 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoam Brown
Safe Search for Stackelberg Equilibria in Extensive-Form Games
Feb 02, 2021
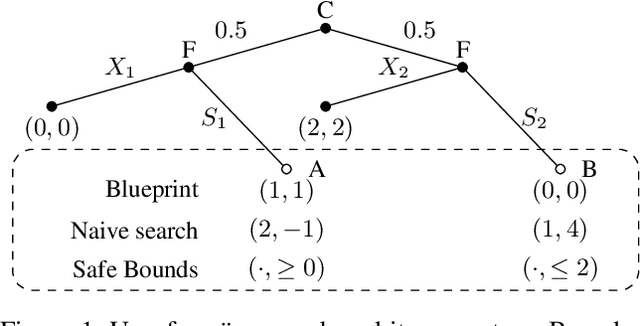
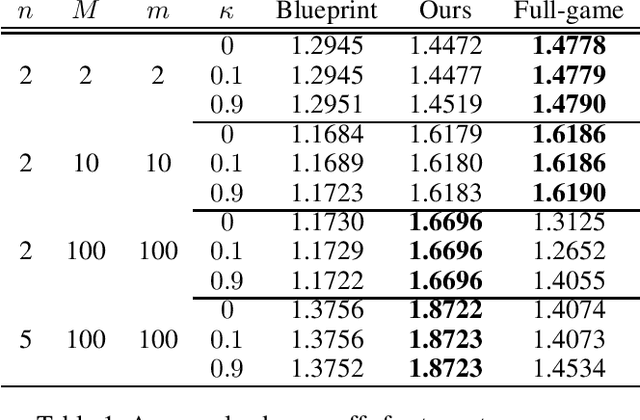
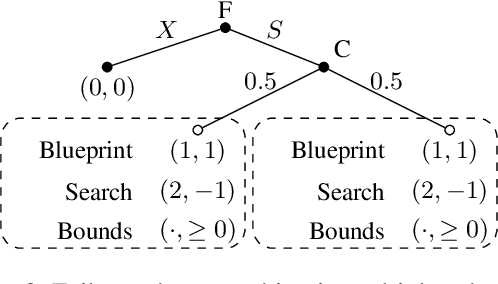

Stackelberg equilibrium is a solution concept in two-player games where the leader has commitment rights over the follower. In recent years, it has become a cornerstone of many security applications, including airport patrolling and wildlife poaching prevention. Even though many of these settings are sequential in nature, existing techniques pre-compute the entire solution ahead of time. In this paper, we present a theoretically sound and empirically effective way to apply search, which leverages extra online computation to improve a solution, to the computation of Stackelberg equilibria in general-sum games. Instead of the leader attempting to solve the full game upfront, an approximate "blueprint" solution is first computed offline and is then improved online for the particular subgames encountered in actual play. We prove that our search technique is guaranteed to perform no worse than the pre-computed blueprint strategy, and empirically demonstrate that it enables approximately solving significantly larger games compared to purely offline methods. We also show that our search operation may be cast as a smaller Stackelberg problem, making our method complementary to existing algorithms based on strategy generation.
