 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSinhala Sentence Embedding: A Two-Tiered Structure for Low-Resource Languages
Oct 26, 2022



In the process of numerically modeling natural languages, developing language embeddings is a vital step. However, it is challenging to develop functional embeddings for resource-poor languages such as Sinhala, for which sufficiently large corpora, effective language parsers, and any other required resources are difficult to find. In such conditions, the exploitation of existing models to come up with an efficacious embedding methodology to numerically represent text could be quite fruitful. This paper explores the effectivity of several one-tiered and two-tiered embedding architectures in representing Sinhala text in the sentiment analysis domain. With our findings, the two-tiered embedding architecture where the lower-tier consists of a word embedding and the upper-tier consists of a sentence embedding has been proven to perform better than one-tier word embeddings, by achieving a maximum F1 score of 88.04% in contrast to the 83.76% achieved by word embedding models. Furthermore, embeddings in the hyperbolic space are also developed and compared with Euclidean embeddings in terms of performance. A sentiment data set consisting of Facebook posts and associated reactions have been used for this research. To effectively compare the performance of different embedding systems, the same deep neural network structure has been trained on sentiment data with each of the embedding systems used to encode the text associated.
Some Languages are More Equal than Others: Probing Deeper into the Linguistic Disparity in the NLP World
Oct 20, 2022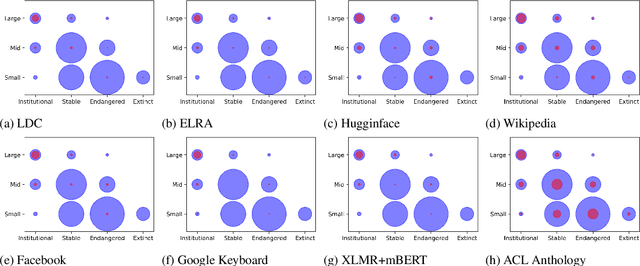
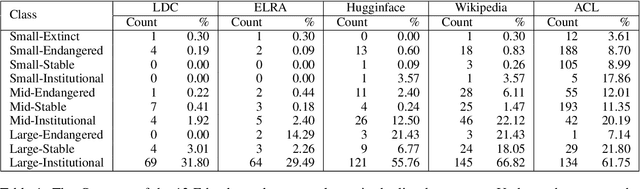
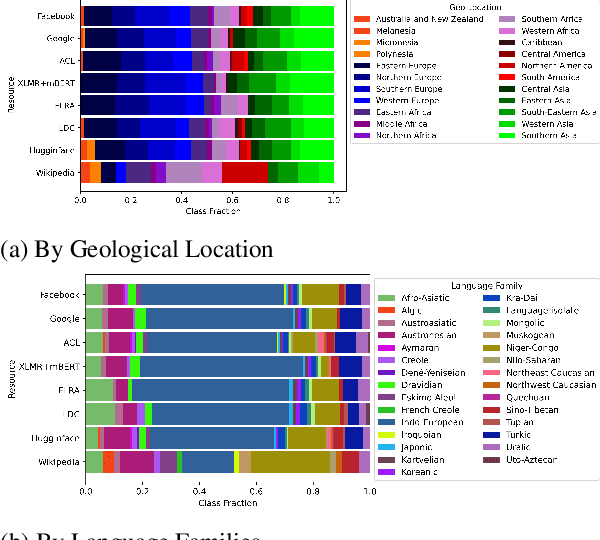
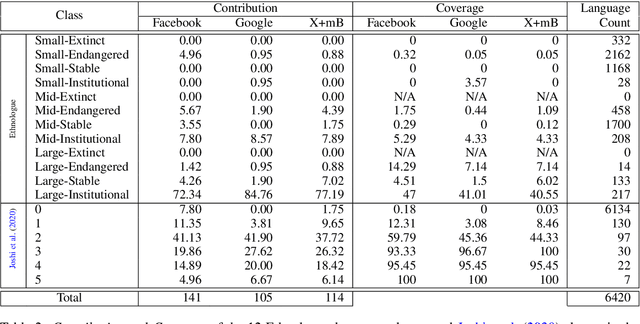
Linguistic disparity in the NLP world is a problem that has been widely acknowledged recently. However, different facets of this problem, or the reasons behind this disparity are seldom discussed within the NLP community. This paper provides a comprehensive analysis of the disparity that exists within the languages of the world. We show that simply categorising languages considering data availability may not be always correct. Using an existing language categorisation based on speaker population and vitality, we analyse the distribution of language data resources, amount of NLP/CL research, inclusion in multilingual web-based platforms and the inclusion in pre-trained multilingual models. We show that many languages do not get covered in these resources or platforms, and even within the languages belonging to the same language group, there is wide disparity. We analyse the impact of family, geographical location, GDP and the speaker population of languages and provide possible reasons for this disparity, along with some suggestions to overcome the same.
