 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdgeTran: Co-designing Transformers for Efficient Inference on Mobile Edge Platforms
Mar 24, 2023Automated design of efficient transformer models has recently attracted significant attention from industry and academia. However, most works only focus on certain metrics while searching for the best-performing transformer architecture. Furthermore, running traditional, complex, and large transformer models on low-compute edge platforms is a challenging problem. In this work, we propose a framework, called ProTran, to profile the hardware performance measures for a design space of transformer architectures and a diverse set of edge devices. We use this profiler in conjunction with the proposed co-design technique to obtain the best-performing models that have high accuracy on the given task and minimize latency, energy consumption, and peak power draw to enable edge deployment. We refer to our framework for co-optimizing accuracy and hardware performance measures as EdgeTran. It searches for the best transformer model and edge device pair. Finally, we propose GPTran, a multi-stage block-level grow-and-prune post-processing step that further improves accuracy in a hardware-aware manner. The obtained transformer model is 2.8$\times$ smaller and has a 0.8% higher GLUE score than the baseline (BERT-Base). Inference with it on the selected edge device enables 15.0% lower latency, 10.0$\times$ lower energy, and 10.8$\times$ lower peak power draw compared to an off-the-shelf GPU.
AccelTran: A Sparsity-Aware Accelerator for Dynamic Inference with Transformers
Feb 28, 2023Self-attention-based transformer models have achieved tremendous success in the domain of natural language processing. Despite their efficacy, accelerating the transformer is challenging due to its quadratic computational complexity and large activation sizes. Existing transformer accelerators attempt to prune its tokens to reduce memory access, albeit with high compute overheads. Moreover, previous works directly operate on large matrices involved in the attention operation, which limits hardware utilization. In order to address these challenges, this work proposes a novel dynamic inference scheme, DynaTran, which prunes activations at runtime with low overhead, substantially reducing the number of ineffectual operations. This improves the throughput of transformer inference. We further propose tiling the matrices in transformer operations along with diverse dataflows to improve data reuse, thus enabling higher energy efficiency. To effectively implement these methods, we propose AccelTran, a novel accelerator architecture for transformers. Extensive experiments with different models and benchmarks demonstrate that DynaTran achieves higher accuracy than the state-of-the-art top-k hardware-aware pruning strategy while attaining up to 1.2$\times$ higher sparsity. One of our proposed accelerators, AccelTran-Edge, achieves 330K$\times$ higher throughput with 93K$\times$ lower energy requirement when compared to a Raspberry Pi device. On the other hand, AccelTran-Server achieves 5.73$\times$ higher throughput and 3.69$\times$ lower energy consumption compared to the state-of-the-art transformer co-processor, Energon.
CODEBench: A Neural Architecture and Hardware Accelerator Co-Design Framework
Dec 07, 2022Recently, automated co-design of machine learning (ML) models and accelerator architectures has attracted significant attention from both the industry and academia. However, most co-design frameworks either explore a limited search space or employ suboptimal exploration techniques for simultaneous design decision investigations of the ML model and the accelerator. Furthermore, training the ML model and simulating the accelerator performance is computationally expensive. To address these limitations, this work proposes a novel neural architecture and hardware accelerator co-design framework, called CODEBench. It is composed of two new benchmarking sub-frameworks, CNNBench and AccelBench, which explore expanded design spaces of convolutional neural networks (CNNs) and CNN accelerators. CNNBench leverages an advanced search technique, BOSHNAS, to efficiently train a neural heteroscedastic surrogate model to converge to an optimal CNN architecture by employing second-order gradients. AccelBench performs cycle-accurate simulations for a diverse set of accelerator architectures in a vast design space. With the proposed co-design method, called BOSHCODE, our best CNN-accelerator pair achieves 1.4% higher accuracy on the CIFAR-10 dataset compared to the state-of-the-art pair, while enabling 59.1% lower latency and 60.8% lower energy consumption. On the ImageNet dataset, it achieves 3.7% higher Top1 accuracy at 43.8% lower latency and 11.2% lower energy consumption. CODEBench outperforms the state-of-the-art framework, i.e., Auto-NBA, by achieving 1.5% higher accuracy and 34.7x higher throughput, while enabling 11.0x lower energy-delay product (EDP) and 4.0x lower chip area on CIFAR-10.
