 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGREAD: Graph Neural Reaction-Diffusion Equations
Nov 25, 2022



Graph neural networks (GNNs) are one of the most popular research topics for deep learning. GNN methods typically have been designed on top of the graph signal processing theory. In particular, diffusion equations have been widely used for designing the core processing layer of GNNs and therefore, they are inevitably vulnerable to the oversmoothing problem. Recently, a couple of papers paid attention to reaction equations in conjunctions with diffusion equations. However, they all consider limited forms of reaction equations. To this end, we present a reaction-diffusion equation-based GNN method that considers all popular types of reaction equations in addition to one special reaction equation designed by us. To our knowledge, our paper is one of the most comprehensive studies on reaction-diffusion equation-based GNNs. In our experiments with 9 datasets and 17 baselines, our method, called GREAD, outperforms them in almost all cases. Further synthetic data experiments show that GREAD mitigates the oversmoothing and performs well for various homophily rates.
Time Series Forecasting with Hypernetworks Generating Parameters in Advance
Nov 22, 2022



Forecasting future outcomes from recent time series data is not easy, especially when the future data are different from the past (i.e. time series are under temporal drifts). Existing approaches show limited performances under data drifts, and we identify the main reason: It takes time for a model to collect sufficient training data and adjust its parameters for complicated temporal patterns whenever the underlying dynamics change. To address this issue, we study a new approach; instead of adjusting model parameters (by continuously re-training a model on new data), we build a hypernetwork that generates other target models' parameters expected to perform well on the future data. Therefore, we can adjust the model parameters beforehand (if the hypernetwork is correct). We conduct extensive experiments with 6 target models, 6 baselines, and 4 datasets, and show that our HyperGPA outperforms other baselines.
Perturbation-Recovery Method for Recommendation
Nov 17, 2022Collaborative filtering is one of the most influential recommender system types. Various methods have been proposed for collaborative filtering, ranging from matrix factorization to graph convolutional methods. Being inspired by recent successes of GF-CF and diffusion models, we present a novel concept of blurring-sharpening process model (BSPM). Diffusion models and BSPMs share the same processing philosophy in that new information is discovered (e.g., a new image is generated in the case of diffusion models) while original information is first perturbed and then recovered to its original form. However, diffusion models and our BSPMs deal with different types of information, and their optimal perturbation and recovery processes have a fundamental discrepancy. Therefore, our BSPMs have different forms from diffusion models. In addition, our concept not only theoretically subsumes many existing collaborative filtering models but also outperforms them in terms of Recall and NDCG in the three benchmark datasets, Gowalla, Yelp2018, and Amazon-book. Our model marks the best accuracy in them. In addition, the processing time of our method is one of the shortest cases ever in collaborative filtering. Our proposed concept has much potential in the future to be enhanced by designing better blurring (i.e., perturbation) and sharpening (i.e., recovery) processes than what we use in this paper.
TimeKit: A Time-series Forecasting-based Upgrade Kit for Collaborative Filtering
Nov 08, 2022



Recommender systems are a long-standing research problem in data mining and machine learning. They are incremental in nature, as new user-item interaction logs arrive. In real-world applications, we need to periodically train a collaborative filtering algorithm to extract user/item embedding vectors and therefore, a time-series of embedding vectors can be naturally defined. We present a time-series forecasting-based upgrade kit (TimeKit), which works in the following way: it i) first decides a base collaborative filtering algorithm, ii) extracts user/item embedding vectors with the base algorithm from user-item interaction logs incrementally, e.g., every month, iii) trains our time-series forecasting model with the extracted time-series of embedding vectors, and then iv) forecasts the future embedding vectors and recommend with their dot-product scores owing to a recent breakthrough in processing complicated time-series data, i.e., neural controlled differential equations (NCDEs). Our experiments with four real-world benchmark datasets show that the proposed time-series forecasting-based upgrade kit can significantly enhance existing popular collaborative filtering algorithms.