Selecting Seed Words for Wordle using Character Statistics
Feb 09, 2022
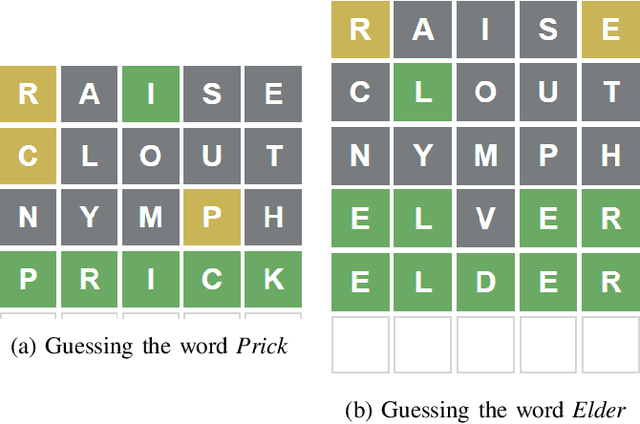
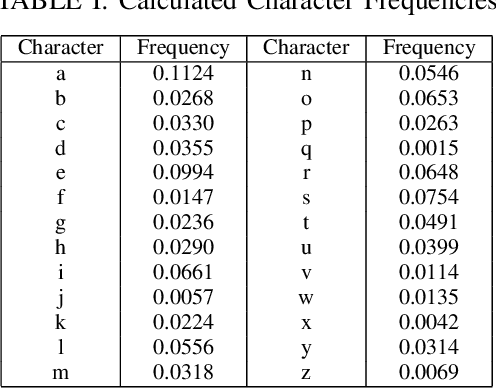
Wordle, a word guessing game rose to global popularity in the January of 2022. The goal of the game is to guess a five-letter English word within six tries. Each try provides the player with hints by means of colour changing tiles which inform whether or not a given character is part of the solution as well as, in cases where it is part of the solution, whether or not it is in the correct placement. Numerous attempts have been made to find the best starting word and best strategy to solve the daily wordle. This study uses character statistics of five-letter words to determine the best three starting words.
Sentiment Analysis with Deep Learning Models: A Comparative Study on a Decade of Sinhala Language Facebook Data
Jan 14, 2022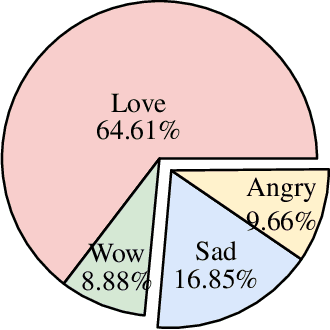
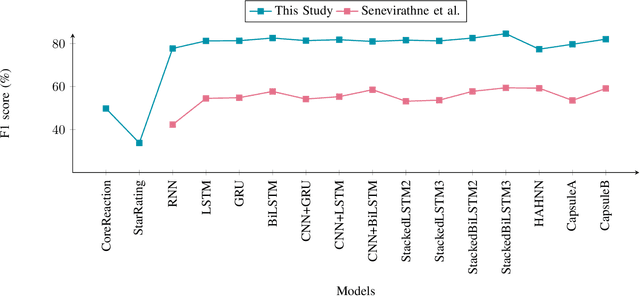
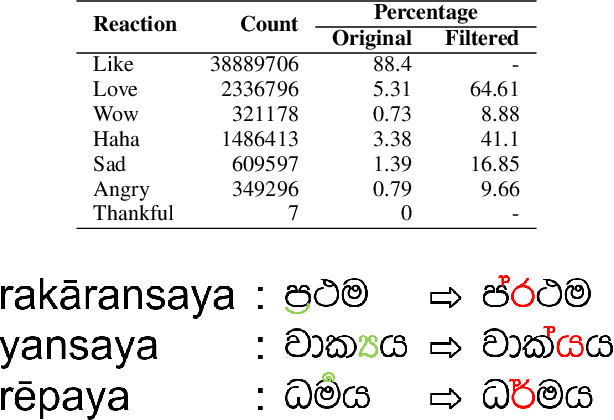
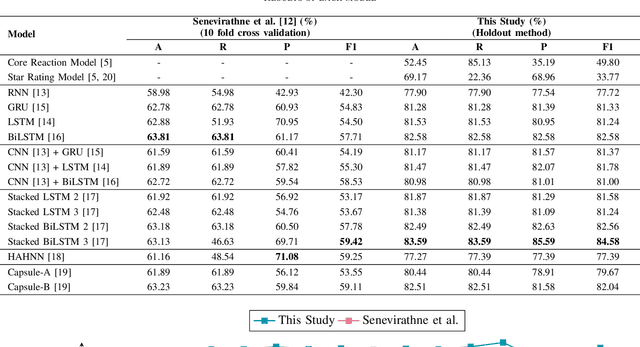
The relationship between Facebook posts and the corresponding reaction feature is an interesting subject to explore and understand. To achieve this end, we test state-of-the-art Sinhala sentiment analysis models against a data set containing a decade worth of Sinhala posts with millions of reactions. For the purpose of establishing benchmarks and