CTRL: Clustering Training Losses for Label Error Detection
Aug 17, 2022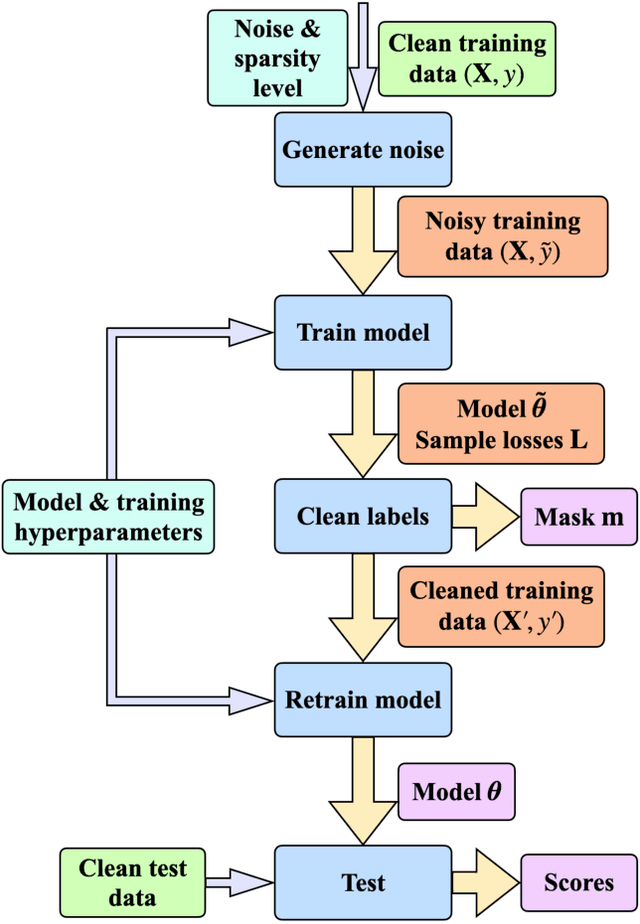
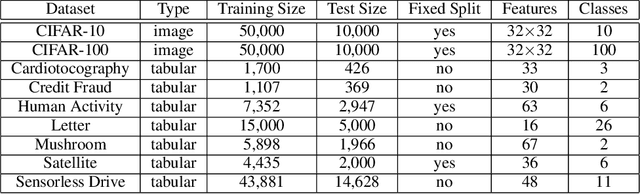
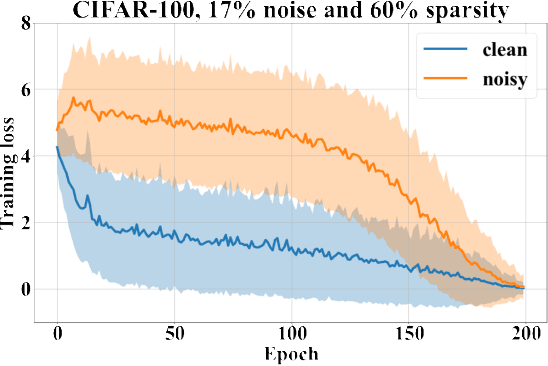
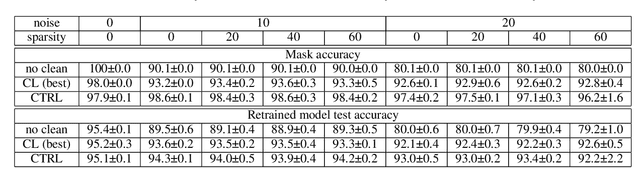
In supervised machine learning, use of correct labels is extremely important to ensure high accuracy. Unfortunately, most datasets contain corrupted labels. Machine learning models trained on such datasets do not generalize well. Thus, detecting their label errors can significantly increase their efficacy. We propose a novel framework, called CTRL (Clustering TRaining Losses for label error detection), to detect label errors in multi-class datasets. It detects label errors in two steps based on the observation that models learn clean and noisy labels in different ways. First, we train a neural network using the noisy training dataset and obtain the loss curve for each sample. Then, we apply clustering algorithms to the training losses to group samples into two categories: cleanly-labeled and noisily-labeled. After label error detection, we remove samples with noisy labels and retrain the model. Our experimental results demonstrate state-of-the-art error detection accuracy on both image (CIFAR-10 and CIFAR-100) and tabular datasets under simulated noise. We also use a theoretical analysis to provide insights into why CTRL performs so well.
