 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat if we had no Wikipedia? Domain-independent Term Extraction from a Large News Corpus
Sep 17, 2020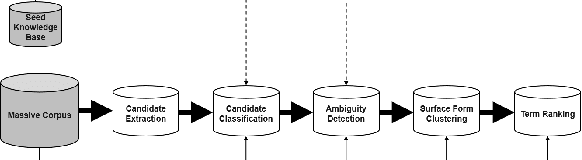
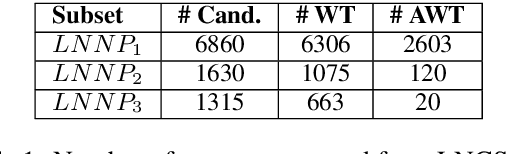
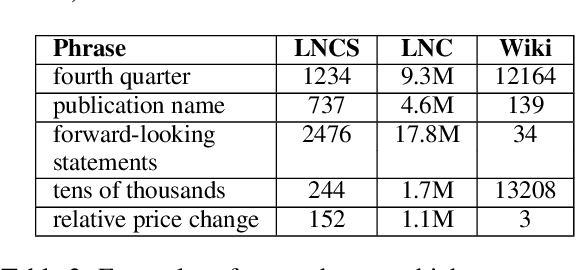
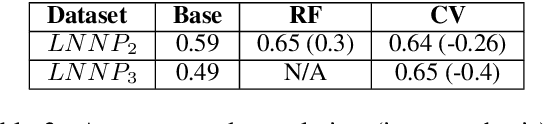
One of the most impressive human endeavors of the past two decades is the collection and categorization of human knowledge in the free and accessible format that is Wikipedia. In this work we ask what makes a term worthy of entering this edifice of knowledge, and having a page of its own in Wikipedia? To what extent is this a natural product of on-going human discourse and discussion rather than an idiosyncratic choice of Wikipedia editors? Specifically, we aim to identify such "wiki-worthy" terms in a massive news corpus, and see if this can be done with no, or minimal, dependency on actual Wikipedia entries. We suggest a five-step pipeline for doing so, providing baseline results for all five, and the relevant datasets for benchmarking them. Our work sheds new light on the domain-specific Automatic Term Extraction problem, with the problem at hand being a domain-independent variant of it.
From Arguments to Key Points: Towards Automatic Argument Summarization
May 04, 2020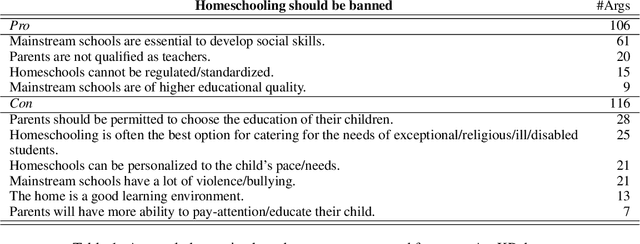
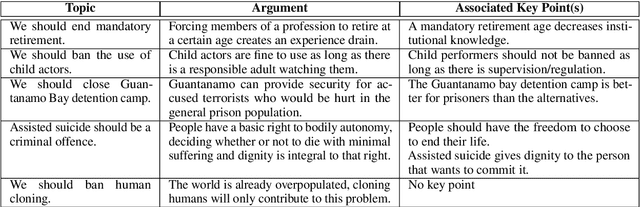
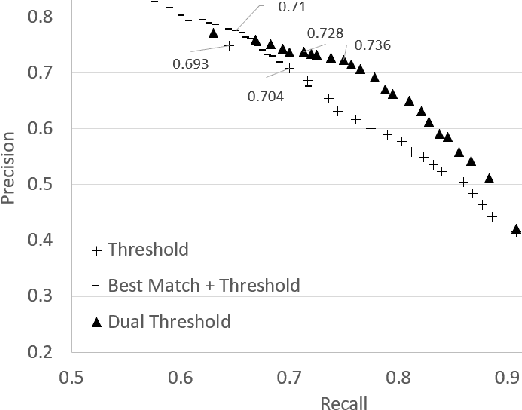
Generating a concise summary from a large collection of arguments on a given topic is an intriguing yet understudied problem. We propose to represent such summaries as a small set of talking points, termed "key points", each scored according to its salience. We show, by analyzing a large dataset of crowd-contributed arguments, that a small number of key points per topic is typically sufficient for covering the vast majority of the arguments. Furthermore, we found that a domain expert can often predict these key points in advance. We study the task of argument-to-key point mapping, and introduce a novel large-scale dataset for this task. We report empirical results for an extensive set of experiments with this dataset, showing promising performance.
