 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Generative Models for Compositional Representation Learning
Dec 11, 2019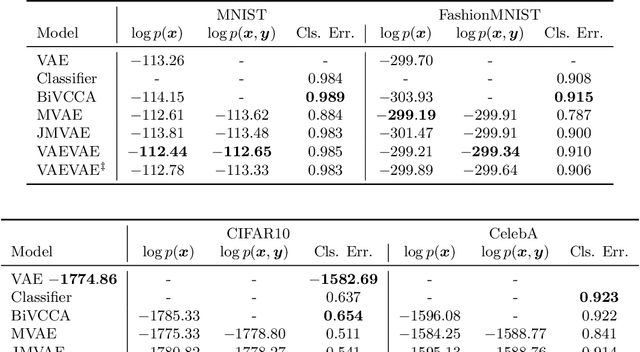
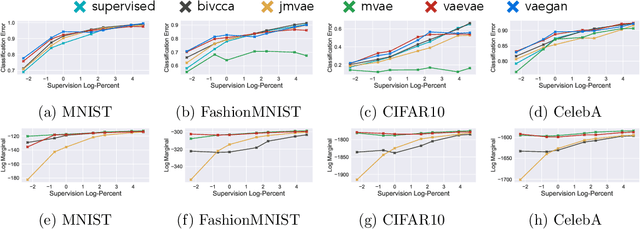
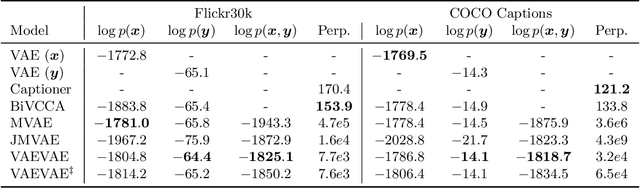
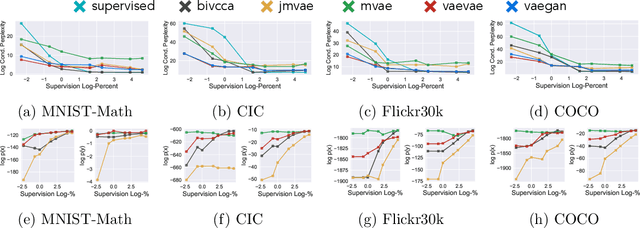
As deep neural networks become more adept at traditional tasks, many of the most exciting new challenges concern multimodality---observations that combine diverse types, such as image and text. In this paper, we introduce a family of multimodal deep generative models derived from variational bounds on the evidence (data marginal likelihood). As part of our derivation we find that many previous multimodal variational autoencoders used objectives that do not correctly bound the joint marginal likelihood across modalities. We further generalize our objective to work with several types of deep generative model (VAE, GAN, and flow-based), and allow use of different model types for different modalities. We benchmark our models across many image, label, and text datasets, and find that our multimodal VAEs excel with and without weak supervision. Additional improvements come from use of GAN image models with VAE language models. Finally, we investigate the effect of language on learned image representations through a variety of downstream tasks, such as compositionally, bounding box prediction, and visual relation prediction. We find evidence that these image representations are more abstract and compositional than equivalent representations learned from only visual data.
Shaping Visual Representations with Language for Few-shot Classification
Nov 06, 2019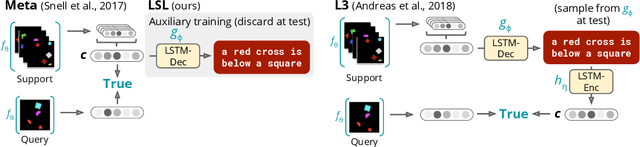
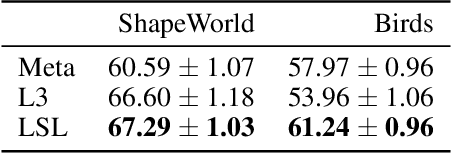

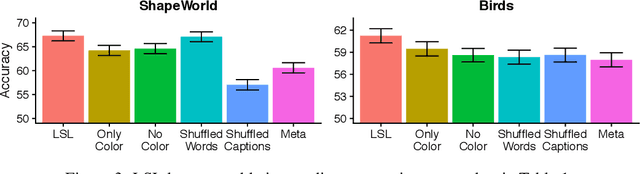
Language is designed to convey useful information about the world, thus serving as a scaffold for efficient human learning. How can we let language guide representation learning in machine learning models? We explore this question in the setting of few-shot visual classification, proposing models which learn to perform visual classification while jointly predicting natural language task descriptions at train time. At test time, with no language available, we find that these language-influenced visual representations are more generalizable, compared to meta-learning baselines and approaches that explicitly use language as a bottleneck for classification.