SCouT: Synthetic Counterfactuals via Spatiotemporal Transformers for Actionable Healthcare
Jul 09, 2022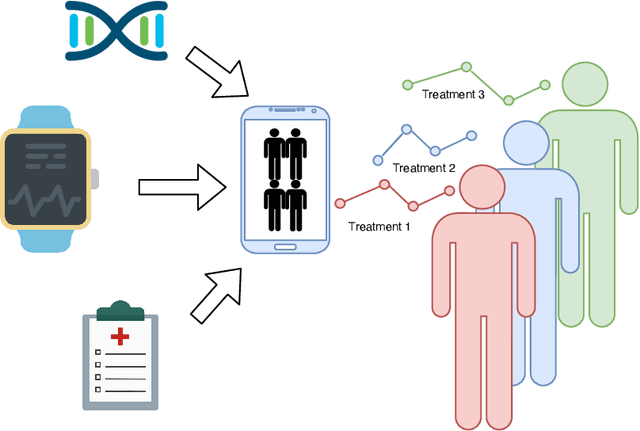
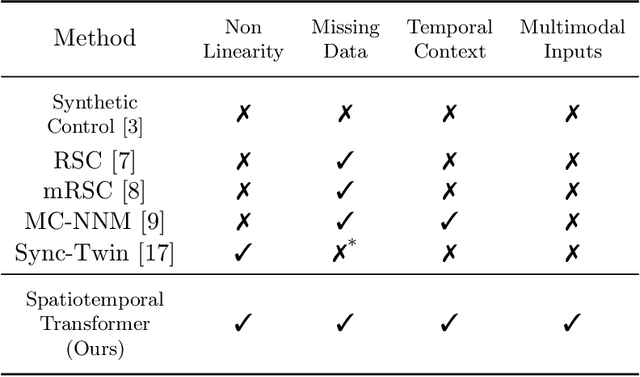
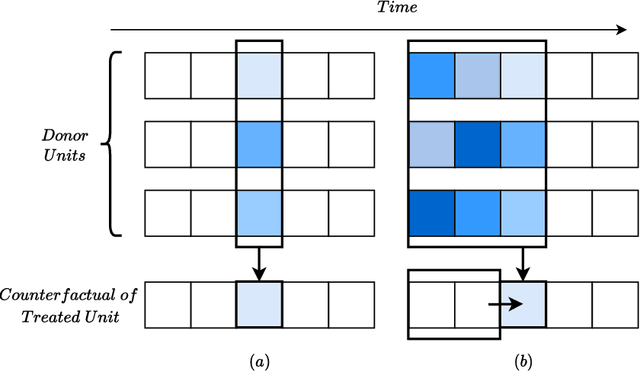

The Synthetic Control method has pioneered a class of powerful data-driven techniques to estimate the counterfactual reality of a unit from donor units. At its core, the technique involves a linear model fitted on the pre-intervention period that combines donor outcomes to yield the counterfactual. However, linearly combining spatial information at each time instance using time-agnostic weights fails to capture important inter-unit and intra-unit temporal contexts and complex nonlinear dynamics of real data. We instead propose an approach to use local spatiotemporal information before the onset of the intervention as a promising way to estimate the counterfactual sequence. To this end, we suggest a Transformer model that leverages particular positional embeddings, a modified decoder attention mask, and a novel pre-training task to perform spatiotemporal sequence-to-sequence modeling. Our experiments on synthetic data demonstrate the efficacy of our method in the typical small donor pool setting and its robustness against noise. We also generate actionable healthcare insights at the population and patient levels by simulating a state-wide public health policy to evaluate its effectiveness, an in silico trial for asthma medications to support randomized controlled trials, and a medical intervention for patients with Friedreich's ataxia to improve clinical decision-making and promote personalized therapy.
FlexiBERT: Are Current Transformer Architectures too Homogeneous and Rigid?