with the goal of identifying the best model for Sinhala sentiment analysis, we also test, on the same data set configuration, other deep learning models catered for sentiment analysis. In this study we report that the 3 layer Bidirectional LSTM model achieves an F1 score of 84.58% for Sinhala sentiment analysis, surpassing the current state-of-the-art model; Capsule B, which only manages to get an F1 score of 82.04%. Further, since all the deep learning models show F1 scores above 75% we conclude that it is safe to claim that Facebook reactions are suitable to predict the sentiment of a text.
Seeking Sinhala Sentiment: Predicting Facebook Reactions of Sinhala Posts
Dec 01, 2021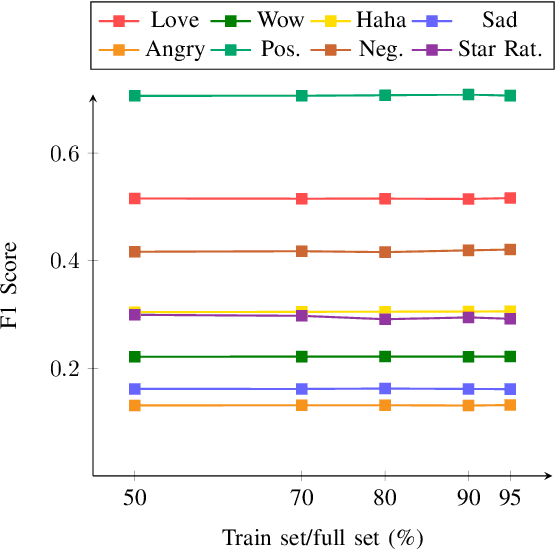
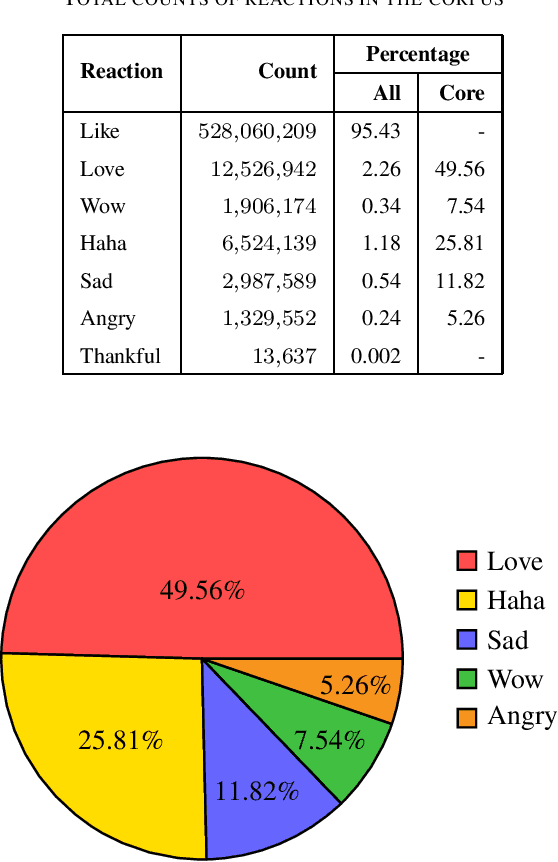
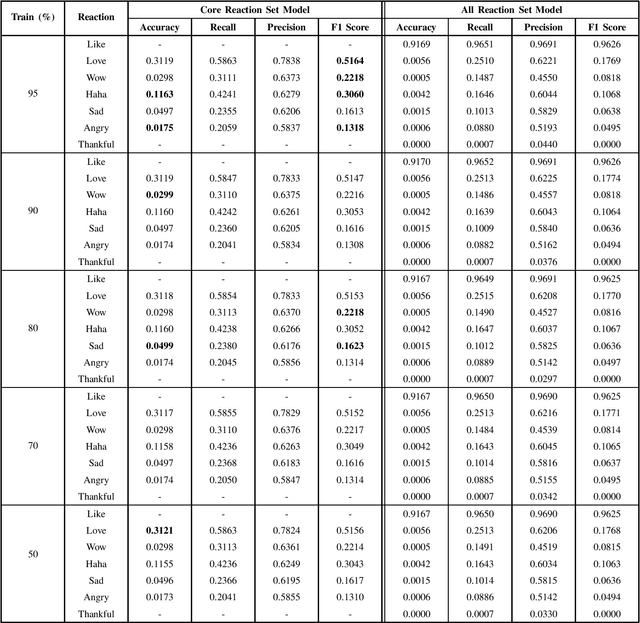

The Facebook network allows its users to record their reactions to text via a typology of emotions. This network, taken at scale, is therefore a prime data set of annotated sentiment data. This paper uses millions of such reactions, derived from a decade worth of Facebook post data centred around a Sri Lankan context, to model an eye of the beholder approach to sentiment detection for online Sinhala textual content. Three different sentiment analysis models are built, taking into account a limited subset of reactions, all reactions, and another that derives a positive/negative star rating