Out of the Echo Chamber: Detecting Countering Debate Speeches
May 03, 2020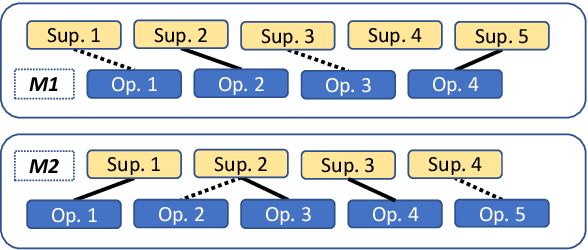

An educated and informed consumption of media content has become a challenge in modern times. With the shift from traditional news outlets to social media and similar venues, a major concern is that readers are becoming encapsulated in "echo chambers" and may fall prey to fake news and disinformation, lacking easy access to dissenting views. We suggest a novel task aiming to alleviate some of these concerns -- that of detecting articles that most effectively counter the arguments -- and not just the stance -- made in a given text. We study this problem in the context of debate speeches. Given such a speech, we aim to identify, from among a set of speeches on the same topic and with an opposing stance, the ones that directly counter it. We provide a large dataset of 3,685 such speeches (in English), annotated for this relation, which hopefully would be of general interest to the NLP community. We explore several algorithms addressing this task, and while some are successful, all fall short of expert human performance, suggesting room for further research. All data collected during this work is freely available for research.
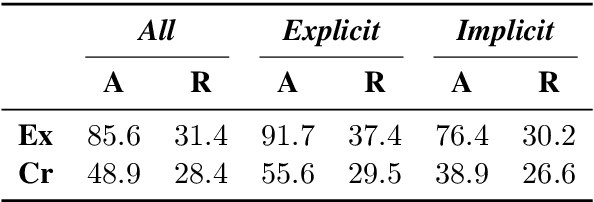
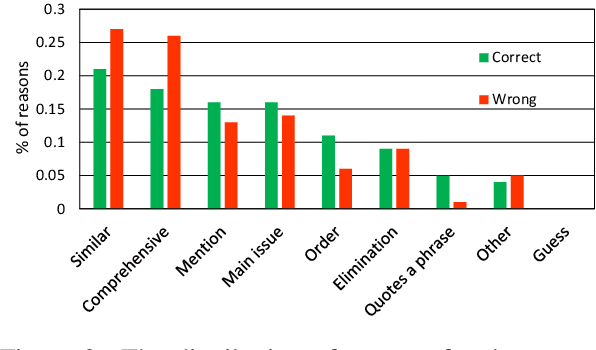
A Large-scale Dataset for Argument Quality Ranking: Construction and Analysis
Nov 26, 2019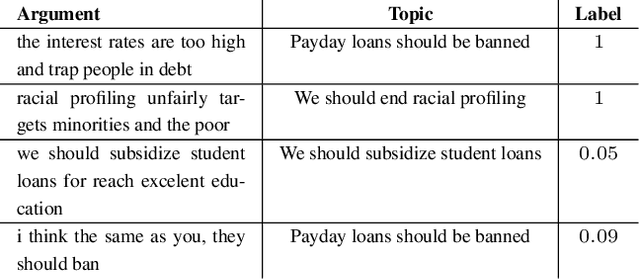
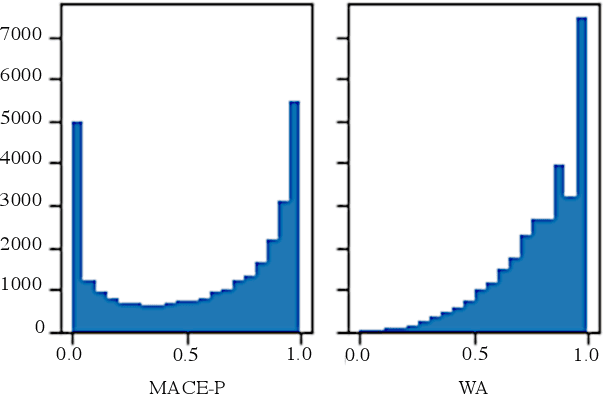

Identifying the quality of free-text arguments has become an important task in the rapidly expanding field of computational argumentation. In this work, we explore the challenging task of argument quality ranking. To this end, we created a corpus of 30,497 arguments carefully annotated for point-wise quality, released as part of this