May 23, 2022
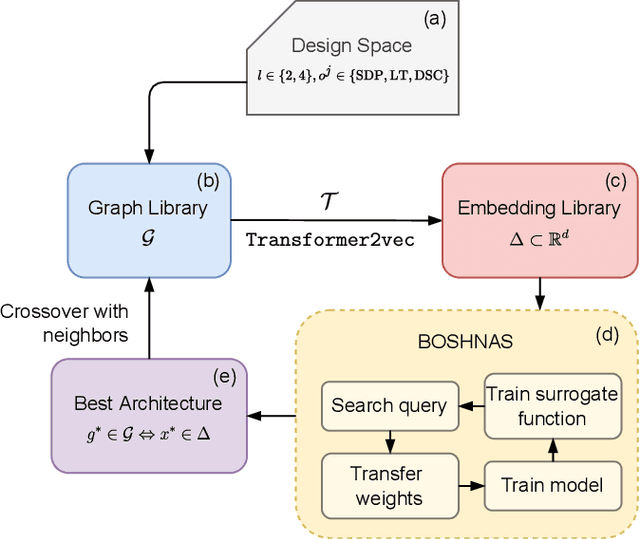
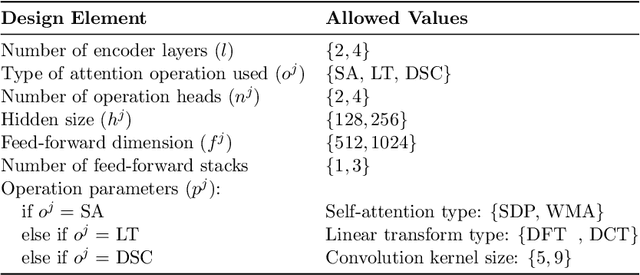
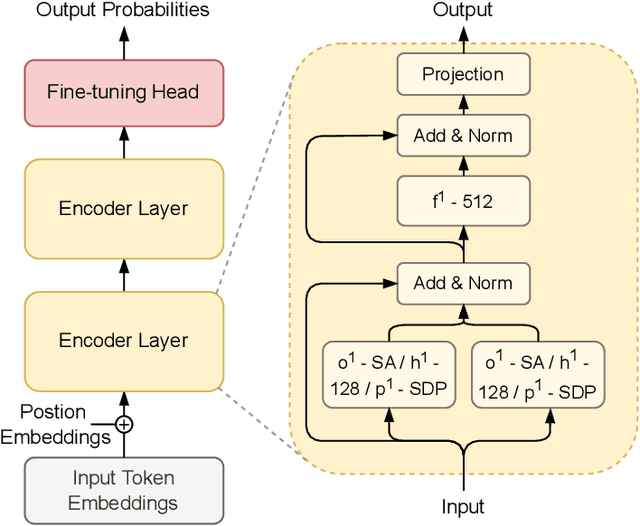
The existence of a plethora of language models makes the problem of selecting the best one for a custom task challenging. Most state-of-the-art methods leverage transformer-based models (e.g., BERT) or their variants. Training such models and exploring their hyperparameter space, however, is computationally expensive. Prior work proposes several neural architecture search (NAS) methods that employ performance predictors (e.g., surrogate models) to address this issue; however, analysis has been limited to homogeneous models that use fixed dimensionality throughout the network. This leads to sub-optimal architectures. To address this limitation, we propose a suite of heterogeneous and flexible models, namely FlexiBERT, that have varied encoder layers with a diverse set of possible operations and different hidden dimensions. For better-posed surrogate modeling in this expanded design space, we propose a new graph-similarity-based embedding scheme. We also propose a novel NAS policy, called BOSHNAS, that leverages this new scheme, Bayesian modeling, and second-order optimization, to quickly train and use a neural surrogate model to converge to the optimal architecture. A comprehensive set of experiments shows that the proposed policy, when applied to the FlexiBERT design space, pushes the performance frontier upwards compared to traditional models. FlexiBERT-Mini, one of our proposed models, has 3% fewer parameters than BERT-Mini and achieves 8.9% higher GLUE score. A FlexiBERT model with equivalent performance as the best homogeneous model achieves 2.6x smaller size. FlexiBERT-Large, another proposed model, achieves state-of-the-art results, outperforming the baseline models by at least 5.7% on the GLUE benchmark.