Generative Grading: Neural Approximate Parsing for Automated Student Feedback
May 23, 2019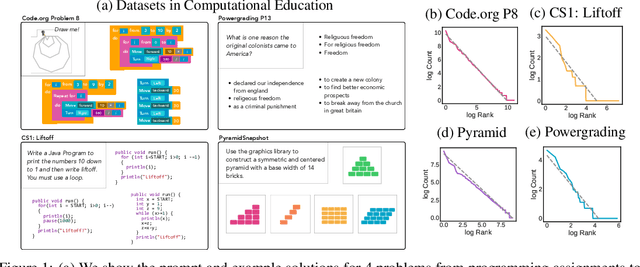

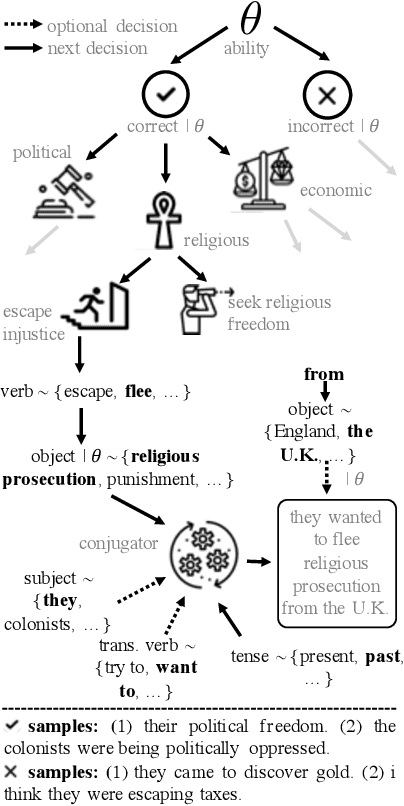
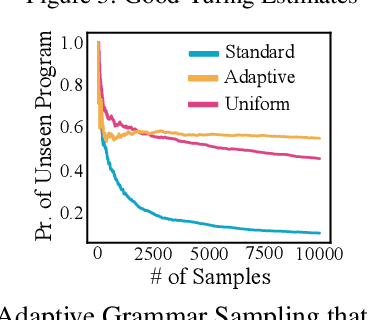
Open access to high-quality education is limited by the difficulty of providing student feedback. In this paper, we present Generative Grading with Neural Approximate Parsing (GG-NAP): a novel approach for providing feedback at scale that is capable of both accurately grading student work while also providing verifiability--a property where the model is able to substantiate its claims with a provable certificate. Our approach uses generative descriptions of student cognition, written as probabilistic programs, to synthesise millions of labelled example solutions to a problem; it then trains inference networks to approximately parse real student solutions according to these generative models. We achieve feedback prediction accuracy comparable to professional human experts in a variety of settings: short-answer questions, programs with graphical output, block-based programming, and short Java programs. In a real classroom, we ran an experiment where humans used GG-NAP to grade, yielding doubled grading accuracy while halving grading time.