Human-Level Performance in No-Press Diplomacy via Equilibrium Search
Oct 06, 2020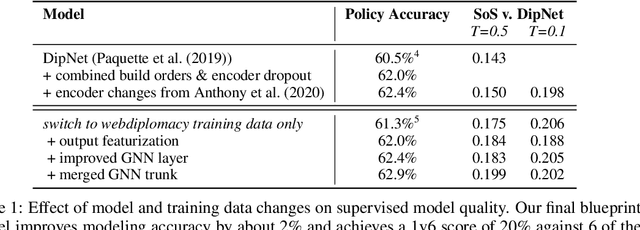
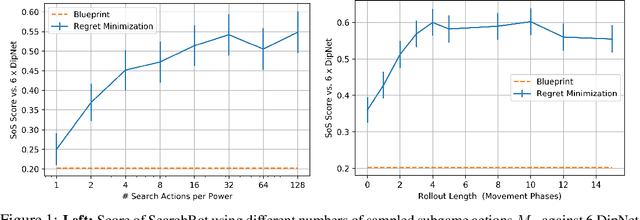
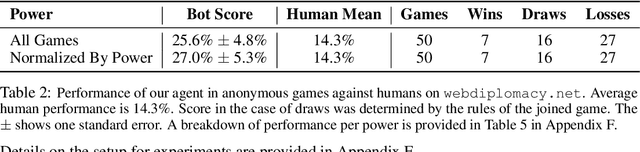
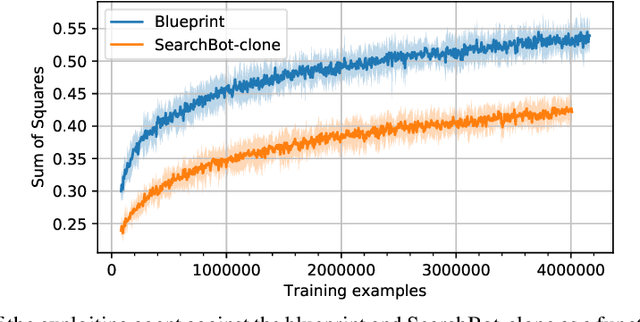
Prior AI breakthroughs in complex games have focused on either the purely adversarial or purely cooperative settings. In contrast, Diplomacy is a game of shifting alliances that involves both cooperation and competition. For this reason, Diplomacy has proven to be a formidable research challenge. In this paper we describe an agent for the no-press variant of Diplomacy that combines supervised learning on human data with one-step lookahead search via external regret minimization. External regret minimization techniques have been behind previous AI successes in adversarial games, most notably poker, but have not previously been shown to be successful in large-scale games involving cooperation. We show that our agent greatly exceeds the performance of past no-press Diplomacy bots, is unexploitable by expert humans, and achieves a rank of 23 out of 1,128 human players when playing anonymous games on a popular Diplomacy website.
Combining Deep Reinforcement Learning and Search for Imperfect-Information Games
Jul 27, 2020
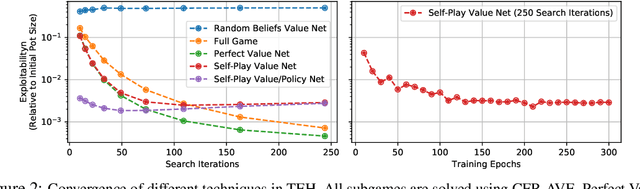
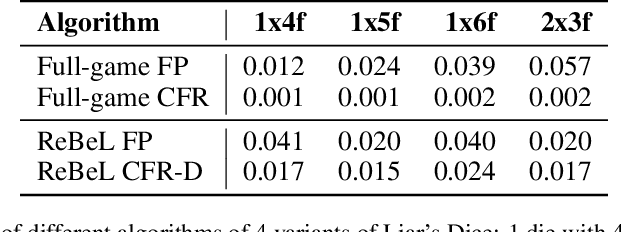
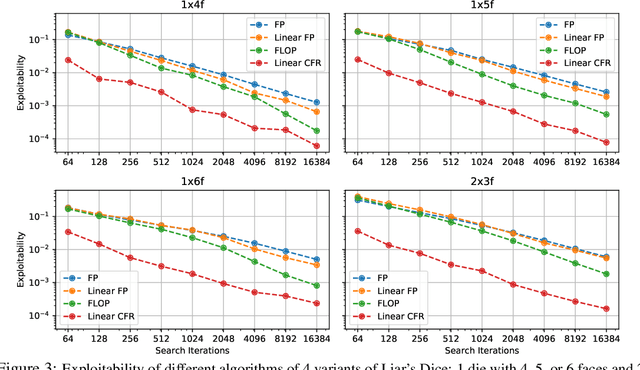
The combination of deep reinforcement learning and search at both training and test time is a powerful paradigm that has led to a number of a successes in single-agent settings and perfect-information games, best exemplified by the success of AlphaZero. However, algorithms of this form have been unable to cope with imperfect-information games. This paper presents ReBeL, a general framework for self-play reinforcement learning and search for imperfect-information games. In the simpler setting of perfect-information games, ReBeL reduces to an algorithm similar to AlphaZero. Results show ReBeL leads to low exploitability in benchmark imperfect-information games and achieves superhuman performance in heads-up no-limit Texas hold'em poker, while using far less domain knowledge than any prior poker AI. We also prove that ReBeL converges to a Nash equilibrium in two-player zero-sum games in tabular settings.
