 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter Question-Answering Models on a Budget
Apr 24, 2023Low-rank adaptation (LoRA) and question-answer datasets from large language models have made it much easier for much smaller models to be finetuned to the point where they display sophisticated conversational abilities. In this paper, we present Eluwa, a family of LoRA models that use the Stanford Alpaca dataset and massively improve the capabilities of Facebook's OPT 1.3B, 2.7B and 6.7B models. We benchmark these models in multiple ways, including letting GPT-4 judge their answers to prompts that span general knowledge, writing, programming and other tasks. We show that smaller models here can be fine-tuned to be as performant as models 3x larger - all for as little as 40 USD in compute.
Sinhala Sentence Embedding: A Two-Tiered Structure for Low-Resource Languages
Oct 26, 2022



In the process of numerically modeling natural languages, developing language embeddings is a vital step. However, it is challenging to develop functional embeddings for resource-poor languages such as Sinhala, for which sufficiently large corpora, effective language parsers, and any other required resources are difficult to find. In such conditions, the exploitation of existing models to come up with an efficacious embedding methodology to numerically represent text could be quite fruitful. This paper explores the effectivity of several one-tiered and two-tiered embedding architectures in representing Sinhala text in the sentiment analysis domain. With our findings, the two-tiered embedding architecture where the lower-tier consists of a word embedding and the upper-tier consists of a sentence embedding has been proven to perform better than one-tier word embeddings, by achieving a maximum F1 score of 88.04% in contrast to the 83.76% achieved by word embedding models. Furthermore, embeddings in the hyperbolic space are also developed and compared with Euclidean embeddings in terms of performance. A sentiment data set consisting of Facebook posts and associated reactions have been used for this research. To effectively compare the performance of different embedding systems, the same deep neural network structure has been trained on sentiment data with each of the embedding systems used to encode the text associated.
Sentiment Analysis with Deep Learning Models: A Comparative Study on a Decade of Sinhala Language Facebook Data
Jan 14, 2022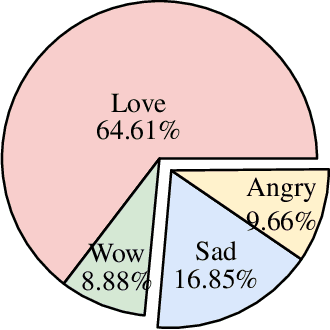
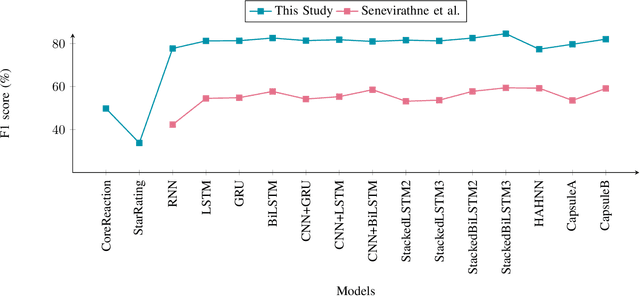
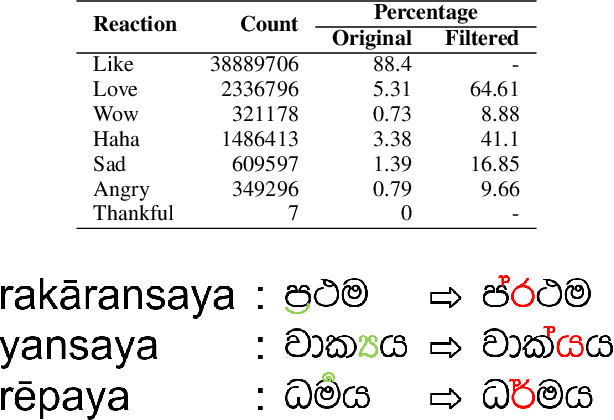
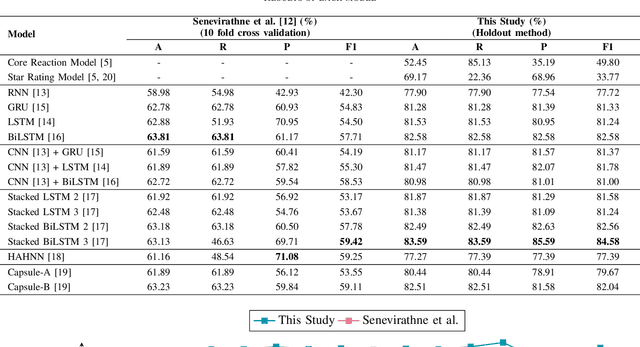
The relationship between Facebook posts and the corresponding reaction feature is an interesting subject to explore and understand. To achieve this end, we test state-of-the-art Sinhala sentiment analysis models against a data set containing a decade worth of Sinhala posts with millions of reactions. For the purpose of establishing benchmarks and with the goal of identifying the best model for Sinhala sentiment analysis, we also test, on the same data set configuration, other deep learning models catered for sentiment analysis. In this study we report that the 3 layer Bidirectional LSTM model achieves an F1 score of 84.58% for Sinhala sentiment analysis, surpassing the current state-of-the-art model; Capsule B, which only manages to get an F1 score of 82.04%. Further, since all the deep learning models show F1 scores above 75% we conclude that it is safe to claim that Facebook reactions are suitable to predict the sentiment of a text.
Seeking Sinhala Sentiment: Predicting Facebook Reactions of Sinhala Posts
Dec 01, 2021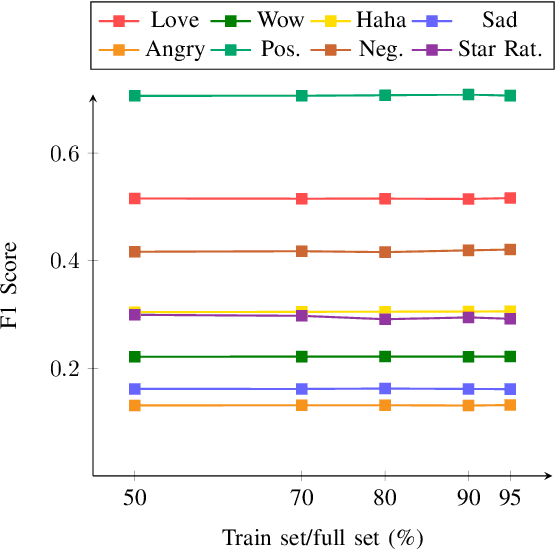
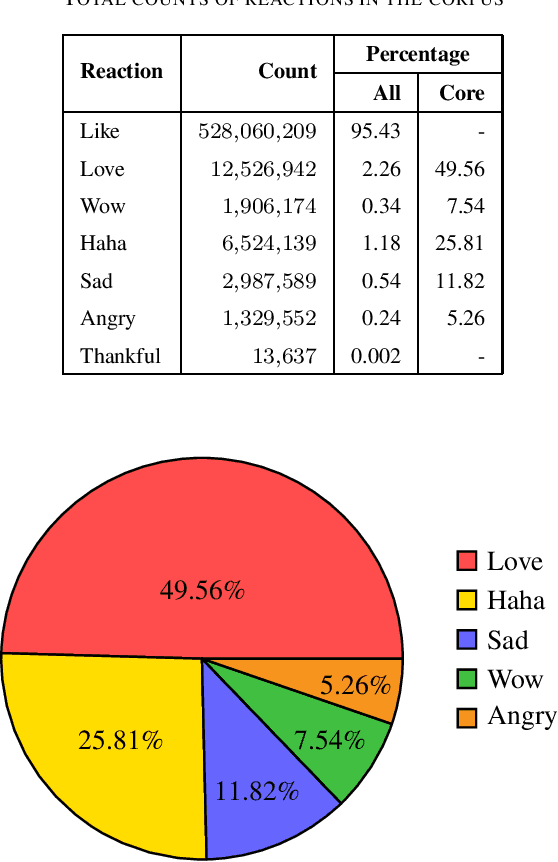
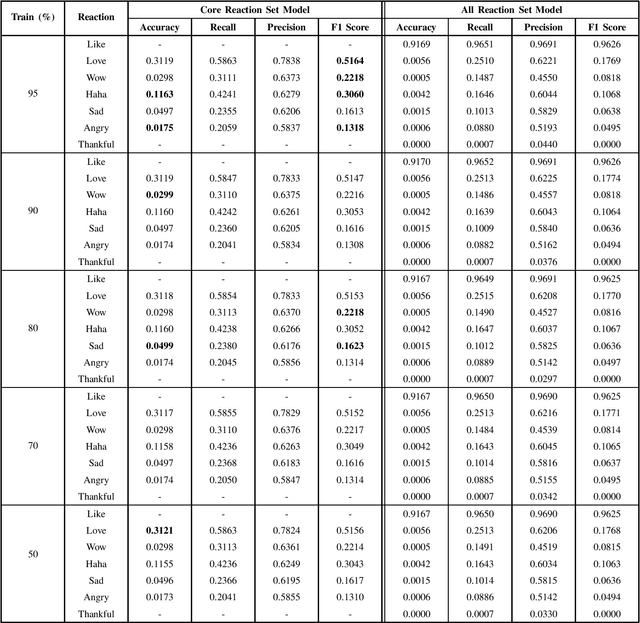