GT-GAN: General Purpose Time Series Synthesis with Generative Adversarial Networks
Oct 11, 2022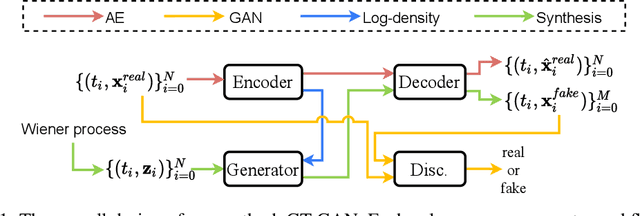
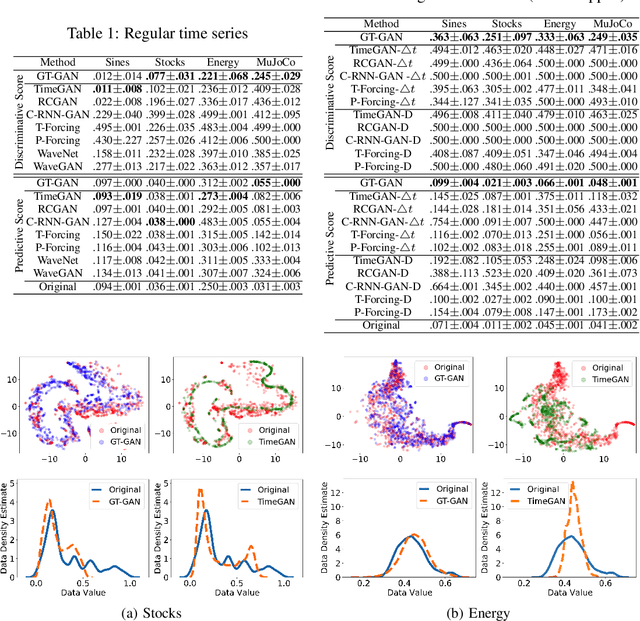
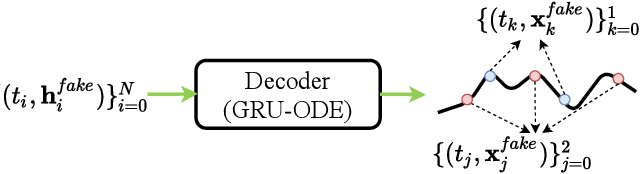
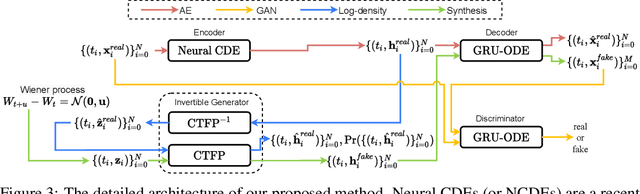
Time series synthesis is an important research topic in the field of deep learning, which can be used for data augmentation. Time series data types can be broadly classified into regular or irregular. However, there are no existing generative models that show good performance for both types without any model changes. Therefore, we present a general purpose model capable of synthesizing regular and irregular time series data. To our knowledge, we are the first designing a general purpose time series synthesis model, which is one of the most challenging settings for time series synthesis. To this end, we design a generative adversarial network-based method, where many related techniques are carefully integrated into a single framework, ranging from neural ordinary/controlled differential equations to continuous time-flow processes. Our method outperforms all existing methods.