Unlocking the Potential of Deep Counterfactual Value Networks
Jul 20, 2020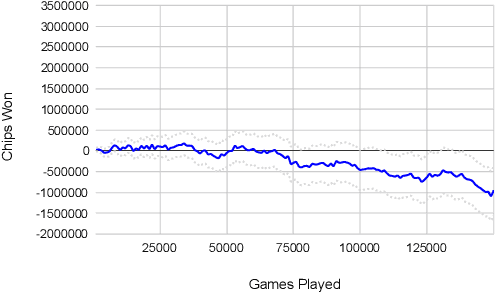
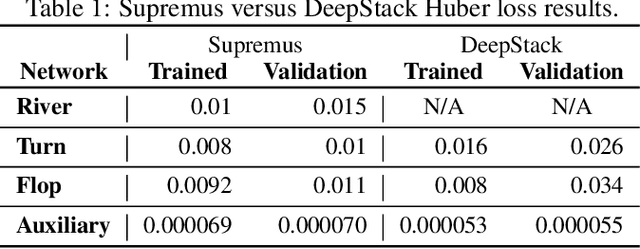
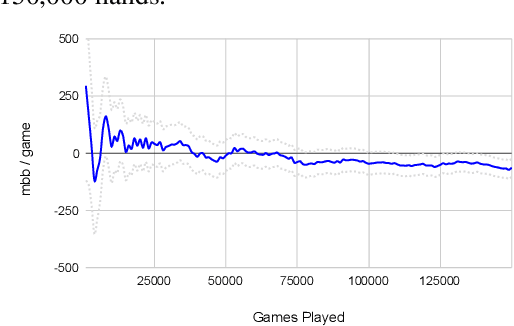

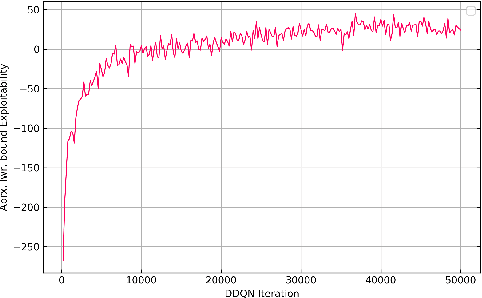
Deep counterfactual value networks combined with continual resolving provide a way to conduct depth-limited search in imperfect-information games. However, since their introduction in the DeepStack poker AI, deep counterfactual value networks have not seen widespread adoption. In this paper we introduce several improvements to deep counterfactual value networks, as well as counterfactual regret minimization, and analyze the effects of each change. We combined these improvements to create the poker AI Supremus. We show that while a reimplementation of DeepStack loses head-to-head against the strong benchmark agent Slumbot, Supremus successfully beats Slumbot by an extremely large margin and also achieves a lower exploitability than DeepStack against a local best response. Together, these results show that with our key improvements, deep counterfactual value networks can achieve state-of-the-art performance.