value. The efficacy of these models in capturing the reactions of the observers are then computed and discussed. The analysis reveals that binary classification of reactions, for Sinhala content, is significantly more accurate than the other approaches. Furthermore, the inclusion of the like reaction hinders the capability of accurately predicting other reactions.
Critical Sentence Identification in Legal Cases Using Multi-Class Classification
Nov 14, 2021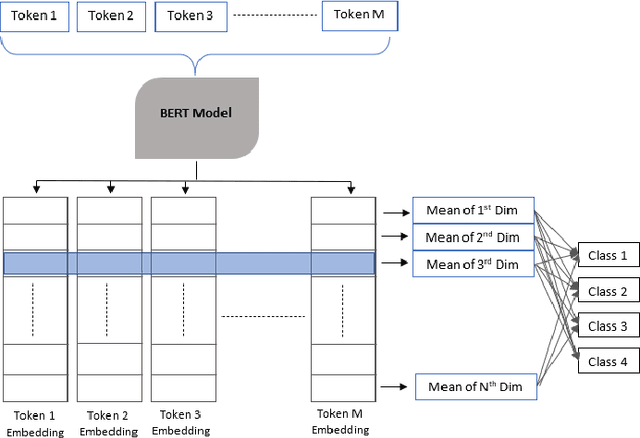
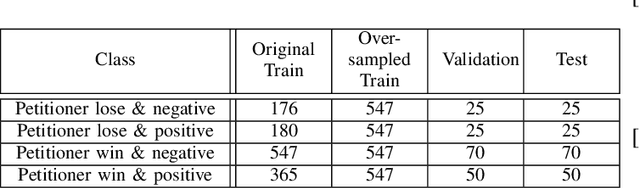
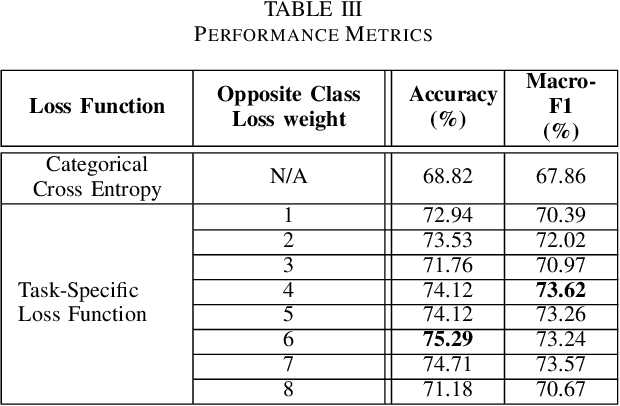
Inherently, the legal domain contains a vast amount of data in text format. Therefore it requires the application of Natural Language Processing (NLP) to cater to the analytically demanding needs of the domain. The advancement of NLP is spreading through various domains, such as the legal domain, in forms of practical applications and academic research. Identifying critical sentences, facts and arguments in a legal case is a tedious task for legal professionals. In this research we explore the usage of sentence embeddings for multi-class classification to identify critical sentences in a legal case, in the perspective of the main parties present in the case. In addition, a task-specific loss function is defined in order to improve the accuracy restricted by the straightforward use of categorical cross entropy loss.