Machine Learning Assisted Security Analysis of 5G-Network-Connected Systems
Aug 07, 2021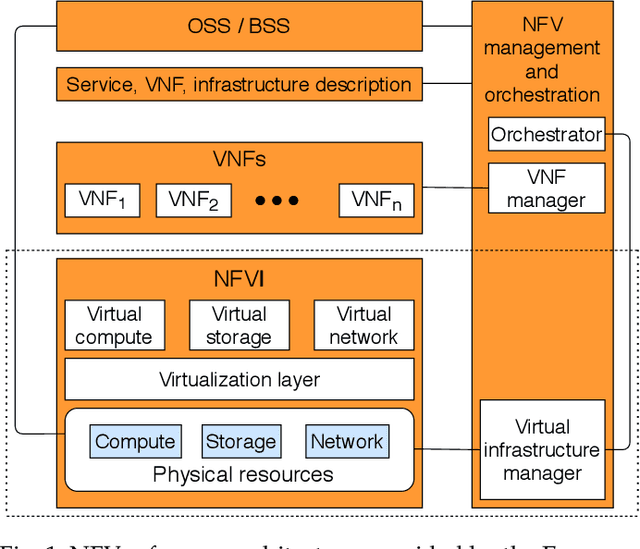

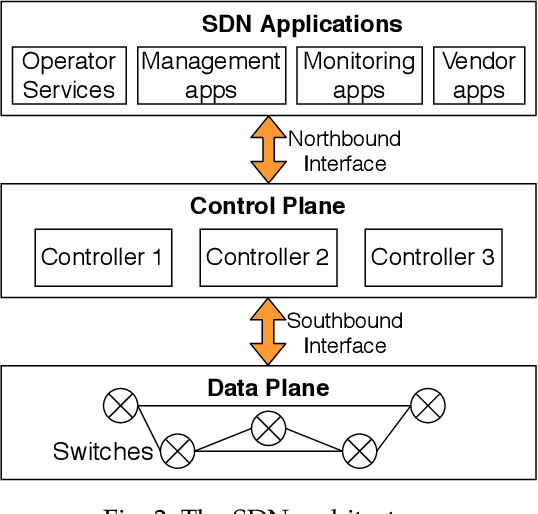
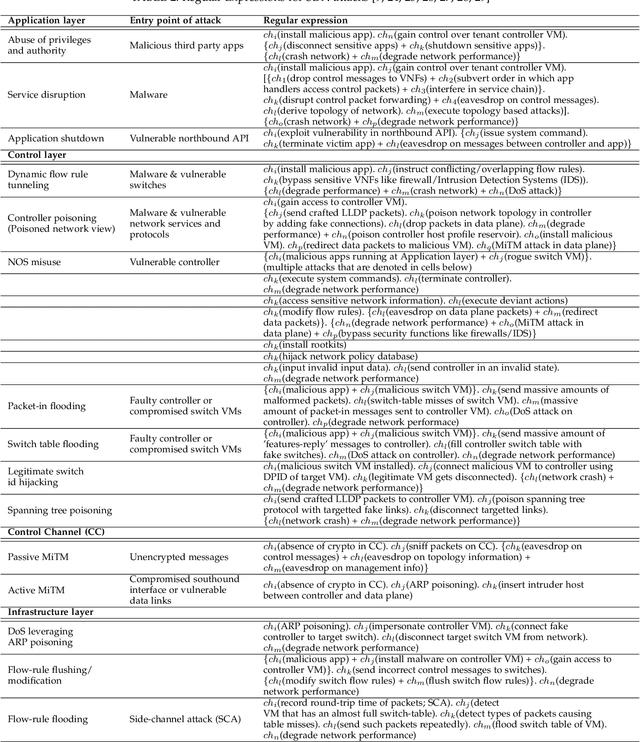
The core network architecture of telecommunication systems has undergone a paradigm shift in the fifth-generation (5G)networks. 5G networks have transitioned to software-defined infrastructures, thereby reducing their dependence on hardware-based network functions. New technologies, like network function virtualization and software-defined networking, have been incorporated in the 5G core network (5GCN) architecture to enable this transition. This has resulted in significant improvements in efficiency, performance, and robustness of the networks. However, this has also made the core network more vulnerable, as software systems are generally easier to compromise than hardware systems. In this article, we present a comprehensive security analysis framework for the 5GCN. The novelty of this approach lies in the creation and analysis of attack graphs of the software-defined and virtualized 5GCN through machine learning. This analysis points to 119 novel possible exploits in the 5GCN. We demonstrate that these possible exploits of 5GCN vulnerabilities generate five novel attacks on the 5G Authentication and Key Agreement protocol. We combine the attacks at the network, protocol, and the application layers to generate complex attack vectors. In a case study, we use these attack vectors to find four novel security loopholes in WhatsApp running on a 5G network.