work. To the best of our knowledge, this is the largest dataset annotated for point-wise argument quality, larger by a factor of five than previously released datasets. Moreover, we address the core issue of inducing a labeled score from crowd annotations by performing a comprehensive evaluation of different approaches to this problem. In addition, we analyze the quality dimensions that characterize this dataset. Finally, we present a neural method for argument quality ranking, which outperforms several baselines on our own dataset, as well as previous methods published for another dataset.
Corpus Wide Argument Mining -- a Working Solution
Nov 25, 2019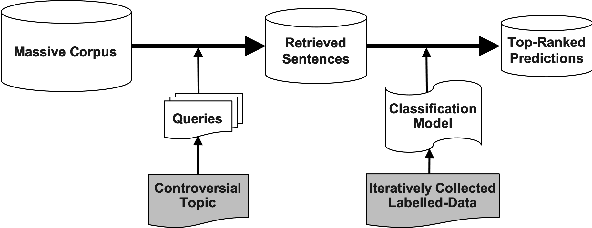
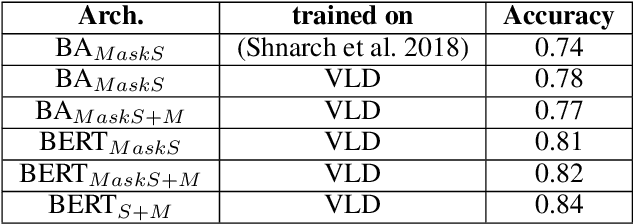
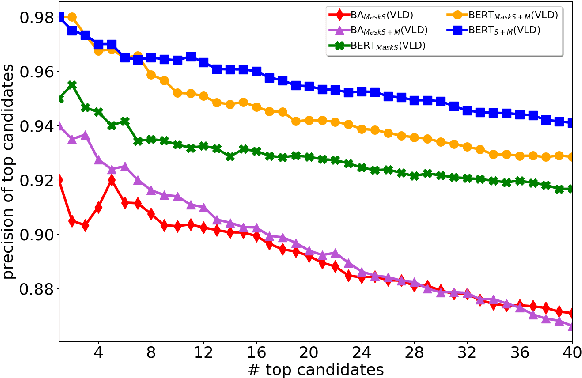
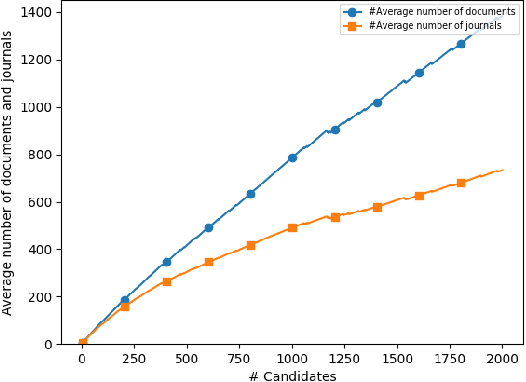
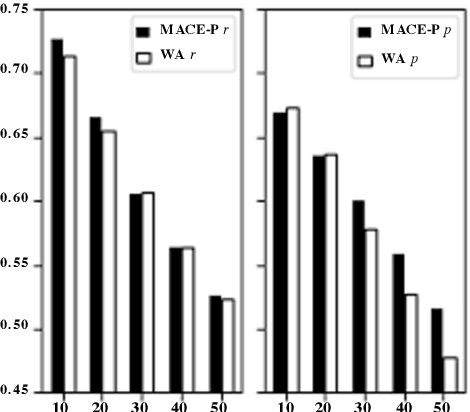
One of the main tasks in argument mining is the retrieval of argumentative content pertaining to a given topic. Most previous work addressed this task by retrieving a relatively small number of relevant documents as the initial source for such content. This line of research yielded moderate success, which is of limited use in a real-world system. Furthermore, for such a system to yield a comprehensive set of relevant arguments, over a wide range of topics, it requires leveraging a large and diverse corpus in an appropriate manner. Here we present a first end-to-end high-precision, corpus-wide argument mining system. This is made possible by combining sentence-level queries over an appropriate indexing of a very large corpus of newspaper articles, with an iterative annotation scheme. This scheme addresses the inherent label bias in the data and pinpoints the regions of the sample space whose manual labeling is required to obtain high-precision among top-ranked candidates.