The Facebook network allows its users to record their reactions to text via a typology of emotions. This network, taken at scale, is therefore a prime data set of annotated sentiment data. This paper uses millions of such reactions, derived from a decade worth of Facebook post data centred around a Sri Lankan context, to model an eye of the beholder approach to sentiment detection for online Sinhala textual content. Three different sentiment analysis models are built, taking into account a limited subset of reactions, all reactions, and another that derives a positive/negative star rating value. The efficacy of these models in capturing the reactions of the observers are then computed and discussed. The analysis reveals that binary classification of reactions, for Sinhala content, is significantly more accurate than the other approaches. Furthermore, the inclusion of the like reaction hinders the capability of accurately predicting other reactions.
Sinhala Language Corpora and Stopwords from a Decade of Sri Lankan Facebook
Jul 15, 2020

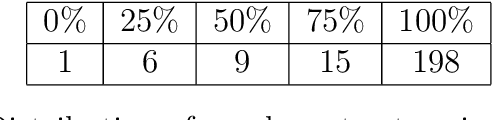
This paper presents two colloquial Sinhala language corpora from the language efforts of the Data, Analysis and Policy team of LIRNEasia, as well as a list of algorithmically derived stopwords. The larger of the two corpora spans 2010 to 2020 and contains 28,825,820 to 29,549,672 words of multilingual text posted by 533 Sri Lankan Facebook pages, including politics, media, celebrities, and other categories; the smaller corpus amounts to 5,402,76 words of only Sinhala text extracted from the larger. Both corpora have markers for their date of creation, page of origin, and content type.