DREAM: Deep Regret minimization with Advantage baselines and Model-free learning
Jun 18, 2020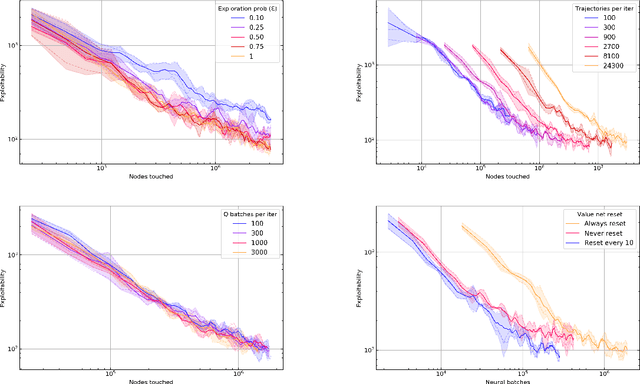
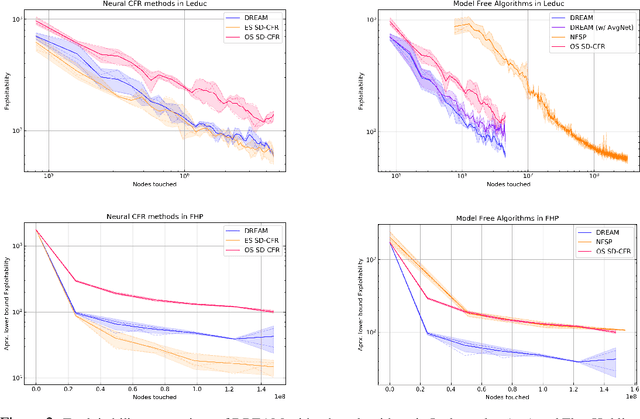
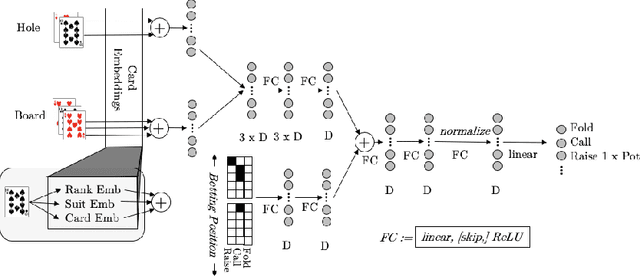
We introduce DREAM, a deep reinforcement learning algorithm that finds optimal strategies in imperfect-information games with multiple agents. Formally, DREAM converges to a Nash Equilibrium in two-player zero-sum games and to an extensive-form coarse correlated equilibrium in all other games. Our primary innovation is an effective algorithm that, in contrast to other regret-based deep learning algorithms, does not require access to a perfect simulator of the game to achieve good performance. We show that DREAM empirically achieves state-of-the-art performance among model-free algorithms in popular benchmark games, and is even competitive with algorithms that do use a perfect simulator.
Improving Policies via Search in Cooperative Partially Observable Games
Dec 05, 2019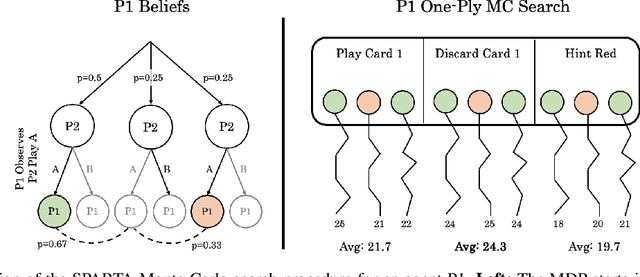
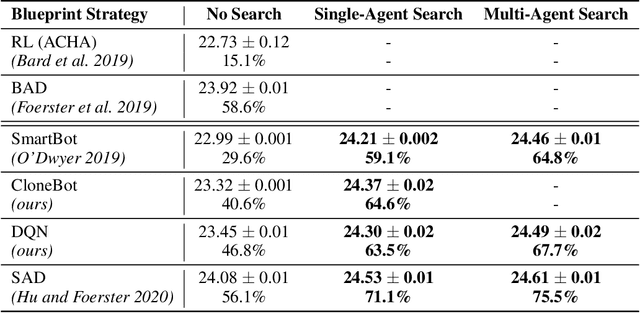
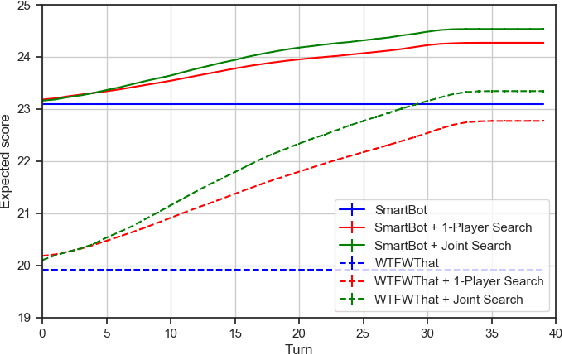
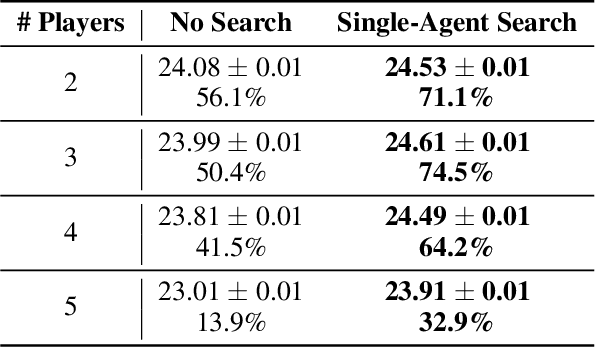
Recent superhuman results in games have largely been achieved in a variety of zero-sum settings, such as Go and Poker, in which agents need to compete against others. However, just like humans, real-world AI systems have to coordinate and communicate with other agents in cooperative partially observable environments as well. These settings commonly require participants to both interpret the actions of others and to act in a way that is informative when being interpreted. Those abilities are typically summarized as theory f mind and are seen as crucial for social interactions. In this paper we propose two different search techniques that can be applied to improve an arbitrary agreed-upon policy in a cooperative partially observable game. The first one, single-agent search, effectively converts the problem into a single agent setting by making all but one of the agents play according to the agreed-upon policy. In contrast, in multi-agent search all agents carry out the same common-knowledge search procedure whenever doing so is computationally feasible, and fall back to playing according to the agreed-upon policy otherwise. We prove that these search procedures are theoretically guaranteed to at least maintain the original performance of the agreed-upon policy (up to a bounded approximation error). In the benchmark challenge problem of Hanabi, our search technique greatly improves the performance of every agent we tested and when applied to a policy trained using RL achieves a new state-of-the-art score of 24.61 / 25 in the game, compared to a previous-best of 24.08 / 25.