Automatic Argument Quality Assessment -- New Datasets and Methods
Sep 03, 2019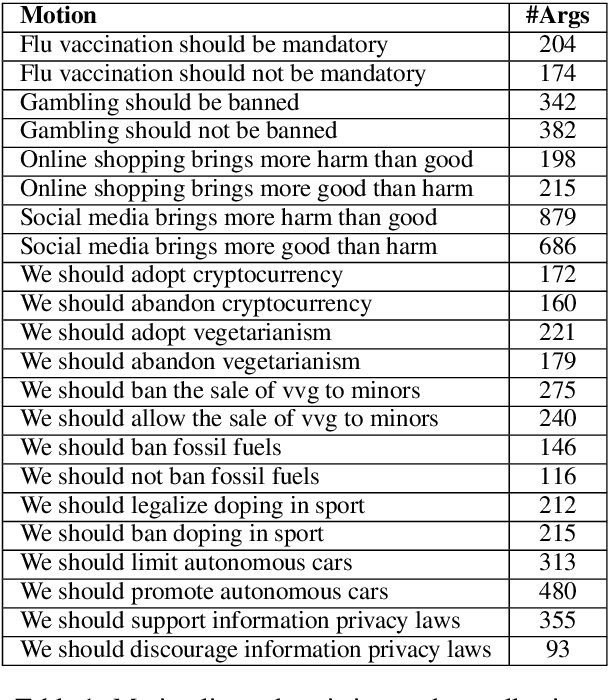
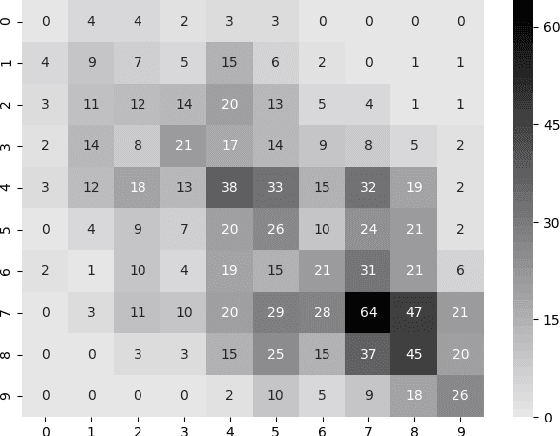
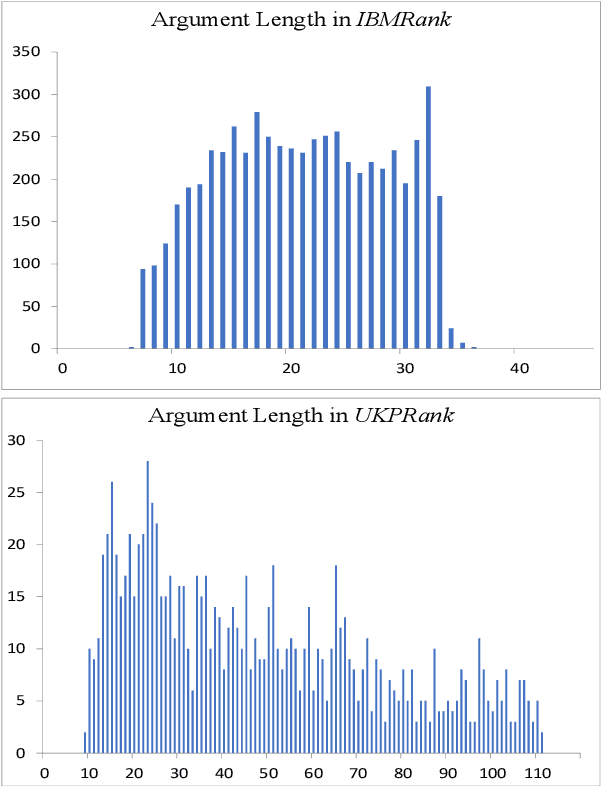
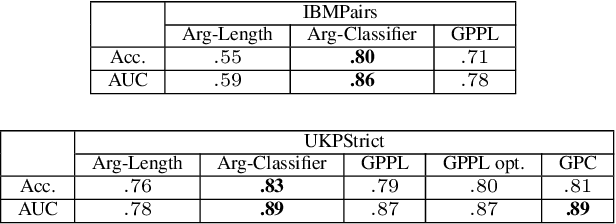
We explore the task of automatic assessment of argument quality. To that end, we actively collected 6.3k arguments, more than a factor of five compared to previously examined data. Each argument was explicitly and carefully annotated for its quality. In addition, 14k pairs of arguments were annotated independently, identifying the higher quality argument in each pair. In spite of the inherent subjective nature of the task, both annotation schemes led to surprisingly consistent results. We release the labeled datasets to the community. Furthermore, we suggest neural methods based on a recently released language model, for argument ranking as well as for argument-pair classification. In the former task, our results are comparable to state-of-the-art; in the latter task our results significantly outperform earlier methods.
