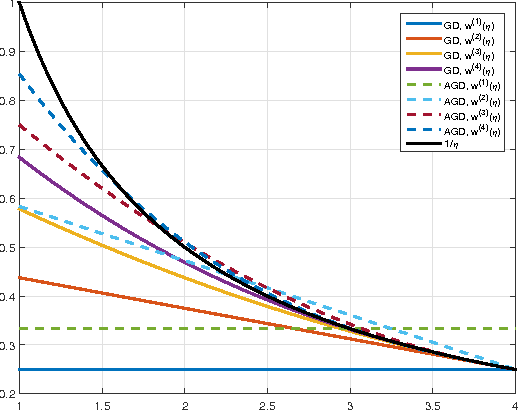
Many canonical machine learning problems boil down to a convex optimization problem with a finite sum structure. However, whereas much progress has been made in developing faster algorithms for this setting, the inherent limitations of these problems are not satisfactorily addressed by existing lower bounds. Indeed, current bounds focus on first-order optimization algorithms, and only apply in the often unrealistic regime where the number of iterations is less than $\mathcal{O}(d/n)$ (where $d$ is the dimension and $n$ is the number of samples). In this work, we extend the framework of (Arjevani et al., 2015) to provide new lower bounds, which are dimension-free, and go beyond the assumptions of current bounds, thereby covering standard finite sum optimization methods, e.g., SAG, SAGA, SVRG, SDCA without duality, as well as stochastic coordinate-descent methods, such as SDCA and accelerated proximal SDCA.
On the Quality of the Initial Basin in Overspecified Neural Networks
Jun 14, 2016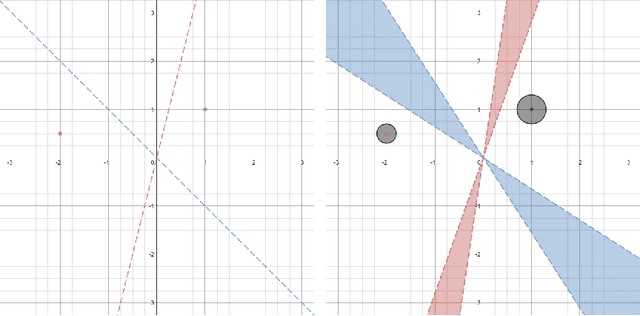
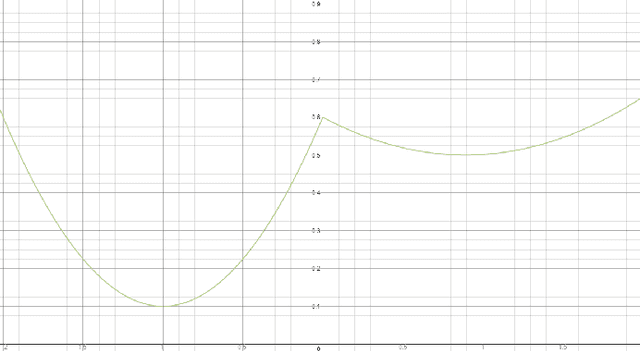
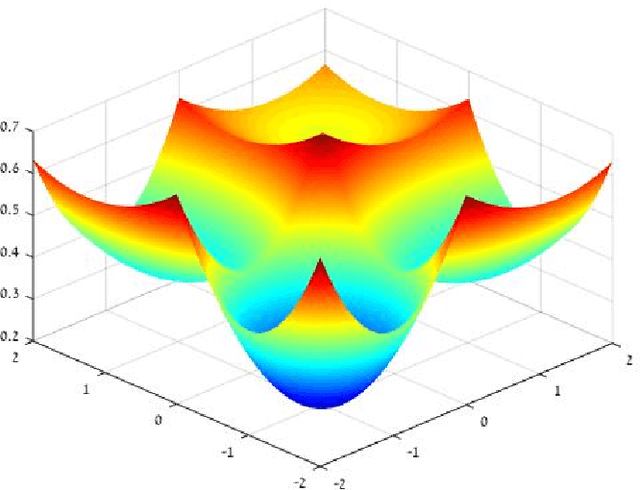
Deep learning, in the form of artificial neural networks, has achieved remarkable practical success in recent years, for a variety of difficult machine learning applications. However, a theoretical explanation for this remains a major open problem, since training neural networks involves optimizing a highly non-convex objective function, and is known to be computationally hard in the worst case. In this work, we study the \emph{geometric} structure of the associated non-convex objective function, in the context of ReLU networks and starting from a random initialization of the network parameters. We identify some conditions under which it becomes more favorable to optimization, in the sense of (i) High probability of initializing at a point from which there is a monotonically decreasing path to a global minimum; and (ii) High probability of initializing at a basin (suitably defined) with a small minimal objective value. A common theme in our results is that such properties are more likely to hold for larger ("overspecified") networks, which accords with some recent empirical and theoretical observations.
On the Iteration Complexity of Oblivious First-Order Optimization Algorithms
May 11, 2016We consider a broad class of first-order optimization algorithms which are \emph{oblivious}, in the sense that their step sizes are scheduled regardless of the function under consideration, except for limited side-information such as smoothness or strong convexity parameters. With the knowledge of these two parameters, we show that any such algorithm attains an iteration complexity lower bound of $\Omega(\sqrt{L/\epsilon})$ for $L$-smooth convex functions, and $\tilde{\Omega}(\sqrt{L/\mu}\ln(1/\epsilon))$ for $L$-smooth $\mu$-strongly convex functions. These lower bounds are stronger than those in the traditional oracle model, as they hold independently of the dimension. To attain these, we abandon the oracle model in favor of a structure-based approach which builds upon a framework recently proposed in (Arjevani et al., 2015). We further show that without knowing the strong convexity parameter, it is impossible to attain an iteration complexity better than $\tilde{\Omega}\left((L/\mu)\ln(1/\epsilon)\right)$. This result is then used to formalize an observation regarding $L$-smooth convex functions, namely, that the iteration complexity of algorithms employing time-invariant step sizes must be at least $\Omega(L/\epsilon)$.