Quality at a Glance: An Audit of Web-Crawled Multilingual Datasets
Mar 22, 2021
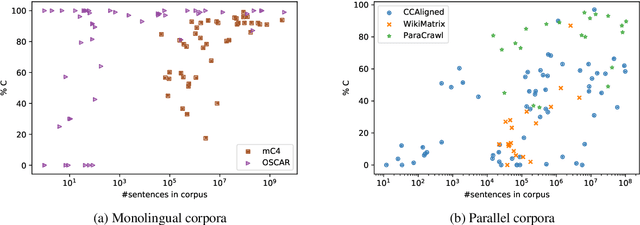

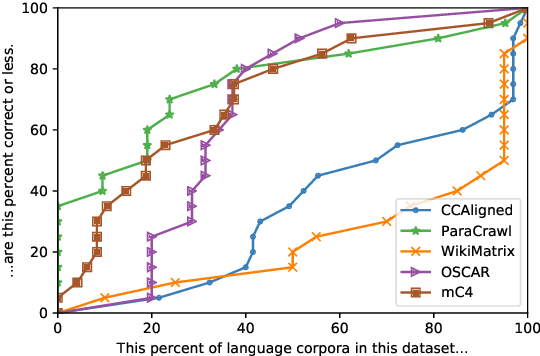
With the success of large-scale pre-training and multilingual modeling in Natural Language Processing (NLP), recent years have seen a proliferation of large, web-mined text datasets covering hundreds of languages. However, to date there has been no systematic analysis of the quality of these publicly available datasets, or whether the datasets actually contain content in the languages they claim to represent. In this work, we manually audit the quality of 205 language-specific corpora released with five major public datasets (CCAligned, ParaCrawl, WikiMatrix, OSCAR, mC4), and audit the correctness of language codes in a sixth (JW300). We find that lower-resource corpora have systematic issues: at least 15 corpora are completely erroneous, and a significant fraction contains less than 50% sentences of acceptable quality. Similarly, we find 82 corpora that are mislabeled or use nonstandard/ambiguous language codes. We demonstrate that these issues are easy to detect even for non-speakers of the languages in question, and supplement the human judgements with automatic analyses. Inspired by our analysis, we recommend techniques to evaluate and improve multilingual corpora and discuss the risks that come with low-quality data releases.
Rule-Based Approach for Party-Based Sentiment Analysis in Legal Opinion Texts
Nov 13, 2020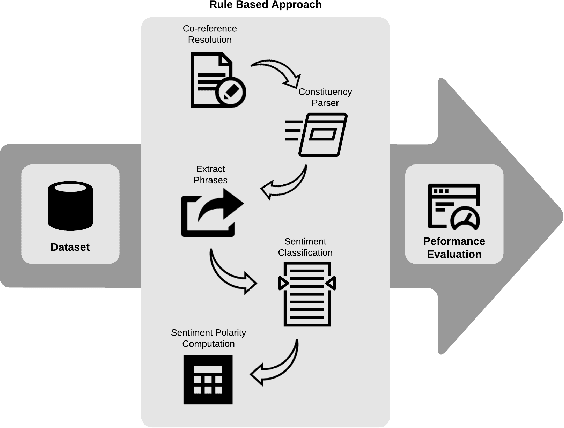
A document which elaborates opinions and arguments related to the previous court cases is known as a legal opinion text. Lawyers and legal officials have to spend considerable effort and time to obtain the required information manually from those documents when dealing with new legal cases. Hence, it provides much convenience to those individuals if there is a way to automate the process of extracting information from legal opinion texts. Party-based sentiment analysis will play a key role in the automation system by identifying opinion values with respect to each legal parties in legal texts.