A Dataset of General-Purpose Rebuttal
Sep 01, 2019
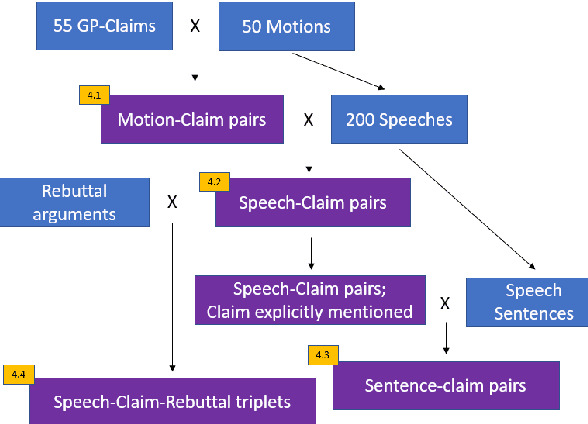
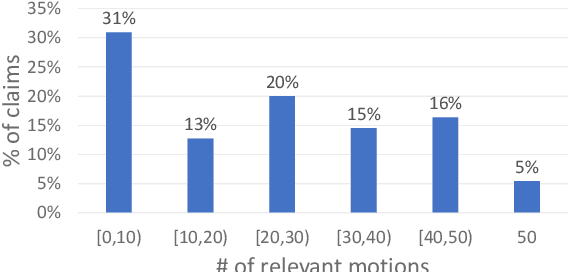
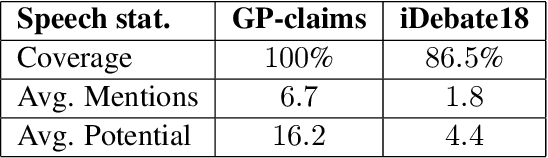
In Natural Language Understanding, the task of response generation is usually focused on responses to short texts, such as tweets or a turn in a dialog. Here we present a novel task of producing a critical response to a long argumentative text, and suggest a method based on general rebuttal arguments to address it. We do this in the context of the recently-suggested task of listening comprehension over argumentative content: given a speech on some specified topic, and a list of relevant arguments, the goal is to determine which of the arguments appear in the speech. The general rebuttals we describe here (written in English) overcome the need for topic-specific arguments to be provided, by proving to be applicable for a large set of topics. This allows creating responses beyond the scope of topics for which specific arguments are available. All data collected during this work is freely available for research.