Mining Causality from Continuous-time Dynamics Models: An Application to Tsunami Forecasting
Oct 10, 2022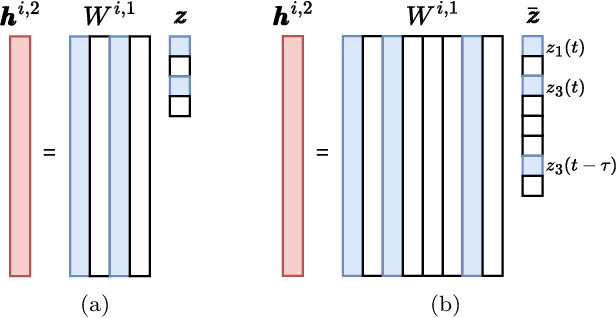
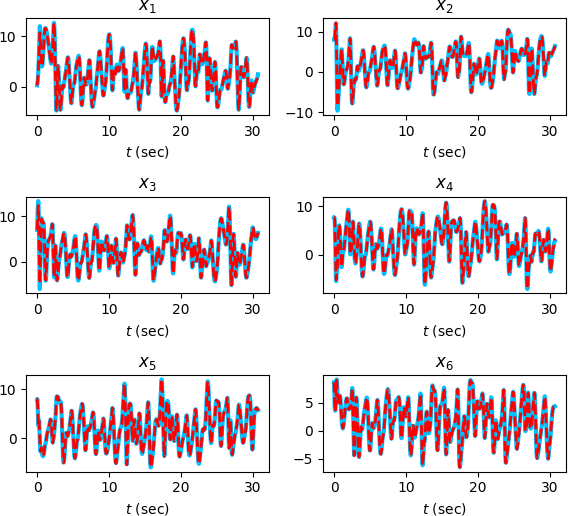
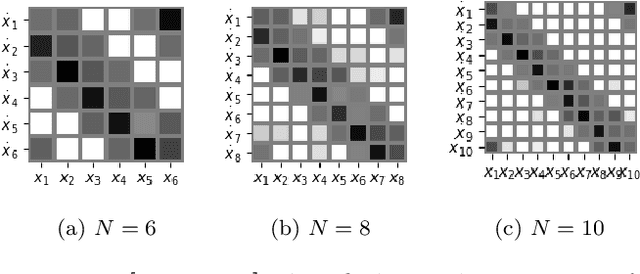
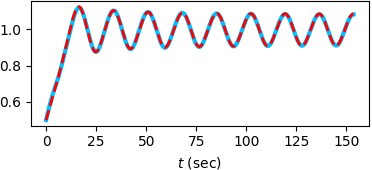
Continuous-time dynamics models, such as neural ordinary differential equations, have enabled the modeling of underlying dynamics in time-series data and accurate forecasting. However, parameterization of dynamics using a neural network makes it difficult for humans to identify causal structures in the data. In consequence, this opaqueness hinders the use of these models in the domains where capturing causal relationships carries the same importance as accurate predictions, e.g., tsunami forecasting. In this paper, we address this challenge by proposing a mechanism for mining causal structures from continuous-time models. We train models to capture the causal structure by enforcing sparsity in the weights of the input layers of the dynamics models. We first verify the effectiveness of our method in the scenario where the exact causal-structures of time-series are known as a priori. We next apply our method to a real-world problem, namely tsunami forecasting, where the exact causal-structures are difficult to characterize. Experimental results show that the proposed method is effective in learning physically-consistent causal relationships while achieving high forecasting accuracy.