Lost in Machine Translation: A Method to Reduce Meaning Loss
Apr 12, 2019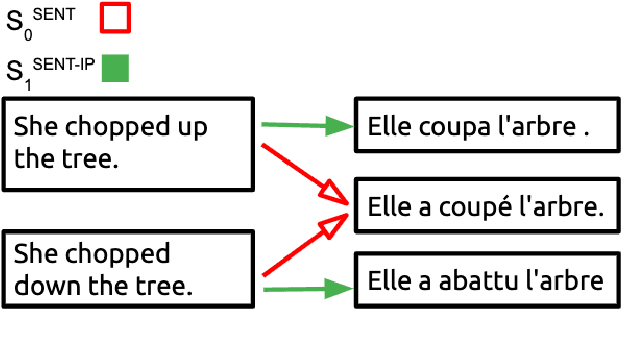
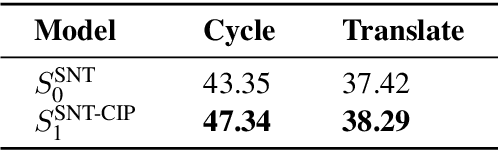

A desideratum of high-quality translation systems is that they preserve meaning, in the sense that two sentences with different meanings should not translate to one and the same sentence in another language. However, state-of-the-art systems often fail in this regard, particularly in cases where the source and target languages partition the "meaning space" in different ways. For instance, "I cut my finger." and "I cut my finger off." describe different states of the world but are translated to French (by both Fairseq and Google Translate) as "Je me suis coupe le doigt.", which is ambiguous as to whether the finger is detached. More generally, translation systems are typically many-to-one (non-injective) functions from source to target language, which in many cases results in important distinctions in meaning being lost in translation. Building on Bayesian models of informative utterance production, we present a method to define a less ambiguous translation system in terms of an underlying pre-trained neural sequence-to-sequence model. This method increases injectivity, resulting in greater preservation of meaning as measured by improvement in cycle-consistency, without impeding translation quality (measured by BLEU score).
Pragmatic inference and visual abstraction enable contextual flexibility during visual communication
Mar 28, 2019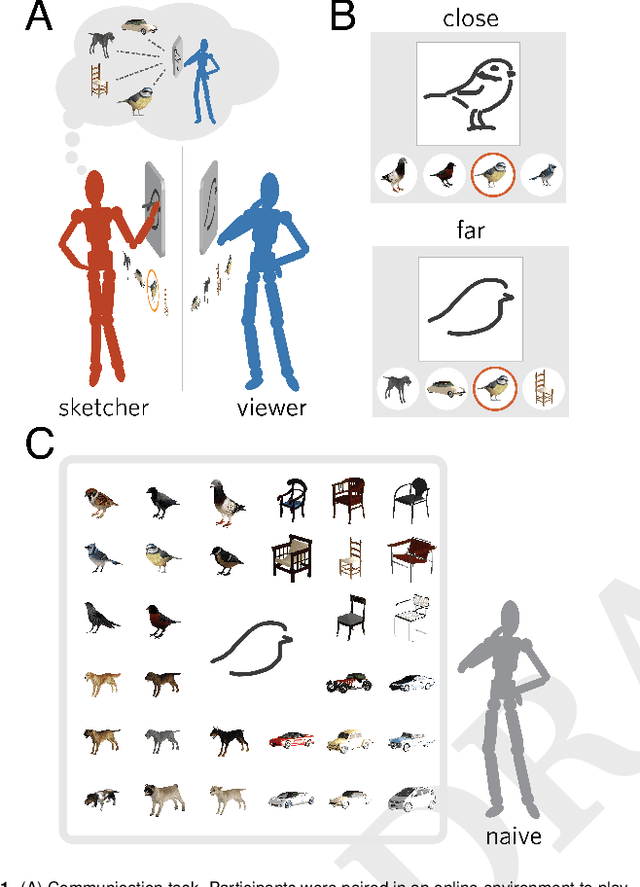
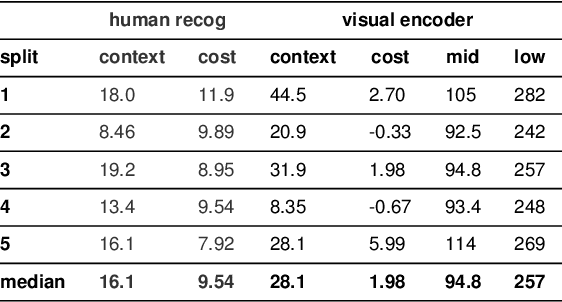
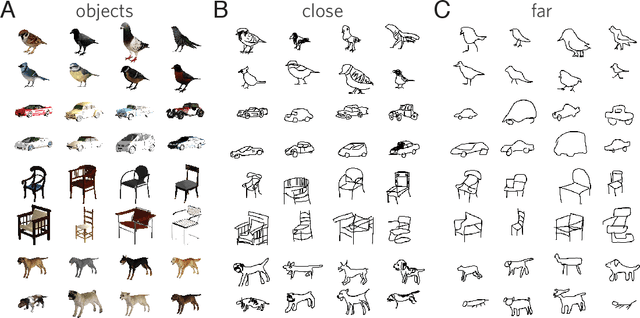
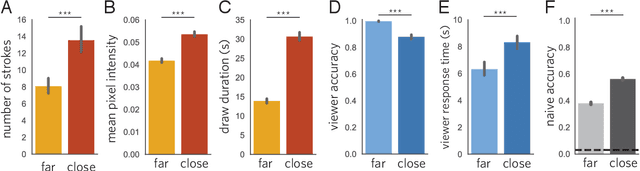
Visual modes of communication are ubiquitous in modern life --- from maps to data plots to political cartoons. Here we investigate drawing, the most basic form of visual communication. Participants were paired in an online environment to play a drawing-based reference game. On each trial, both participants were shown the same four objects, but in different locations. The sketcher's goal was to draw one of these objects so that the viewer could select it from the array. On `close' trials, objects belonged to the same basic-level category, whereas on `far' trials objects belonged to different categories. We found that people exploited shared information to efficiently communicate about the target object: on far trials, sketchers achieved high recognition accuracy while applying fewer strokes, using less ink, and spending less time on their drawings than on close trials. We hypothesized that humans succeed in this task by recruiting two core faculties: visual abstraction, the ability to perceive the correspondence between an object and a drawing of it; and pragmatic inference, the ability to judge what information would help a viewer distinguish the target from distractors. To evaluate this hypothesis, we developed a computational model of the sketcher that embodied both faculties, instantiated as a deep convolutional neural network nested within a probabilistic program. We found that this model fit human data well and outperformed lesioned variants. Together, this work provides the first algorithmically explicit theory of how visual perception and social cognition jointly support contextual flexibility in visual communication.
Variational Estimators for Bayesian Optimal Experimental Design
Mar 13, 2019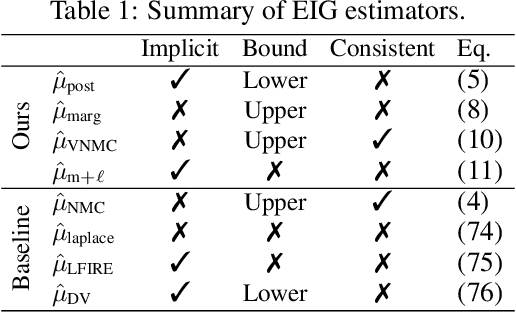
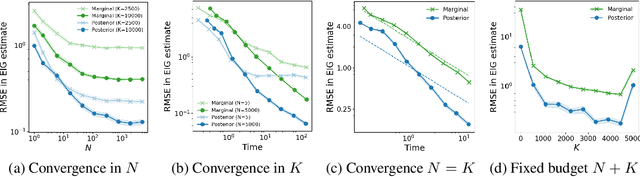
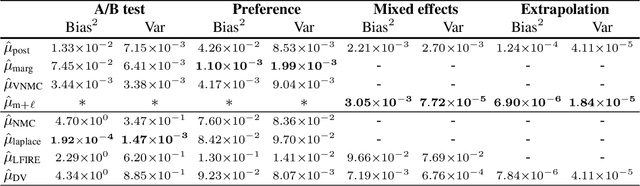
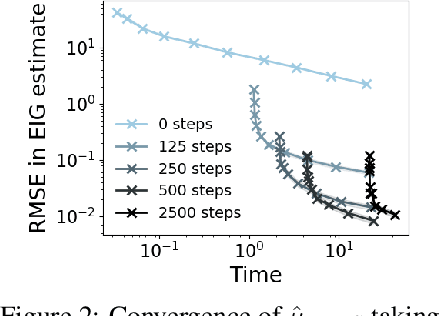
Bayesian optimal experimental design (BOED) is a principled framework for making efficient use of limited experimental resources. Unfortunately, its applicability is hampered by the difficulty of obtaining accurate estimates of the expected information gain (EIG) of an experiment. To address this, we introduce several classes of fast EIG estimators suited to the experiment design context by building on ideas from variational inference and mutual information estimation. We show theoretically and empirically that these estimators can provide significant gains in speed and accuracy over previous approaches. We demonstrate the practicality of our approach via a number of experiments, including an adaptive experiment with human participants.