Argument Invention from First Principles
Aug 22, 2019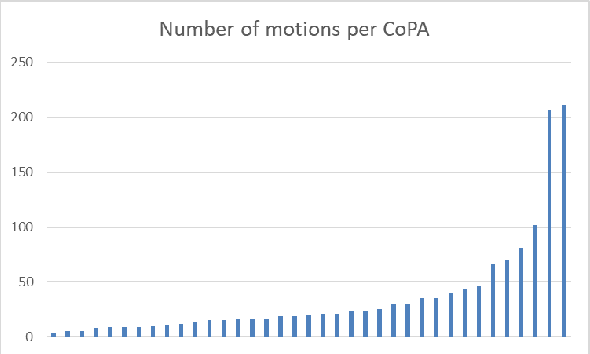

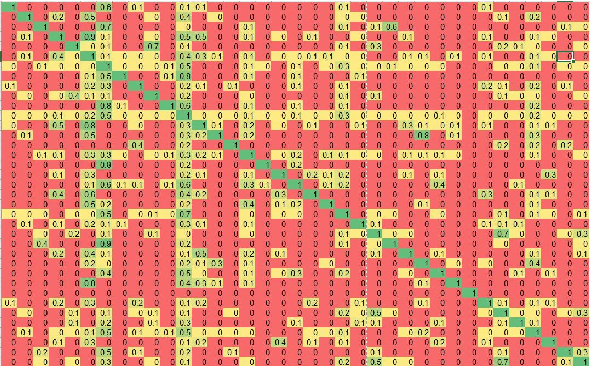
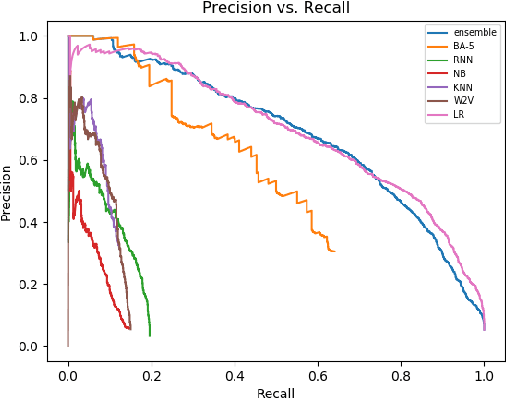
Competitive debaters often find themselves facing a challenging task -- how to debate a topic they know very little about, with only minutes to prepare, and without access to books or the Internet? What they often do is rely on "first principles", commonplace arguments which are relevant to many topics, and which they have refined in past debates. In this work we aim to explicitly define a taxonomy of such principled recurring arguments, and, given a controversial topic, to automatically identify which of these arguments are relevant to the topic. As far as we know, this is the first time that this approach to argument invention is formalized and made explicit in the context of NLP. The main goal of this work is to show that it is possible to define such a taxonomy. While the taxonomy suggested here should be thought of as a "first attempt" it is nonetheless coherent, covers well the relevant topics and coincides with what professional debaters actually argue in their speeches, and facilitates automatic argument invention for new topics.
