 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Neural Network Transformer Model for Composite Microstructure Homogenization
Apr 16, 2023



Heterogeneity and uncertainty in a composite microstructure lead to either computational bottlenecks if modeled rigorously, or to solution inaccuracies in the stress field and failure predictions if approximated. Although methods suitable for analyzing arbitrary and non-linear microstructures exist, their computational cost makes them impractical to use in large-scale structural analysis. Surrogate models or Reduced Order Models (ROM), commonly enhance efficiencies, but they are typically calibrated with a single microstructure. Homogenization methods, such as the Mori-Tanaka method, offer rapid homogenization for a wide range of constituent properties. However, simplifying assumptions, like stress and strain averaging in phases, render the consideration of both deterministic and stochastic variations in microstructure infeasible. This paper illustrates a transformer neural network architecture that captures the knowledge of various microstructures and constituents, enabling it to function as a computationally efficient homogenization surrogate model. Given an image or an abstraction of an arbitrary composite microstructure, the transformer network predicts the homogenized stress-strain response. Two methods were tested that encode features of the microstructure. The first method calculates two-point statistics of the microstructure and uses Principal Component Analysis for dimensionality reduction. The second method uses an autoencoder with a Convolutional Neural Network. Both microstructure encoding methods accurately predict the homogenized material response. The paper describes the network architecture, training and testing data generation and the performance of the transformer network under cycling and random loadings.
Fast Design Space Exploration of Nonlinear Systems: Part I
Apr 11, 2021
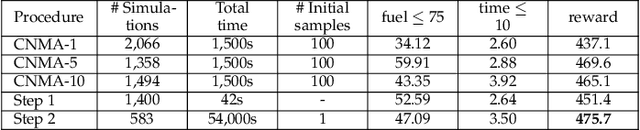
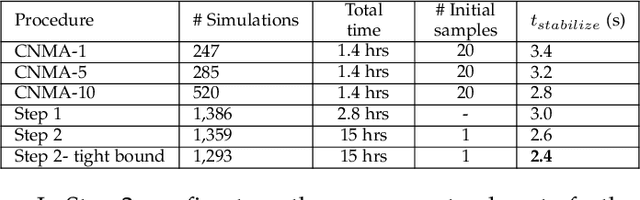
System design tools are often only available as blackboxes with complex nonlinear relationships between inputs and outputs. Blackboxes typically run in the forward direction: for a given design as input they compute an output representing system behavior. Most cannot be run in reverse to produce an input from requirements on output. Thus, finding a design satisfying a requirement is often a trial-and-error process without assurance of optimality. Finding designs concurrently satisfying multiple requirements is harder because designs satisfying individual requirements may conflict with each other. Compounding the hardness are the facts that blackbox evaluations can be expensive and sometimes fail to produce an output due to non-convergence of underlying numerical algorithms. This paper presents CNMA (Constrained optimization with Neural networks, MILP solvers and Active Learning), a new optimization method for blackboxes. It is conservative in the number of blackbox evaluations. Any designs it finds are guaranteed to satisfy all requirements. It is resilient to the failure of blackboxes to compute outputs. It tries to sample only the part of the design space relevant to solving the design problem, leveraging the power of neural networks, MILPs, and a new learning-from-failure feedback loop. The paper also presents parallel CNMA that improves the efficiency and quality of solutions over the sequential version, and tries to steer it away from local optima. CNMA's performance is evaluated for seven nonlinear design problems of 8 (2 problems), 10, 15, 36 and 60 real-valued dimensions and one with 186 binary dimensions. It is shown that CNMA improves the performance of stable, off-the-shelf implementations of Bayesian Optimization and Nelder Mead and Random Search by 1%-87% for a given fixed time and function evaluation budget. Note, that these implementations did not always return solutions.