Tensor Variable Elimination for Plated Factor Graphs
Feb 08, 2019
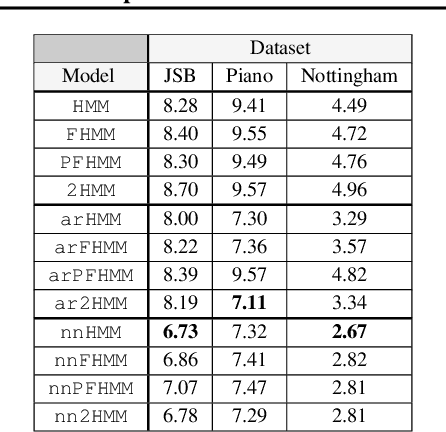
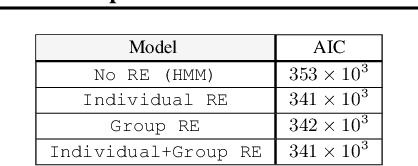
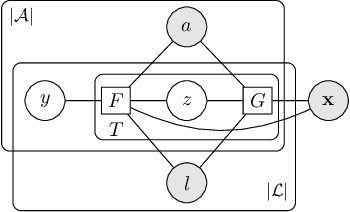
A wide class of machine learning algorithms can be reduced to variable elimination on factor graphs. While factor graphs provide a unifying notation for these algorithms, they do not provide a compact way to express repeated structure when compared to plate diagrams for directed graphical models. To exploit efficient tensor algebra in graphs with plates of variables, we generalize undirected factor graphs to plated factor graphs and variable elimination to a tensor variable elimination algorithm that operates directly on plated factor graphs. Moreover, we generalize complexity bounds based on treewidth and characterize the class of plated factor graphs for which inference is tractable. As an application, we integrate tensor variable elimination into the Pyro probabilistic programming language to enable exact inference in discrete latent variable models with repeated structure. We validate our methods with experiments on both directed and undirected graphical models, including applications to polyphonic music modeling, animal movement modeling, and latent sentiment analysis.
Meta-Amortized Variational Inference and Learning
Feb 05, 2019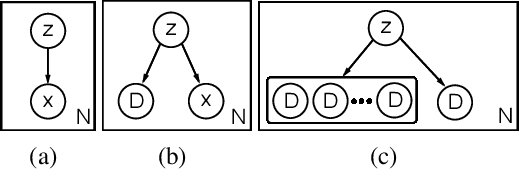

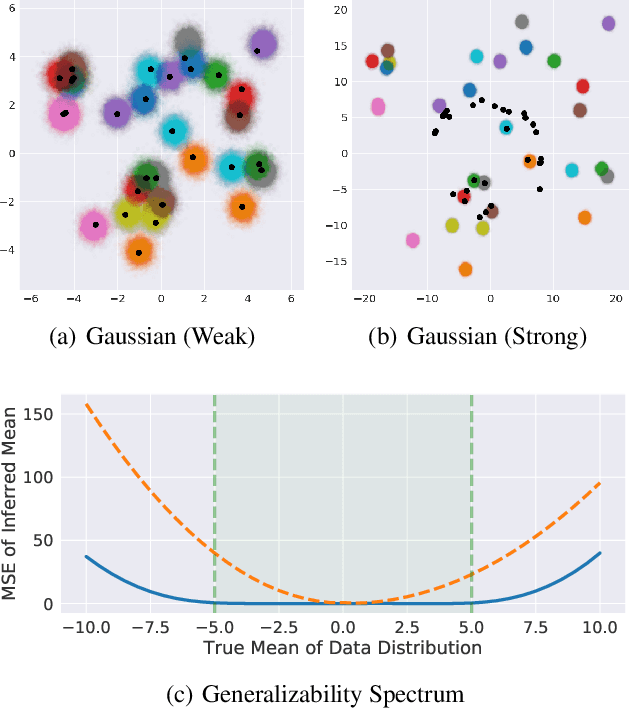
How can we learn to do probabilistic inference in a way that generalizes between models? Amortized variational inference learns for a single model, sharing statistical strength across observations. This benefits scalability and model learning, but does not help with generalization to new models. We propose meta-amortized variational inference, a framework that amortizes the cost of inference over a family of generative models. We apply this approach to deep generative models by introducing the MetaVAE: a variational autoencoder that learns to generalize to new distributions and rapidly solve new unsupervised learning problems using only a small number of target examples. Empirically, we validate the approach by showing that the MetaVAE can: (1) capture relevant sufficient statistics for inference, (2) learn useful representations of data for downstream tasks such as clustering, and (3) perform meta-density estimation on unseen synthetic distributions and out-of-sample Omniglot alphabets.
