 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization in Kernel Regression Under Realistic Assumptions
Dec 26, 2023It is by now well-established that modern over-parameterized models seem to elude the bias-variance tradeoff and generalize well despite overfitting noise. Many recent works attempt to analyze this phenomenon in the relatively tractable setting of kernel regression. However, as we argue in detail, most past works on this topic either make unrealistic assumptions, or focus on a narrow problem setup. This work aims to provide a unified theory to upper bound the excess risk of kernel regression for nearly all common and realistic settings. Specifically, we provide rigorous bounds that hold for common kernels and for any amount of regularization, noise, any input dimension, and any number of samples. Furthermore, we provide relative perturbation bounds for the eigenvalues of kernel matrices, which may be of independent interest. These reveal a self-regularization phenomenon, whereby a heavy tail in the eigendecomposition of the kernel provides it with an implicit form of regularization, enabling good generalization. When applied to common kernels, our results imply benign overfitting in high input dimensions, nearly tempered overfitting in fixed dimensions, and explicit convergence rates for regularized regression. As a by-product, we obtain time-dependent bounds for neural networks trained in the kernel regime.
An Algorithm with Optimal Dimension-Dependence for Zero-Order Nonsmooth Nonconvex Stochastic Optimization
Jul 10, 2023We study the complexity of producing $(\delta,\epsilon)$-stationary points of Lipschitz objectives which are possibly neither smooth nor convex, using only noisy function evaluations. Recent works proposed several stochastic zero-order algorithms that solve this task, all of which suffer from a dimension-dependence of $\Omega(d^{3/2})$ where $d$ is the dimension of the problem, which was conjectured to be optimal. We refute this conjecture by providing a faster algorithm that has complexity $O(d\delta^{-1}\epsilon^{-3})$, which is optimal (up to numerical constants) with respect to $d$ and also optimal with respect to the accuracy parameters $\delta,\epsilon$, thus solving an open question due to Lin et al. (NeurIPS'22). Moreover, the convergence rate achieved by our algorithm is also optimal for smooth objectives, proving that in the nonconvex stochastic zero-order setting, nonsmooth optimization is as easy as smooth optimization. We provide algorithms that achieve the aforementioned convergence rate in expectation as well as with high probability. Our analysis is based on a simple yet powerful geometric lemma regarding the Goldstein-subdifferential set, which allows utilizing recent advancements in first-order nonsmooth nonconvex optimization.
Initialization-Dependent Sample Complexity of Linear Predictors and Neural Networks
May 25, 2023We provide several new results on the sample complexity of vector-valued linear predictors (parameterized by a matrix), and more generally neural networks. Focusing on size-independent bounds, where only the Frobenius norm distance of the parameters from some fixed reference matrix $W_0$ is controlled, we show that the sample complexity behavior can be surprisingly different than what we may expect considering the well-studied setting of scalar-valued linear predictors. This also leads to new sample complexity bounds for feed-forward neural networks, tackling some open questions in the literature, and establishing a new convex linear prediction problem that is provably learnable without uniform convergence.
From Tempered to Benign Overfitting in ReLU Neural Networks
May 24, 2023


Overparameterized neural networks (NNs) are observed to generalize well even when trained to perfectly fit noisy data. This phenomenon motivated a large body of work on "benign overfitting", where interpolating predictors achieve near-optimal performance. Recently, it was conjectured and empirically observed that the behavior of NNs is often better described as "tempered overfitting", where the performance is non-optimal yet also non-trivial, and degrades as a function of the noise level. However, a theoretical justification of this claim for non-linear NNs has been lacking so far. In this work, we provide several results that aim at bridging these complementing views. We study a simple classification setting with 2-layer ReLU NNs, and prove that under various assumptions, the type of overfitting transitions from tempered in the extreme case of one-dimensional data, to benign in high dimensions. Thus, we show that the input dimension has a crucial role on the type of overfitting in this setting, which we also validate empirically for intermediate dimensions. Overall, our results shed light on the intricate connections between the dimension, sample size, architecture and training algorithm on the one hand, and the type of resulting overfitting on the other hand.