Robot Design With Neural Networks, MILP Solvers and Active Learning
Oct 19, 2020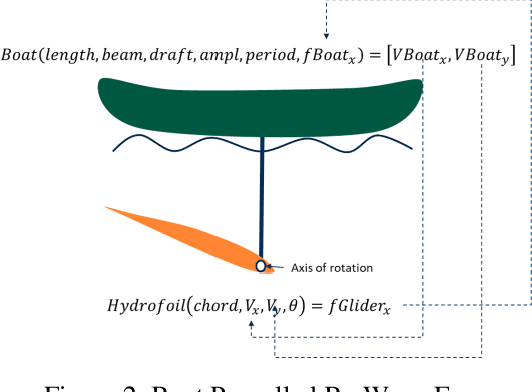
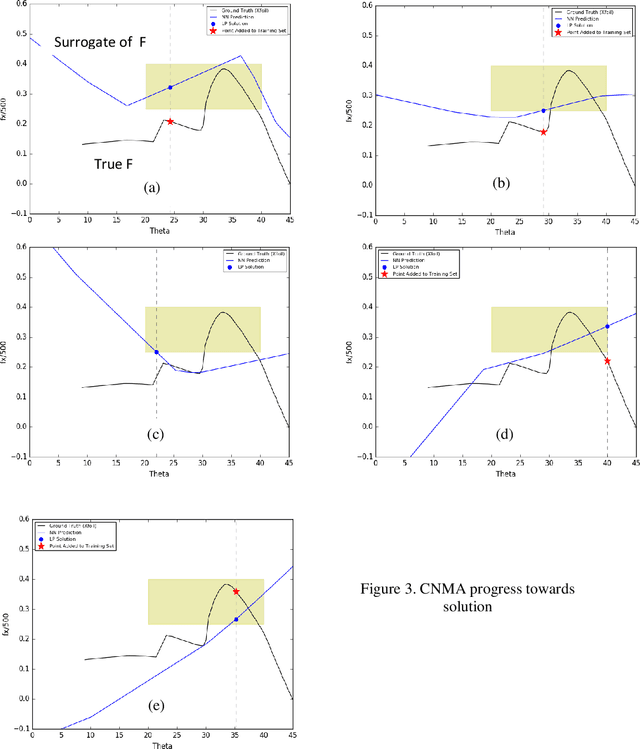
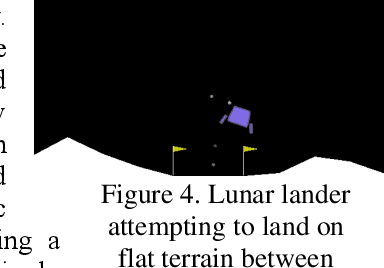
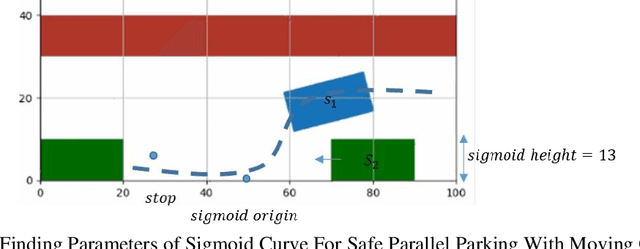
Central to the design of many robot systems and their controllers is solving a constrained blackbox optimization problem. This paper presents CNMA, a new method of solving this problem that is conservative in the number of potentially expensive blackbox function evaluations; allows specifying complex, even recursive constraints directly rather than as hard-to-design penalty or barrier functions; and is resilient to the non-termination of function evaluations. CNMA leverages the ability of neural networks to approximate any continuous function, their transformation into equivalent mixed integer linear programs (MILPs) and their optimization subject to constraints with industrial strength MILP solvers. A new learning-from-failure step guides the learning to be relevant to solving the constrained optimization problem. Thus, the amount of learning is orders of magnitude smaller than that needed to learn functions over their entire domains. CNMA is illustrated with the design of several robotic systems: wave-energy propelled boat, lunar lander, hexapod, cartpole, acrobot and parallel parking. These range from 6 real-valued dimensions to 36. We show that CNMA surpasses the Nelder-Mead, Gaussian and Random Search optimization methods against the metric of number of function evaluations.