 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarks in Leipzig
Jun 04, 2026Between April 1 and May 15, 2026, a group of 49 mathematicians compiled a dataset of research-level mathematics questions with known answers. Most of the work was done during the 3-day workshop *Benchmarks in Leipzig* with 35 participants at the Max Planck Institute for Mathematics in the Sciences in Leipzig, Germany. We present the resulting collection of 100 questions. We evaluated these questions in three stages: a single attempt by five state-of-the-art LLMs, followed by a 20-runs-per-model evaluation with three of these models, and finally a 3-run attempt with two heavy-thinking models. After Stage 1, 41 questions remained completely unsolved; after Stage 2, this count dropped to 16; and we concluded Stage 3 with only 2 unsolved questions. This demonstrates that the mathematical reasoning capabilities of LLMs are becoming impressive.
Joint NMF for Identification of Shared Features in Datasets and a Dataset Distance Measure
Jul 11, 2022
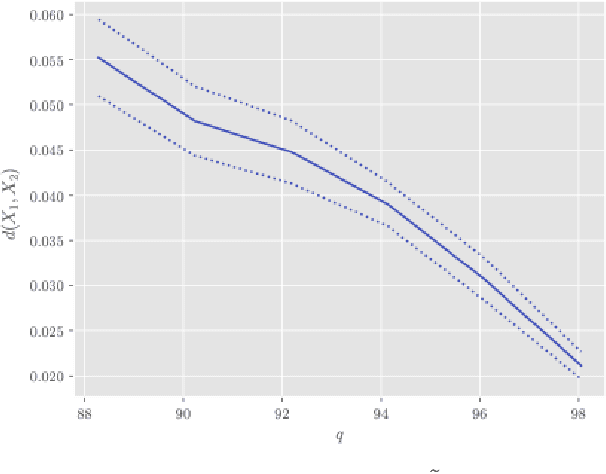
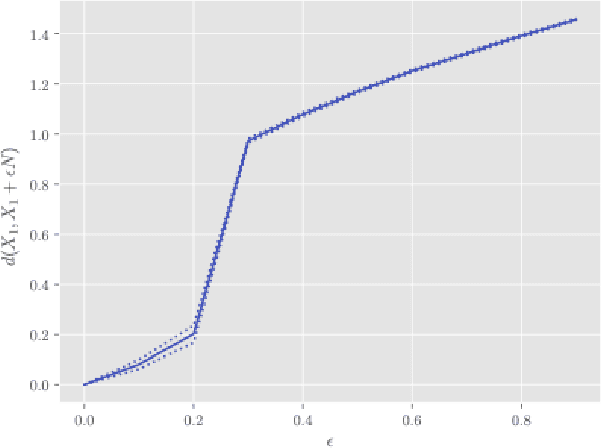
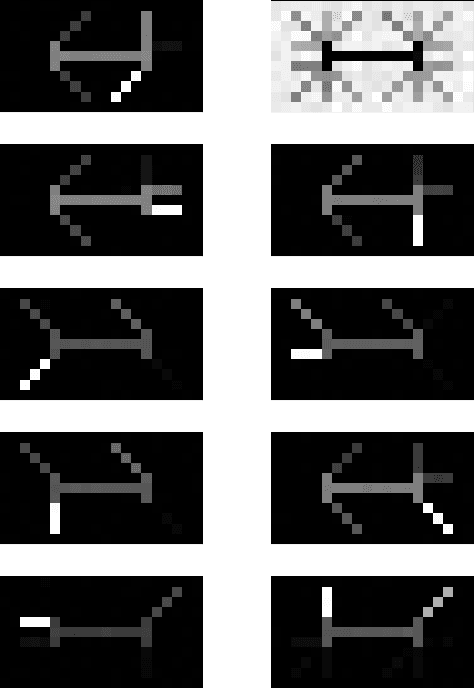
In this paper, we derive a new method for determining shared features of datasets by employing joint non-negative matrix factorization and analyzing the resulting factorizations. Our approach uses the joint factorization of two dataset matrices $X_1,X_2$ into non-negative matrices $X_1 = AS_1, X_2 = AS_2$ to derive a similarity measure that determines how well a shared basis for $X_1, X_2$ approximates each dataset. We also propose a dataset distance measure built upon this method and the learned factorization. Our method is able to successfully identity differences in structure in both image and text datasets. Potential applications include classification, detecting plagiarism or other manipulation, and learning relationships between data sets.