Stable-Predictive Optimistic Counterfactual Regret Minimization
Feb 13, 2019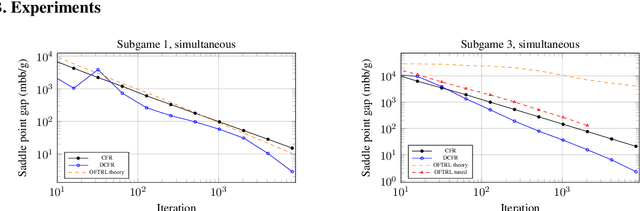
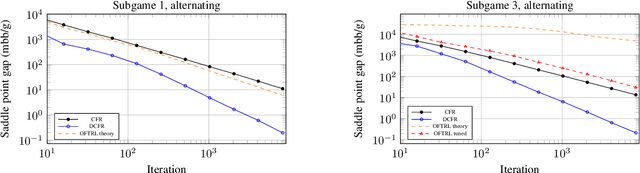
The CFR framework has been a powerful tool for solving large-scale extensive-form games in practice. However, the theoretical rate at which past CFR-based algorithms converge to the Nash equilibrium is on the order of $O(T^{-1/2})$, where $T$ is the number of iterations. In contrast, first-order methods can be used to achieve a $O(T^{-1})$ dependence on iterations, yet these methods have been less successful in practice. In this work we present the first CFR variant that breaks the square-root dependence on iterations. By combining and extending recent advances on predictive and stable regret minimizers for the matrix-game setting we show that it is possible to leverage "optimistic" regret minimizers to achieve a $O(T^{-3/4})$ convergence rate within CFR. This is achieved by introducing a new notion of stable-predictivity, and by setting the stability of each counterfactual regret minimizer relative to its location in the decision tree. Experiments show that this method is faster than the original CFR algorithm, although not as fast as newer variants, in spite of their worst-case $O(T^{-1/2})$ dependence on iterations.
Deep Counterfactual Regret Minimization
Nov 01, 2018



Counterfactual Regret Minimization (CFR) is the leading algorithm for solving large imperfect-information games. It iteratively traverses the game tree in order to converge to a Nash equilibrium. In order to deal with extremely large games, CFR typically uses domain-specific heuristics to simplify the target game in a process known as abstraction. This simplified game is solved with tabular CFR, and its solution is mapped back to the full game. This paper introduces Deep Counterfactual Regret Minimization (Deep CFR), a form of CFR that obviates the need for abstraction by instead using deep neural networks to approximate the behavior of CFR in the full game. We show that Deep CFR is principled and achieves strong performance in the benchmark game of heads-up no-limit Texas hold'em poker. This is the first successful use of function approximation in CFR for large games.