SigmaLaw-ABSA: Dataset for Aspect-Based Sentiment Analysis in Legal Opinion Texts
Nov 12, 2020
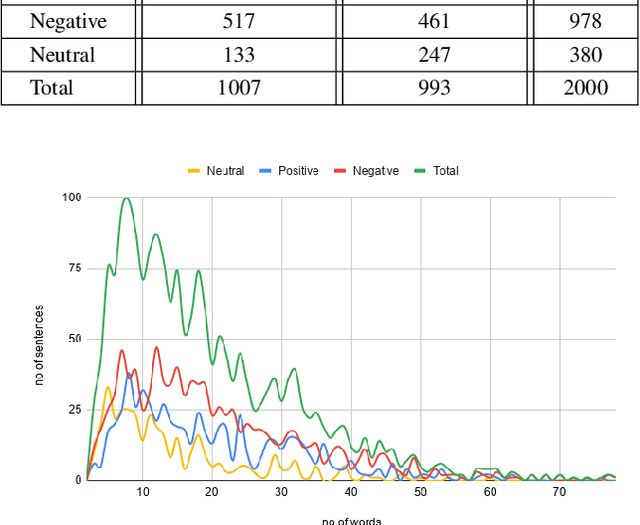
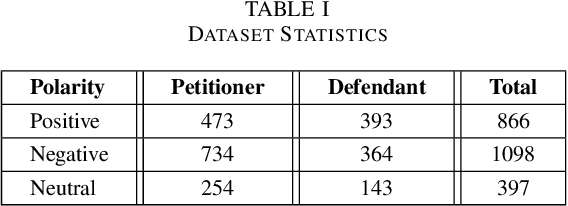
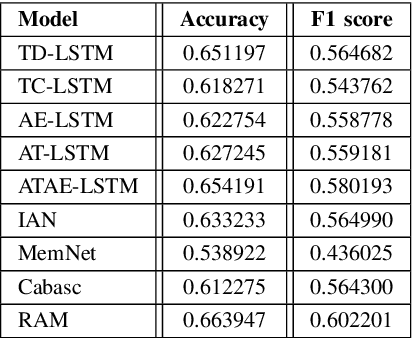
Aspect-Based Sentiment Analysis (ABSA) has been prominent and ongoing research over many different domains, but it is not widely discussed in the legal domain. A number of publicly available datasets for a wide range of domains usually fulfill the needs of researchers to perform their studies in the field of ABSA. To the best of our knowledge, there is no publicly available dataset for the Aspect (Party) Based Sentiment Analysis for legal opinion texts. Therefore, creating a publicly available dataset for the research of ABSA for the legal domain can be considered as a task with significant importance. In this study, we introduce a manually annotated legal opinion text dataset (SigmaLaw-ABSA) intended towards facilitating researchers for ABSA tasks in the legal domain. SigmaLaw-ABSA consists of legal opinion texts in the English language which have been annotated by human judges. This study discusses the sub-tasks of ABSA relevant to the legal domain and how to use the dataset to perform them. This paper also describes the statistics of the dataset and as a baseline, we present some results on the performance of some existing deep learning based systems on the SigmaLaw-ABSA dataset.
Effective Approach to Develop a Sentiment Annotator For Legal Domain in a Low Resource Setting
Oct 31, 2020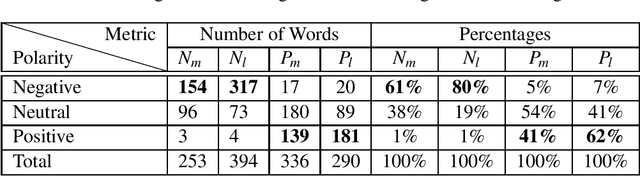
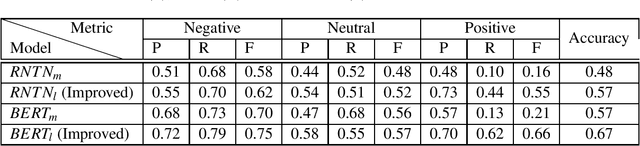
Analyzing the sentiments of legal opinions available in Legal Opinion Texts can facilitate several use cases such as legal judgement prediction, contradictory statements identification and party-based sentiment analysis. However, the task of developing a legal domain specific sentiment annotator is challenging due to resource constraints such as lack of domain specific labelled data and domain expertise. In this study, we propose novel techniques that can be used to develop a sentiment annotator for the legal domain while minimizing the need for manual annotations of data.