STaSy: Score-based Tabular data Synthesis
Oct 08, 2022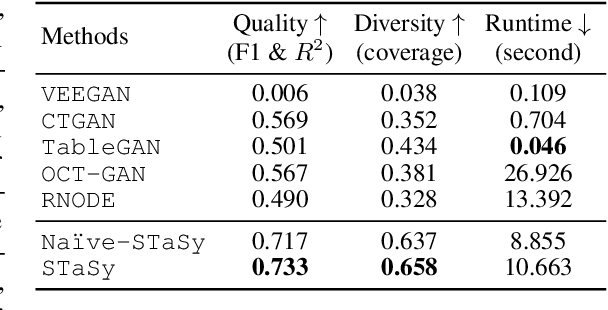
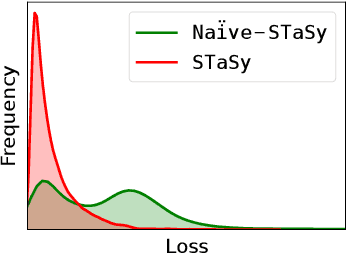
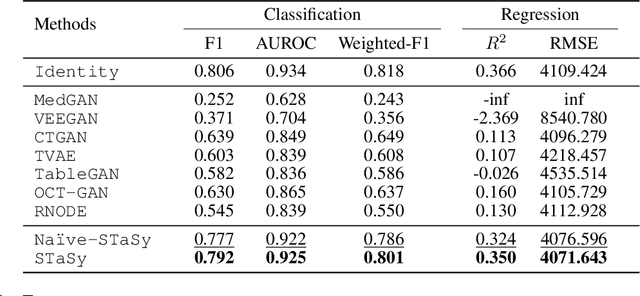

Tabular data synthesis is a long-standing research topic in machine learning. Many different methods have been proposed over the past decades, ranging from statistical methods to deep generative methods. However, it has not always been successful due to the complicated nature of real-world tabular data. In this paper, we present a new model named Score-based Tabular data Synthesis (STaSy) and its training strategy based on the paradigm of score-based generative modeling. Despite the fact that score-based generative models have resolved many issues in generative models, there still exists room for improvement in tabular data synthesis. Our proposed training strategy includes a self-paced learning technique and a fine-tuning strategy, which further increases the sampling quality and diversity by stabilizing the denoising score matching training. Furthermore, we also conduct rigorous experimental studies in terms of the generative task trilemma: sampling quality, diversity, and time. In our experiments with 15 benchmark tabular datasets and 7 baselines, our method outperforms existing methods in terms of task-dependant evaluations and diversity.
Phishing URL Detection: A Network-based Approach Robust to Evasion
Sep 03, 2022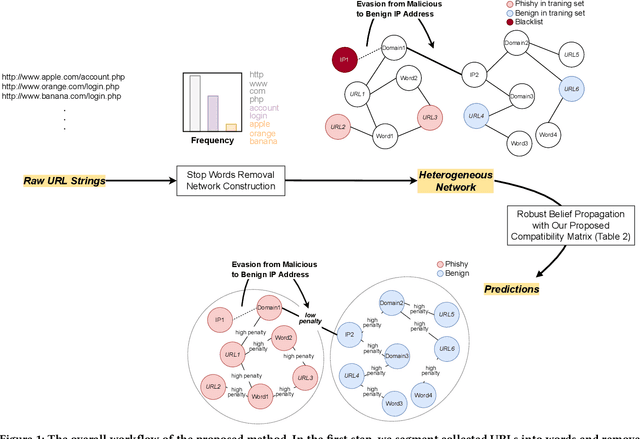

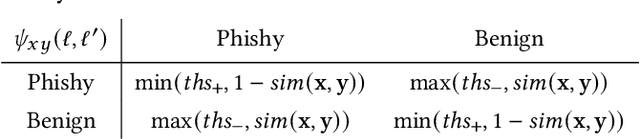
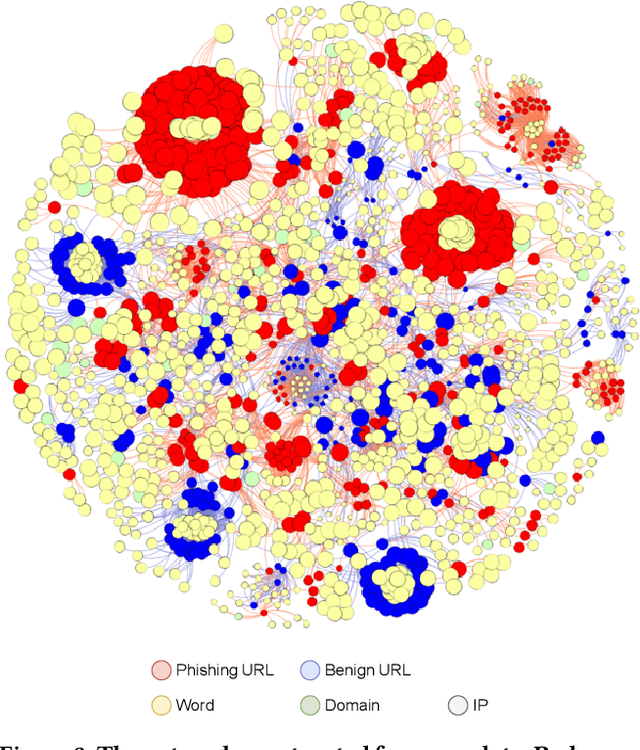
Many cyberattacks start with disseminating phishing URLs. When clicking these phishing URLs, the victim's private information is leaked to the attacker. There have been proposed several machine learning methods to detect phishing URLs. However, it still remains under-explored to detect phishing URLs with evasion, i.e., phishing URLs that pretend to be benign