GRAVITAS: Graphical Reticulated Attack Vectors for Internet-of-Things Aggregate Security
May 31, 2021
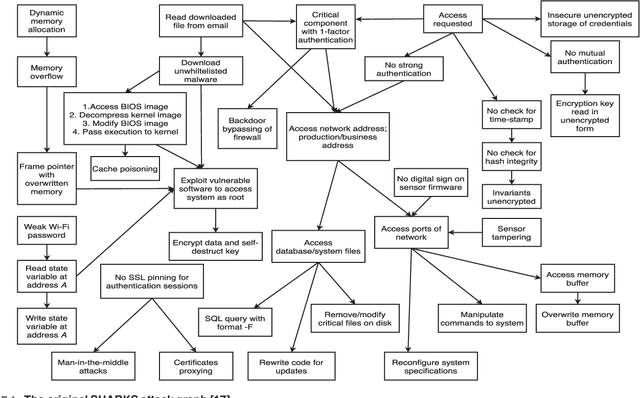
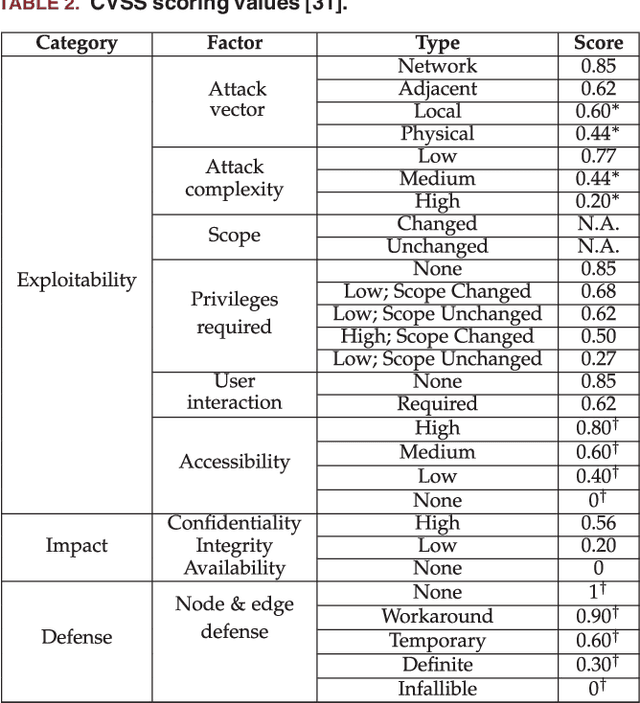
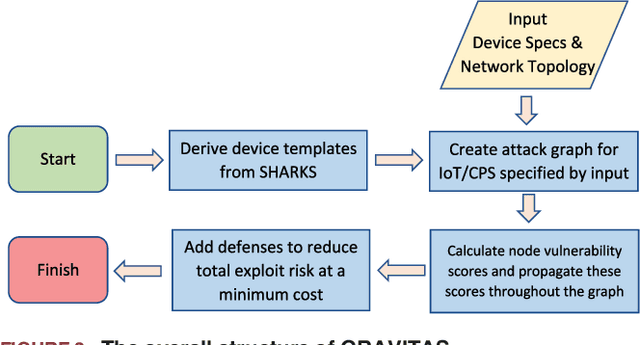
Internet-of-Things (IoT) and cyber-physical systems (CPSs) may consist of thousands of devices connected in a complex network topology. The diversity and complexity of these components present an enormous attack surface, allowing an adversary to exploit security vulnerabilities of different devices to execute a potent attack. Though significant efforts have been made to improve the security of individual devices in these systems, little attention has been paid to security at the aggregate level. In this article, we describe a comprehensive risk management system, called GRAVITAS, for IoT/CPS that can identify undiscovered attack vectors and optimize the placement of defenses within the system for optimal performance and cost. While existing risk management systems consider only known attacks, our model employs a machine learning approach to extrapolate undiscovered exploits, enabling us to identify attacks overlooked by manual penetration testing (pen-testing). The model is flexible enough to analyze practically any IoT/CPS and provide the system administrator with a concrete list of suggested defenses that can reduce system vulnerability at optimal cost. GRAVITAS can be employed by governments, companies, and system administrators to design secure IoT/CPS at scale, providing a quantitative measure of security and efficiency in a world where IoT/CPS devices will soon be ubiquitous.