Deterministic Nonsmooth Nonconvex Optimization
Feb 16, 2023We study the complexity of optimizing nonsmooth nonconvex Lipschitz functions by producing $(\delta,\epsilon)$-stationary points. Several recent works have presented randomized algorithms that produce such points using $\tilde O(\delta^{-1}\epsilon^{-3})$ first-order oracle calls, independent of the dimension $d$. It has been an open problem as to whether a similar result can be obtained via a deterministic algorithm. We resolve this open problem, showing that randomization is necessary to obtain a dimension-free rate. In particular, we prove a lower bound of $\Omega(d)$ for any deterministic algorithm. Moreover, we show that unlike smooth or convex optimization, access to function values is required for any deterministic algorithm to halt within any finite time. On the other hand, we prove that if the function is even slightly smooth, then the dimension-free rate of $\tilde O(\delta^{-1}\epsilon^{-3})$ can be obtained by a deterministic algorithm with merely a logarithmic dependence on the smoothness parameter. Motivated by these findings, we turn to study the complexity of deterministically smoothing Lipschitz functions. Though there are efficient black-box randomized smoothings, we start by showing that no such deterministic procedure can smooth functions in a meaningful manner, resolving an open question. We then bypass this impossibility result for the structured case of ReLU neural networks. To that end, in a practical white-box setting in which the optimizer is granted access to the network's architecture, we propose a simple, dimension-free, deterministic smoothing that provably preserves $(\delta,\epsilon)$-stationary points. Our method applies to a variety of architectures of arbitrary depth, including ResNets and ConvNets. Combined with our algorithm, this yields the first deterministic dimension-free algorithm for optimizing ReLU networks, circumventing our lower bound.
On the Complexity of Finding Small Subgradients in Nonsmooth Optimization
Sep 21, 2022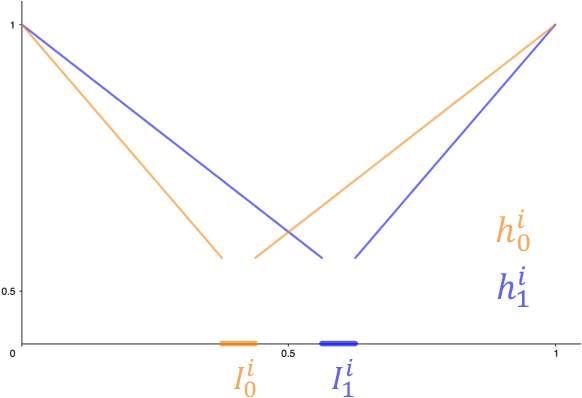
We study the oracle complexity of producing $(\delta,\epsilon)$-stationary points of Lipschitz functions, in the sense proposed by Zhang et al. [2020]. While there exist dimension-free randomized algorithms for producing such points within $\widetilde{O}(1/\delta\epsilon^3)$ first-order oracle calls, we show that no dimension-free rate can be achieved by a deterministic algorithm. On the other hand, we point out that this rate can be derandomized for smooth functions with merely a logarithmic dependence on the smoothness parameter. Moreover, we establish several lower bounds for this task which hold for any randomized algorithm, with or without convexity. Finally, we show how the convergence rate of finding $(\delta,\epsilon)$-stationary points can be improved in case the function is convex, a setting which we motivate by proving that in general no finite time algorithm can produce points with small subgradients even for convex functions.
Reconstructing Training Data from Trained Neural Networks
Jun 15, 2022
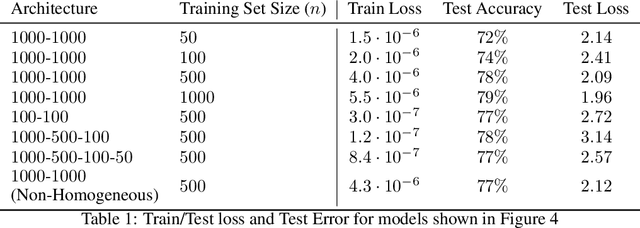
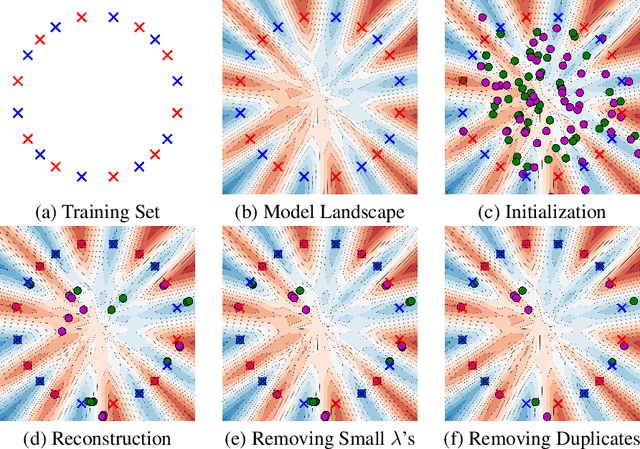
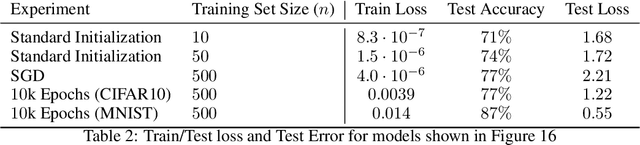
Understanding to what extent neural networks memorize training data is an intriguing question with practical and theoretical implications. In this paper we show that in some cases a significant fraction of the training data can in fact be reconstructed from the parameters of a trained neural network classifier. We propose a novel reconstruction scheme that stems from recent theoretical results about the implicit bias in training neural networks with gradient-based methods. To the best of our knowledge, our results are the first to show that reconstructing a large portion of the actual training samples from a trained neural network classifier is generally possible. This has negative implications on privacy, as it can be used as an attack for revealing sensitive training data. We demonstrate our method for binary MLP classifiers on a few standard computer vision datasets.