by manipulating patterns. In many cases, the attacker i) reuses prepared phishing web pages because making a completely brand-new set costs non-trivial expenses, ii) prefers hosting companies that do not require private information and are cheaper than others, iii) prefers shared hosting for cost efficiency, and iv) sometimes uses benign domains, IP addresses, and URL string patterns to evade existing detection methods. Inspired by those behavioral characteristics, we present a network-based inference method to accurately detect phishing URLs camouflaged with legitimate patterns, i.e., robust to evasion. In the network approach, a phishing URL will be still identified as phishy even after evasion unless a majority of its neighbors in the network are evaded at the same time. Our method consistently shows better detection performance throughout various experimental tests than state-of-the-art methods, e.g., F-1 of 0.89 for our method vs. 0.84 for the best feature-based method.
Prediction-based One-shot Dynamic Parking Pricing
Aug 30, 2022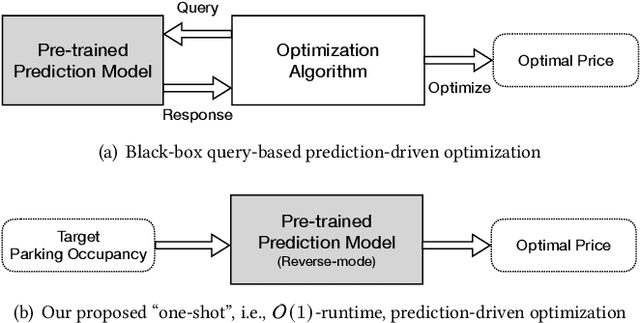
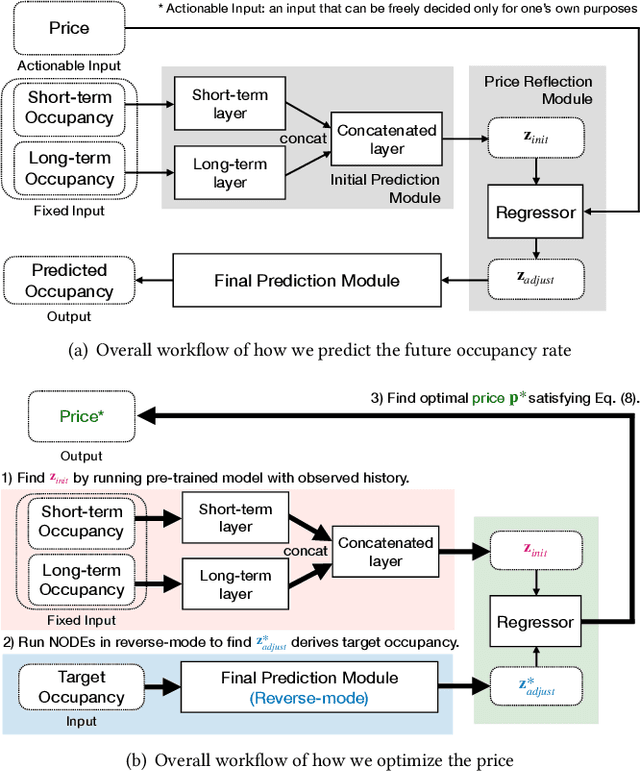
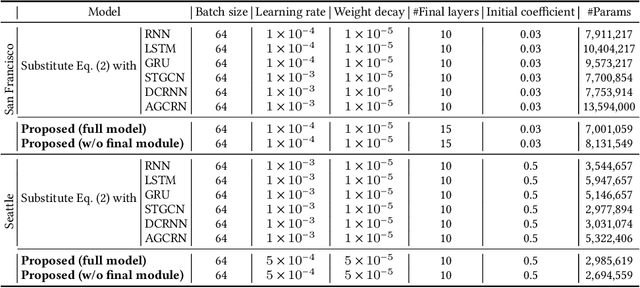
Many U.S. metropolitan cities are notorious for their severe shortage of parking spots. To this end, we present a proactive prediction-driven optimization framework to dynamically adjust parking prices. We use state-of-the-art deep learning technologies such as neural ordinary differential equations (NODEs) to design our future parking occupancy rate prediction model given historical occupancy rates and price information. Owing to the continuous and bijective characteristics of NODEs, in addition, we design a one-shot price optimization method given a pre-trained prediction model, which requires only one iteration to find the optimal solution. In other words, we optimize the price input to the pre-trained prediction