 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Rate of Convergence of GD in Non-linear Neural Networks: An Adversarial Robustness Perspective
Mar 02, 2026We study the convergence dynamics of Gradient Descent (GD) in a minimal binary classification setting, consisting of a two-neuron ReLU network and two training instances. We prove that even under these strong simplifying assumptions, while GD successfully converges to an optimal robustness margin, effectively maximizing the distance between the decision boundary and the training points, this convergence occurs at a prohibitively slow rate, scaling strictly as $Θ(1/\ln(t))$. To the best of our knowledge, this establishes the first explicit lower bound on the convergence rate of the robustness margin in a non-linear model. Through empirical simulations, we further demonstrate that this inherent failure mode is pervasive, exhibiting the exact same tight convergence rate across multiple natural network initializations. Our theoretical guarantees are derived via a rigorous analysis of the GD trajectories across the distinct activation patterns of the model. Specifically, we develop tight control over the system's dynamics to bound the trajectory of the decision boundary, overcoming the primary technical challenge introduced by the non-linear nature of the architecture.
The Median is Easier than it Looks: Approximation with a Constant-Depth, Linear-Width ReLU Network
Feb 06, 2026We study the approximation of the median of $d$ inputs using ReLU neural networks. We present depth-width tradeoffs under several settings, culminating in a constant-depth, linear-width construction that achieves exponentially small approximation error with respect to the uniform distribution over the unit hypercube. By further establishing a general reduction from the maximum to the median, our results break a barrier suggested by prior work on the maximum function, which indicated that linear width should require depth growing at least as $\log\log d$ to achieve comparable accuracy. Our construction relies on a multi-stage procedure that iteratively eliminates non-central elements while preserving a candidate set around the median. We overcome obstacles that do not arise for the maximum to yield approximation results that are strictly stronger than those previously known for the maximum itself.
To Grok Grokking: Provable Grokking in Ridge Regression
Jan 27, 2026We study grokking, the onset of generalization long after overfitting, in a classical ridge regression setting. We prove end-to-end grokking results for learning over-parameterized linear regression models using gradient descent with weight decay. Specifically, we prove that the following stages occur: (i) the model overfits the training data early during training; (ii) poor generalization persists long after overfitting has manifested; and (iii) the generalization error eventually becomes arbitrarily small. Moreover, we show, both theoretically and empirically, that grokking can be amplified or eliminated in a principled manner through proper hyperparameter tuning. To the best of our knowledge, these are the first rigorous quantitative bounds on the generalization delay (which we refer to as the "grokking time") in terms of training hyperparameters. Lastly, going beyond the linear setting, we empirically demonstrate that our quantitative bounds also capture the behavior of grokking on non-linear neural networks. Our results suggest that grokking is not an inherent failure mode of deep learning, but rather a consequence of specific training conditions, and thus does not require fundamental changes to the model architecture or learning algorithm to avoid.
A Depth Hierarchy for Computing the Maximum in ReLU Networks via Extremal Graph Theory
Jan 04, 2026We consider the problem of exact computation of the maximum function over $d$ real inputs using ReLU neural networks. We prove a depth hierarchy, wherein width $Ω\big(d^{1+\frac{1}{2^{k-2}-1}}\big)$ is necessary to represent the maximum for any depth $3\le k\le \log_2(\log_2(d))$. This is the first unconditional super-linear lower bound for this fundamental operator at depths $k\ge3$, and it holds even if the depth scales with $d$. Our proof technique is based on a combinatorial argument and associates the non-differentiable ridges of the maximum with cliques in a graph induced by the first hidden layer of the computing network, utilizing Turán's theorem from extremal graph theory to show that a sufficiently narrow network cannot capture the non-linearities of the maximum. This suggests that despite its simple nature, the maximum function possesses an inherent complexity that stems from the geometric structure of its non-differentiable hyperplanes, and provides a novel approach for proving lower bounds for deep neural networks.
Provable Privacy Attacks on Trained Shallow Neural Networks
Oct 10, 2024We study what provable privacy attacks can be shown on trained, 2-layer ReLU neural networks. We explore two types of attacks; data reconstruction attacks, and membership inference attacks. We prove that theoretical results on the implicit bias of 2-layer neural networks can be used to provably reconstruct a set of which at least a constant fraction are training points in a univariate setting, and can also be used to identify with high probability whether a given point was used in the training set in a high dimensional setting. To the best of our knowledge, our work is the first to show provable vulnerabilities in this setting.