Solving Imperfect-Information Games via Discounted Regret Minimization
Sep 11, 2018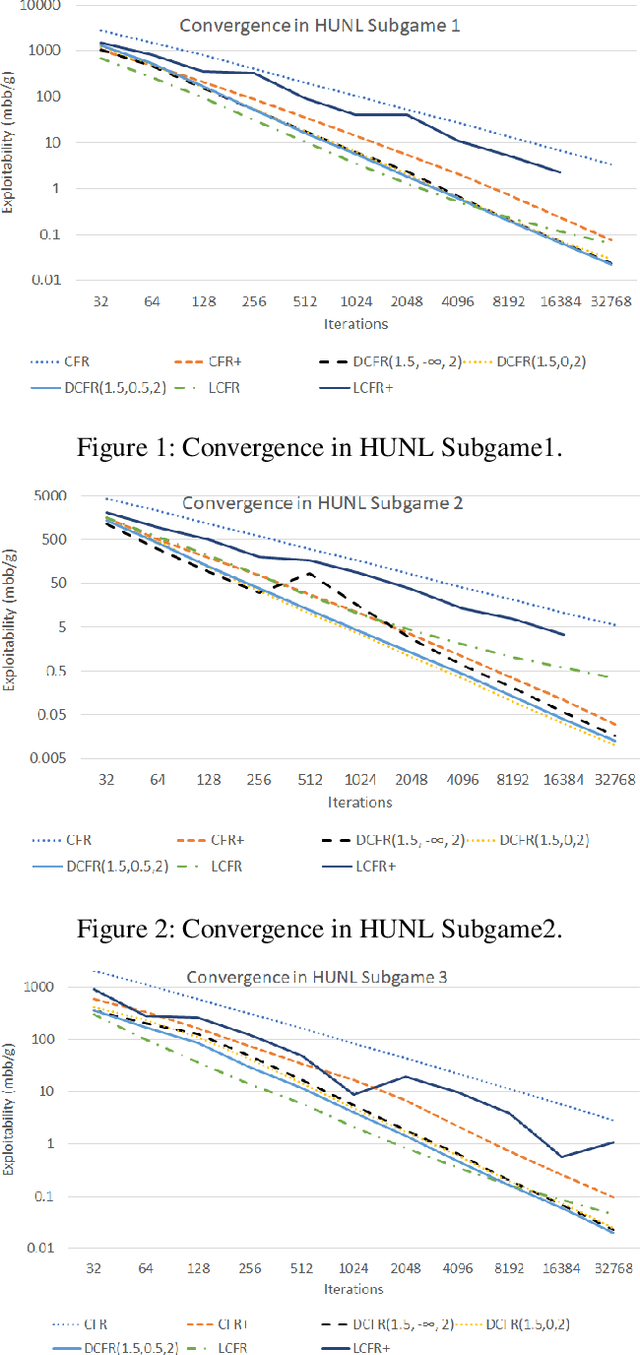
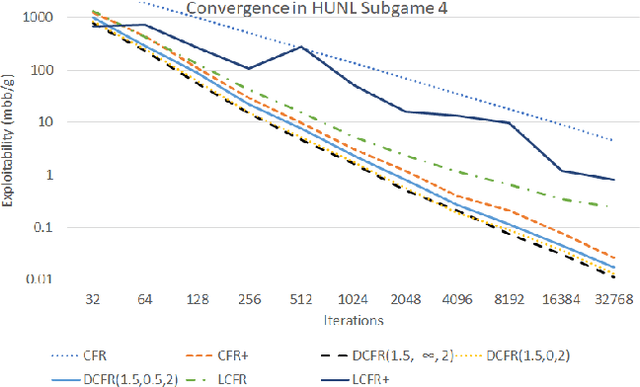
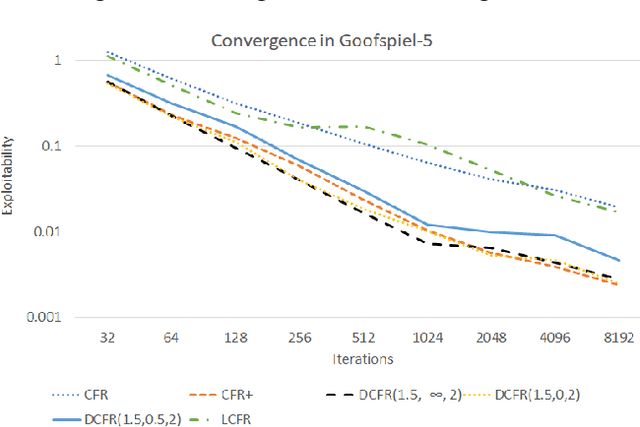
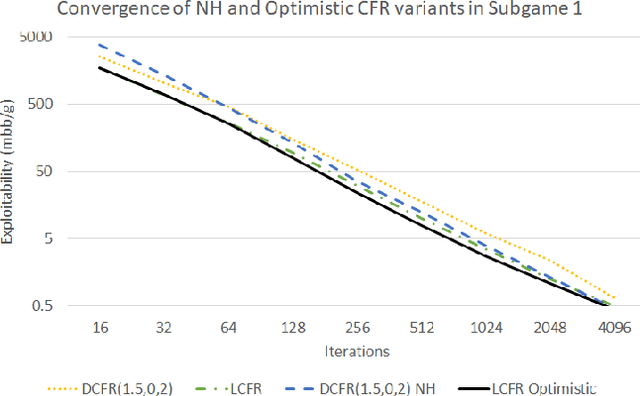
Counterfactual regret minimization (CFR) is a family of iterative algorithms that are the most popular and, in practice, fastest approach to approximately solving large imperfect-information games. In this paper we introduce novel CFR variants that 1) discount regrets from earlier iterations in various ways (in some cases differently for positive and negative regrets), 2) reweight iterations in various ways to obtain the output strategies, 3) use a non-standard regret minimizer and/or 4) leverage "optimistic regret matching". They lead to dramatically improved performance in many settings. For one, we introduce a variant that outperforms CFR+, the prior state-of-the-art algorithm, in every game tested, including large-scale realistic settings. CFR+ is a formidable benchmark: no other algorithm has been able to outperform it. Finally, we show that, unlike CFR+, many of the important new variants are compatible with modern imperfect-information-game pruning techniques and one is also compatible with sampling in the game tree.