Controversy in Context
Aug 20, 2019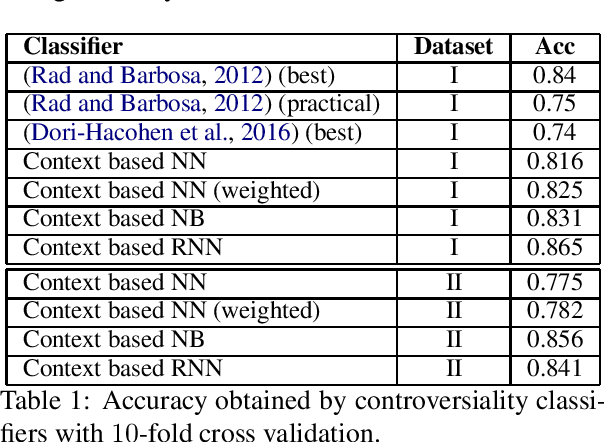
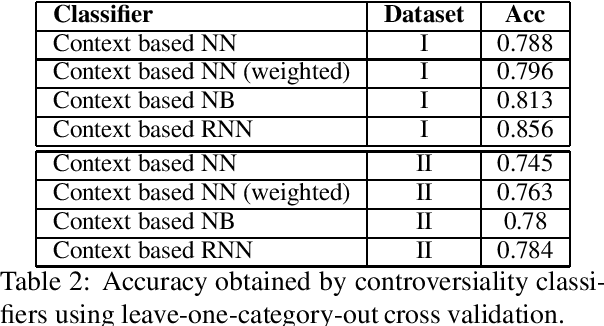
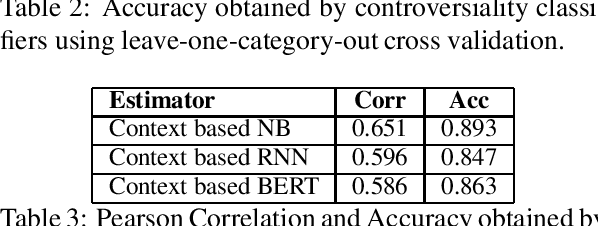
With the growing interest in social applications of Natural Language Processing and Computational Argumentation, a natural question is how controversial a given concept is. Prior works relied on Wikipedia's metadata and on content analysis of the articles pertaining to a concept in question. Here we show that the immediate textual context of a concept is strongly indicative of this property, and, using simple and language-independent machine-learning tools, we leverage this observation to achieve state-of-the-art results in controversiality prediction. In addition, we analyze and make available a new dataset of concepts labeled for controversiality. It is significantly larger than existing datasets, and grades concepts on a 0-10 scale, rather than treating controversiality as a binary label.
Fast End-to-End Wikification
Aug 19, 2019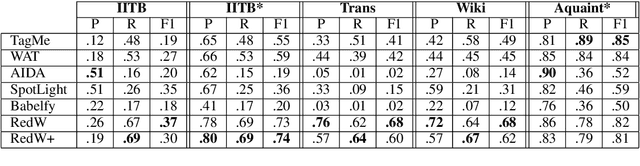
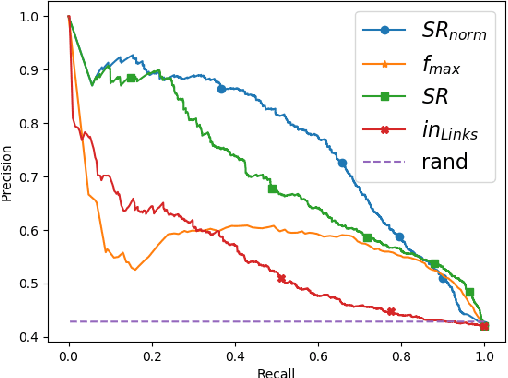
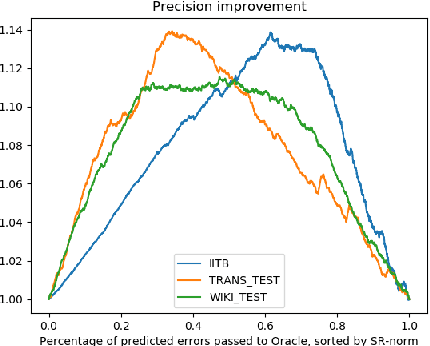

Wikification of large corpora is beneficial for various NLP applications. Existing methods focus on quality performance rather than run-time, and are therefore non-feasible for large data. Here, we introduce RedW, a run-time oriented Wikification solution, based on Wikipedia redirects, that can Wikify massive corpora with competitive performance. We further propose an efficient method for estimating RedW confidence, opening the door for applying more demanding methods only on top of RedW lower-confidence results. Our experimental results support the validity of the proposed approach.