Depth Separations in Neural Networks: Separating the Dimension from the Accuracy
Feb 11, 2024We prove an exponential separation between depth 2 and depth 3 neural networks, when approximating an $\mathcal{O}(1)$-Lipschitz target function to constant accuracy, with respect to a distribution with support in $[0,1]^{d}$, assuming exponentially bounded weights. This addresses an open problem posed in \citet{safran2019depth}, and proves that the curse of dimensionality manifests in depth 2 approximation, even in cases where the target function can be represented efficiently using depth 3. Previously, lower bounds that were used to separate depth 2 from depth 3 required that at least one of the Lipschitz parameter, target accuracy or (some measure of) the size of the domain of approximation scale polynomially with the input dimension, whereas we fix the former two and restrict our domain to the unit hypercube. Our lower bound holds for a wide variety of activation functions, and is based on a novel application of an average- to worst-case random self-reducibility argument, to reduce the problem to threshold circuits lower bounds.
How Many Neurons Does it Take to Approximate the Maximum?
Jul 18, 2023


We study the size of a neural network needed to approximate the maximum function over $d$ inputs, in the most basic setting of approximating with respect to the $L_2$ norm, for continuous distributions, for a network that uses ReLU activations. We provide new lower and upper bounds on the width required for approximation across various depths. Our results establish new depth separations between depth 2 and 3, and depth 3 and 5 networks, as well as providing a depth $\mathcal{O}(\log(\log(d)))$ and width $\mathcal{O}(d)$ construction which approximates the maximum function, significantly improving upon the depth requirements of the best previously known bounds for networks with linearly-bounded width. Our depth separation results are facilitated by a new lower bound for depth 2 networks approximating the maximum function over the uniform distribution, assuming an exponential upper bound on the size of the weights. Furthermore, we are able to use this depth 2 lower bound to provide tight bounds on the number of neurons needed to approximate the maximum by a depth 3 network. Our lower bounds are of potentially broad interest as they apply to the widely studied and used \emph{max} function, in contrast to many previous results that base their bounds on specially constructed or pathological functions and distributions.
On the Effective Number of Linear Regions in Shallow Univariate ReLU Networks: Convergence Guarantees and Implicit Bias
May 18, 2022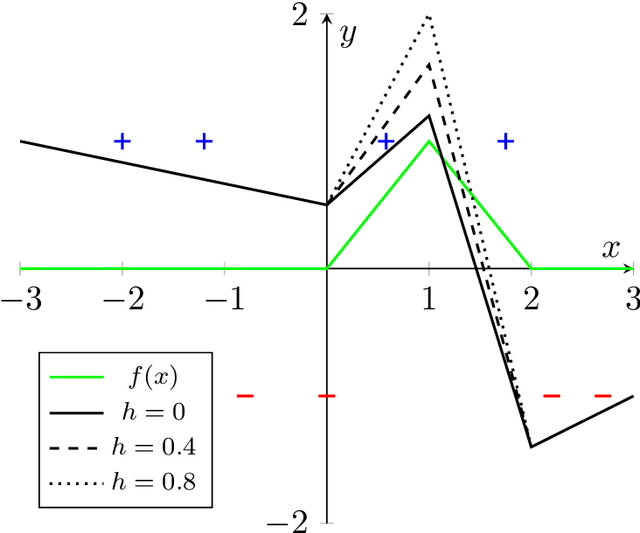
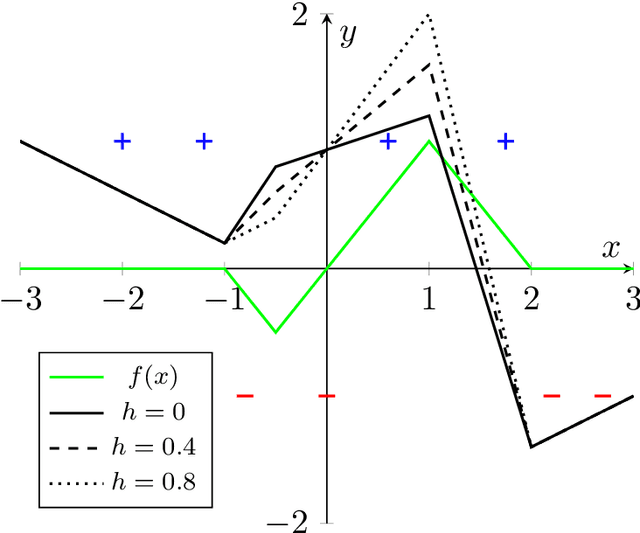
We study the dynamics and implicit bias of gradient flow (GF) on univariate ReLU neural networks with a single hidden layer in a binary classification setting. We show that when the labels are determined by the sign of a target network with $r$ neurons, with high probability over the initialization of the network and the sampling of the dataset, GF converges in direction (suitably defined) to a network achieving perfect training accuracy and having at most $\mathcal{O}(r)$ linear regions, implying a generalization bound. Our result may already hold for mild over-parameterization, where the width is $\tilde{\mathcal{O}}(r)$ and independent of the sample size.