model to achieve targeted occupancy rates in the parking blocks. We conduct experiments with the data collected in San Francisco and Seattle for years. Our prediction model shows the best accuracy in comparison with various temporal or spatio-temporal forecasting models. Our one-shot optimization method greatly outperforms other black-box and white-box search methods in terms of the search time and always returns the optimal price solution.
An Empirical Study on the Membership Inference Attack against Tabular Data Synthesis Models
Aug 25, 2022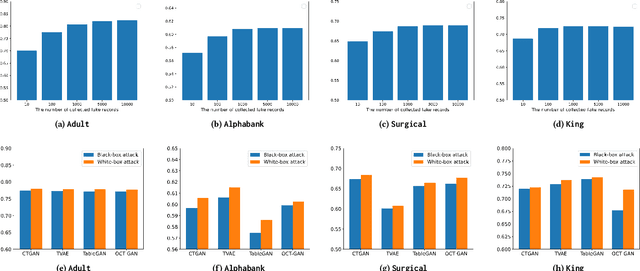
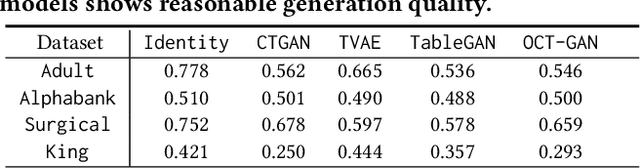

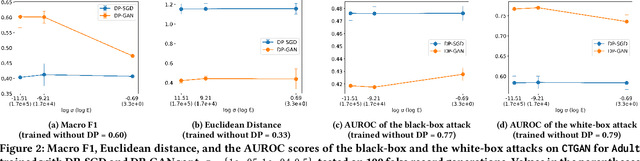
Tabular data typically contains private and important information; thus, precautions must be taken before they are shared with others. Although several methods (e.g., differential privacy and k-anonymity) have been proposed to prevent information leakage, in recent years, tabular data synthesis models have become popular because they can well trade-off between data utility and privacy. However, recent research has shown that generative models for image data are susceptible to the membership inference attack, which can determine whether a given record was used to train a victim synthesis model. In this paper, we investigate the membership inference attack in the context of tabular data synthesis. We conduct experiments on 4 state-of-the-art tabular data synthesis models under two attack scenarios (i.e., one black-box and one white-box attack), and find that the membership inference attack can seriously jeopardize these models. We next conduct experiments to evaluate how well two popular differentially-private deep learning training algorithms, DP-SGD and DP-GAN, can protect the models against the attack. Our key finding is that both algorithms can largely alleviate this threat by sacrificing the generation quality.