Bias and Generalization in Deep Generative Models: An Empirical Study
Nov 08, 2018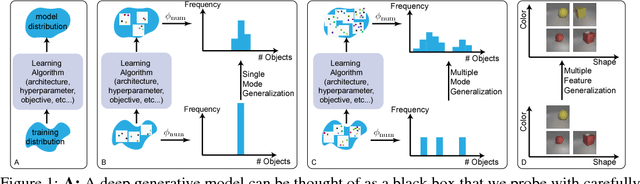

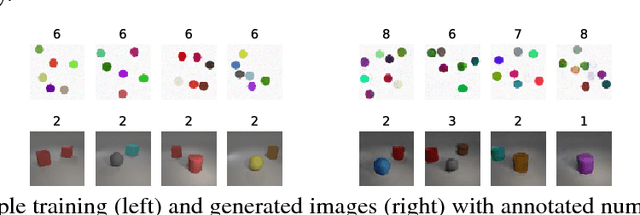
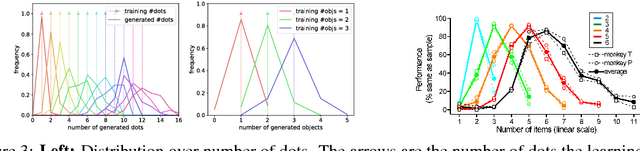
In high dimensional settings, density estimation algorithms rely crucially on their inductive bias. Despite recent empirical success, the inductive bias of deep generative models is not well understood. In this paper we propose a framework to systematically investigate bias and generalization in deep generative models of images. Inspired by experimental methods from cognitive psychology, we probe each learning algorithm with carefully designed training datasets to characterize when and how existing models generate novel attributes and their combinations. We identify similarities to human psychology and verify that these patterns are consistent across commonly used models and architectures.
Zero Shot Learning for Code Education: Rubric Sampling with Deep Learning Inference
Sep 05, 2018

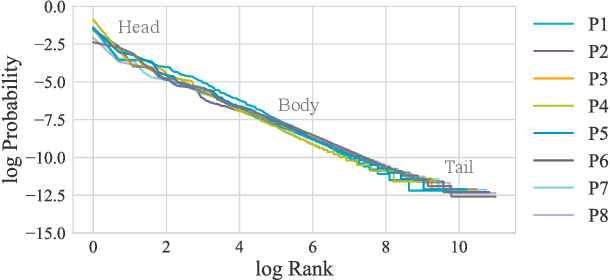

In modern computer science education, massive open online courses (MOOCs) log thousands of hours of data about how students solve coding challenges. Being so rich in data, these platforms have garnered the interest of the machine learning community, with many new algorithms attempting to autonomously provide feedback to help future students learn. But what about those first hundred thousand students? In most educational contexts (i.e. classrooms), assignments do not have enough historical data for supervised learning. In this paper, we introduce a human-in-the-loop "rubric sampling" approach to tackle the "zero shot" feedback challenge. We are able to provide autonomous feedback for the first students working on an introductory programming assignment with accuracy that substantially outperforms data-hungry algorithms and approaches human level fidelity. Rubric sampling requires minimal teacher effort, can associate feedback with specific parts of a student's solution and can articulate a student's misconceptions in the language of the instructor. Deep learning inference enables rubric sampling to further improve as more assignment specific student data is acquired. We demonstrate our results on a novel dataset from Code.org, the world's largest programming education platform.