The Power of Depth for Feedforward Neural Networks
May 09, 2016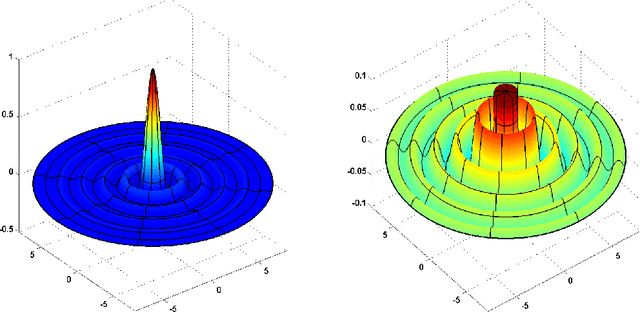
We show that there is a simple (approximately radial) function on $\reals^d$, expressible by a small 3-layer feedforward neural networks, which cannot be approximated by any 2-layer network, to more than a certain constant accuracy, unless its width is exponential in the dimension. The result holds for virtually all known activation functions, including rectified linear units, sigmoids and thresholds, and formally demonstrates that depth -- even if increased by 1 -- can be exponentially more valuable than width for standard feedforward neural networks. Moreover, compared to related results in the context of Boolean functions, our result requires fewer assumptions, and the proof techniques and construction are very different.
Convergence of Stochastic Gradient Descent for PCA
Jan 04, 2016We consider the problem of principal component analysis (PCA) in a streaming stochastic setting, where our goal is to find a direction of approximate maximal variance, based on a stream of i.i.d. data points in $\reals^d$. A simple and computationally cheap algorithm for this is stochastic gradient descent (SGD), which incrementally updates its estimate based on each new data point. However, due to the non-convex nature of the problem, analyzing its performance has been a challenge. In particular, existing guarantees rely on a non-trivial eigengap assumption on the covariance matrix, which is intuitively unnecessary. In this paper, we provide (to the best of our knowledge) the first eigengap-free convergence guarantees for SGD in the context of PCA. This also partially resolves an open problem posed in \cite{hardt2014noisy}. Moreover, under an eigengap assumption, we show that the same techniques lead to new SGD convergence guarantees with better dependence on the eigengap.
Multi-Player Bandits -- a Musical Chairs Approach
Dec 09, 2015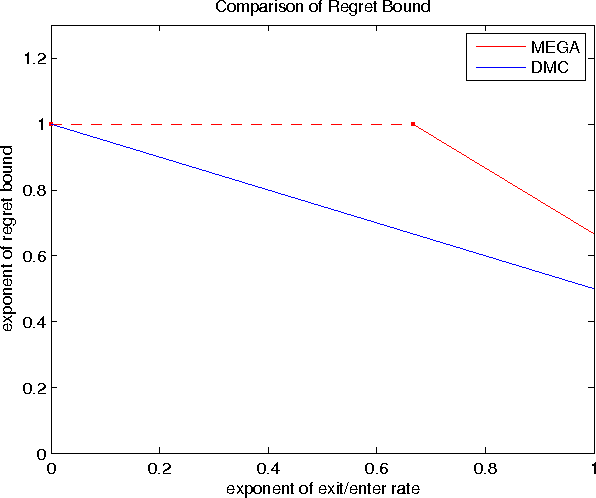

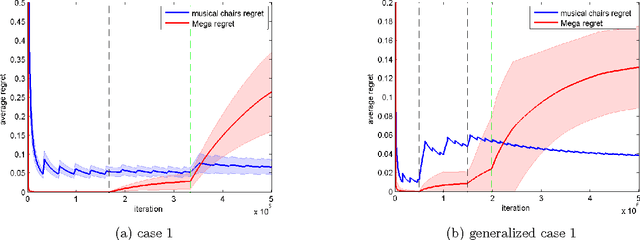
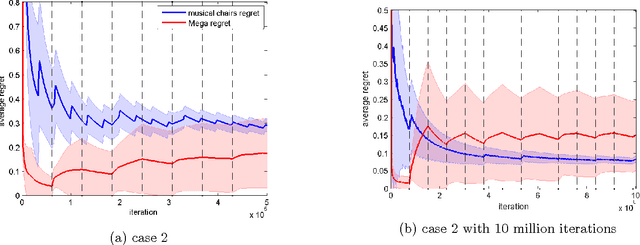
We consider a variant of the stochastic multi-armed bandit problem, where multiple players simultaneously choose from the same set of arms and may collide, receiving no reward. This setting has been motivated by problems arising in cognitive radio networks, and is especially challenging under the realistic assumption that communication between players is limited. We provide a communication-free algorithm (Musical Chairs) which attains constant regret with high probability, as well as a sublinear-regret, communication-free algorithm (Dynamic Musical Chairs) for the more difficult setting of players dynamically entering and leaving throughout the game. Moreover, both algorithms do not require prior knowledge of the number of players. To the best of our knowledge, these are the first communication-free algorithms with these types of formal guarantees. We also rigorously compare our algorithms to previous works, and complement our theoretical findings with experiments.