Optimization-Based Separations for Neural Networks
Dec 04, 2021Depth separation results propose a possible theoretical explanation for the benefits of deep neural networks over shallower architectures, establishing that the former possess superior approximation capabilities. However, there are no known results in which the deeper architecture leverages this advantage into a provable optimization guarantee. We prove that when the data are generated by a distribution with radial symmetry which satisfies some mild assumptions, gradient descent can efficiently learn ball indicator functions using a depth 2 neural network with two layers of sigmoidal activations, and where the hidden layer is held fixed throughout training. Since it is known that ball indicators are hard to approximate with respect to a certain heavy-tailed distribution when using depth 2 networks with a single layer of non-linearities (Safran and Shamir, 2017), this establishes what is to the best of our knowledge, the first optimization-based separation result where the approximation benefits of the stronger architecture provably manifest in practice. Our proof technique relies on a random features approach which reduces the problem to learning with a single neuron, where new tools are required to show the convergence of gradient descent when the distribution of the data is heavy-tailed.
Random Shuffling Beats SGD Only After Many Epochs on Ill-Conditioned Problems
Jun 12, 2021
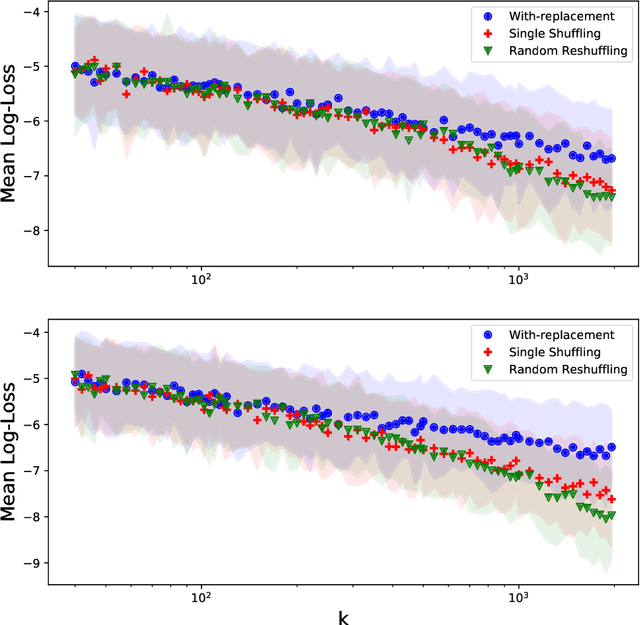
Recently, there has been much interest in studying the convergence rates of without-replacement SGD, and proving that it is faster than with-replacement SGD in the worst case. However, these works ignore or do not provide tight bounds in terms of the problem's geometry, including its condition number. Perhaps surprisingly, we prove that when the condition number is taken into account, without-replacement SGD \emph{does not} significantly improve on with-replacement SGD in terms of worst-case bounds, unless the number of epochs (passes over the data) is larger than the condition number. Since many problems in machine learning and other areas are both ill-conditioned and involve large datasets, this indicates that without-replacement does not necessarily improve over with-replacement sampling for realistic iteration budgets. We show this by providing new lower and upper bounds which are tight (up to log factors), for quadratic problems with commuting quadratic terms, precisely quantifying the dependence on the problem parameters.