The Sample Complexity of One-Hidden-Layer Neural Networks
Feb 13, 2022
We study norm-based uniform convergence bounds for neural networks, aiming at a tight understanding of how these are affected by the architecture and type of norm constraint, for the simple class of scalar-valued one-hidden-layer networks, and inputs bounded in Euclidean norm. We begin by proving that in general, controlling the spectral norm of the hidden layer weight matrix is insufficient to get uniform convergence guarantees (independent of the network width), while a stronger Frobenius norm control is sufficient, extending and improving on previous work. Motivated by the proof constructions, we identify and analyze two important settings where a mere spectral norm control turns out to be sufficient: First, when the network's activation functions are sufficiently smooth (with the result extending to deeper networks); and second, for certain types of convolutional networks. In the latter setting, we study how the sample complexity is additionally affected by parameters such as the amount of overlap between patches and the overall number of patches.
The Implicit Bias of Benign Overfitting
Feb 13, 2022
The phenomenon of benign overfitting, where a predictor perfectly fits noisy training data while attaining low expected loss, has received much attention in recent years, but still remains not fully understood beyond simple linear regression setups. In this paper, we show that for regression, benign overfitting is ``biased'' towards certain types of problems, in the sense that its existence on one learning problem precludes its existence on other learning problems. On the negative side, we use this to argue that one should not expect benign overfitting to occur in general, for several natural extensions of the plain linear regression problems studied so far. We then turn to classification problems, and show that the situation there is much more favorable. Specifically, we consider a model where an arbitrary input distribution of some fixed dimension $k$ is concatenated with a high-dimensional distribution, and prove that the max-margin predictor (to which gradient-based methods are known to converge in direction) is asymptotically biased towards minimizing the expected \emph{squared hinge loss} w.r.t. the $k$-dimensional distribution. This allows us to reduce the question of benign overfitting in classification to the simpler question of whether this loss is a good surrogate for the misclassification error, and use it to show benign overfitting in some new settings.
Gradient Methods Provably Converge to Non-Robust Networks
Feb 09, 2022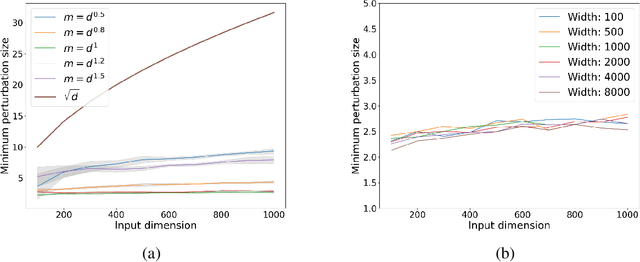
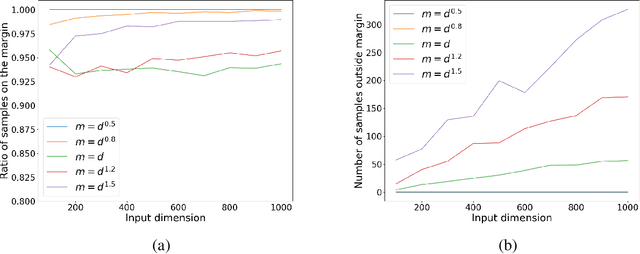
Despite a great deal of research, it is still unclear why neural networks are so susceptible to adversarial examples. In this work, we identify natural settings where depth-$2$ ReLU networks trained with gradient flow are provably non-robust (susceptible to small adversarial $\ell_2$-perturbations), even when robust networks that classify the training dataset correctly exist. Perhaps surprisingly, we show that the well-known implicit bias towards margin maximization induces bias towards non-robust networks, by proving that every network which satisfies the KKT conditions of the max-margin problem is non-robust.