Depth-Limited Solving for Imperfect-Information Games
May 21, 2018

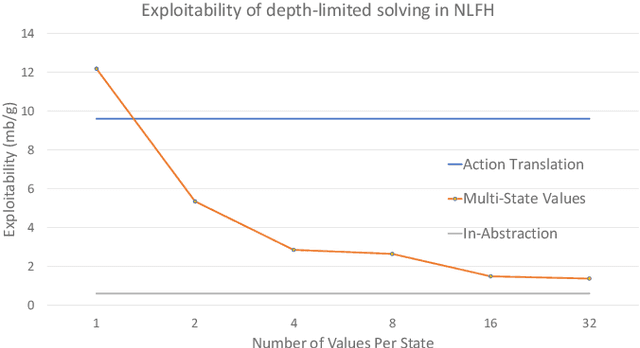
A fundamental challenge in imperfect-information games is that states do not have well-defined values. As a result, depth-limited search algorithms used in single-agent settings and perfect-information games do not apply. This paper introduces a principled way to conduct depth-limited solving in imperfect-information games by allowing the opponent to choose among a number of strategies for the remainder of the game at the depth limit. Each one of these strategies results in a different set of values for leaf nodes. This forces an agent to be robust to the different strategies an opponent may employ. We demonstrate the effectiveness of this approach by building a master-level heads-up no-limit Texas hold'em poker AI that defeats two prior top agents using only a 4-core CPU and 16 GB of memory. Developing such a powerful agent would have previously required a supercomputer.