Fast Design Space Exploration of Nonlinear Systems: Part I
Apr 11, 2021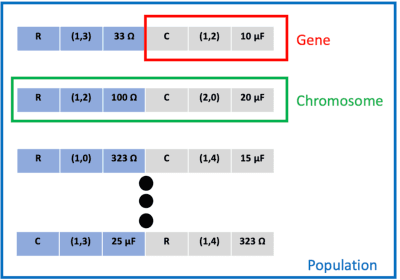
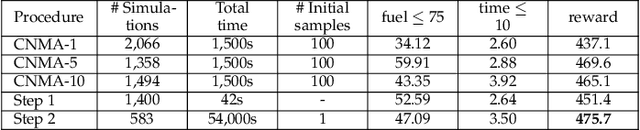
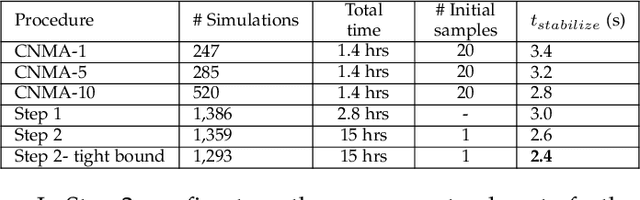
System design tools are often only available as blackboxes with complex nonlinear relationships between inputs and outputs. Blackboxes typically run in the forward direction: for a given design as input they compute an output representing system behavior. Most cannot be run in reverse to produce an input from requirements on output. Thus, finding a design satisfying a requirement is often a trial-and-error process without assurance of optimality. Finding designs concurrently satisfying multiple requirements is harder because designs satisfying individual requirements may conflict with each other. Compounding the hardness are the facts that blackbox evaluations can be expensive and sometimes fail to produce an output due to non-convergence of underlying numerical algorithms. This paper presents CNMA (Constrained optimization with Neural networks, MILP solvers and Active Learning), a new optimization method for blackboxes. It is conservative in the number of blackbox evaluations. Any designs it finds are guaranteed to satisfy all requirements. It is resilient to the failure of blackboxes to compute outputs. It tries to sample only the part of the design space relevant to solving the design problem, leveraging the power of neural networks, MILPs, and a new learning-from-failure feedback loop. The paper also presents parallel CNMA that improves the efficiency and quality of solutions over the sequential version, and tries to steer it away from local optima. CNMA's performance is evaluated for seven nonlinear design problems of 8 (2 problems), 10, 15, 36 and 60 real-valued dimensions and one with 186 binary dimensions. It is shown that CNMA improves the performance of stable, off-the-shelf implementations of Bayesian Optimization and Nelder Mead and Random Search by 1%-87% for a given fixed time and function evaluation budget. Note, that these implementations did not always return solutions.
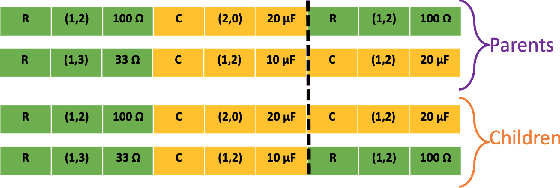
Fast Design Space Exploration of Nonlinear Systems: Part II
Apr 08, 2021Nonlinear system design is often a multi-objective optimization problem involving search for a design that satisfies a number of predefined constraints. The design space is typically very large since it includes all possible system architectures with different combinations of components composing each architecture. In this article, we address nonlinear system design space exploration through a two-step approach encapsulated in a framework called Fast Design Space Exploration of Nonlinear Systems (ASSENT). In the first step, we use a genetic algorithm to search for system architectures that allow discrete choices for component values or else only component values for a fixed architecture. This step yields a coarse design since the system may or may not meet the target specifications. In the second step, we use an inverse design to search over a continuous space and fine-tune the component values with the goal of improving the value of the objective function. We use a neural network to model the system response. The neural network is converted into a mixed-integer linear program for active learning to sample component values efficiently. We illustrate the efficacy of ASSENT on problems ranging from nonlinear system design to design of electrical circuits. Experimental results show that ASSENT achieves the same or better value of the objective function compared to various other optimization techniques for nonlinear system design by up to 54%. We improve sample efficiency by 6-10x compared to reinforcement learning based synthesis of electrical circuits.