 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Math Reasoning Evaluation: A Robust LLM-as-a-Judge Framework Beyond Symbolic Rigidity
Apr 24, 2026Recent advancements in large language models have led to significant improvements across various tasks, including mathematical reasoning, which is used to assess models' intelligence in logical reasoning and problem-solving. Models are evaluated on mathematical reasoning benchmarks by verifying the correctness of the final answer against a ground truth answer. A common approach for this verification is based on symbolic mathematics comparison, which fails to generalize across diverse mathematical representations and solution formats. In this work, we offer a robust and flexible alternative to rule-based symbolic mathematics comparison. We propose an LLM-based evaluation framework for evaluating model-generated answers, enabling accurate evaluation across diverse mathematical representations and answer formats. We present failure cases of symbolic evaluation in two popular frameworks, Lighteval and SimpleRL, and compare them to our approach, demonstrating clear improvements over commonly used methods. Our framework enables more reliable evaluation and benchmarking, leading to more accurate performance monitoring, which is important for advancing mathematical problem-solving and intelligent systems.
Pseudo-Invertible Neural Networks
Feb 05, 2026The Moore-Penrose Pseudo-inverse (PInv) serves as the fundamental solution for linear systems. In this paper, we propose a natural generalization of PInv to the nonlinear regime in general and to neural networks in particular. We introduce Surjective Pseudo-invertible Neural Networks (SPNN), a class of architectures explicitly designed to admit a tractable non-linear PInv. The proposed non-linear PInv and its implementation in SPNN satisfy fundamental geometric properties. One such property is null-space projection or "Back-Projection", $x' = x + A^\dagger(y-Ax)$, which moves a sample $x$ to its closest consistent state $x'$ satisfying $Ax=y$. We formalize Non-Linear Back-Projection (NLBP), a method that guarantees the same consistency constraint for non-linear mappings $f(x)=y$ via our defined PInv. We leverage SPNNs to expand the scope of zero-shot inverse problems. Diffusion-based null-space projection has revolutionized zero-shot solving for linear inverse problems by exploiting closed-form back-projection. We extend this method to non-linear degradations. Here, "degradation" is broadly generalized to include any non-linear loss of information, spanning from optical distortions to semantic abstractions like classification. This approach enables zero-shot inversion of complex degradations and allows precise semantic control over generative outputs without retraining the diffusion prior.
Scene-VLM: Multimodal Video Scene Segmentation via Vision-Language Models
Dec 25, 2025



Segmenting long-form videos into semantically coherent scenes is a fundamental task in large-scale video understanding. Existing encoder-based methods are limited by visual-centric biases, classify each shot in isolation without leveraging sequential dependencies, and lack both narrative understanding and explainability. In this paper, we present Scene-VLM, the first fine-tuned vision-language model (VLM) framework for video scene segmentation. Scene-VLM jointly processes visual and textual cues including frames, transcriptions, and optional metadata to enable multimodal reasoning across consecutive shots. The model generates predictions sequentially with causal dependencies among shots and introduces a context-focus window mechanism to ensure sufficient temporal context for each shot-level decision. In addition, we propose a scheme to extract confidence scores from the token-level logits of the VLM, enabling controllable precision-recall trade-offs that were previously limited to encoder-based methods. Furthermore, we demonstrate that our model can be aligned to generate coherent natural-language rationales for its boundary decisions through minimal targeted supervision. Our approach achieves state-of-the-art performance on standard scene segmentation benchmarks. On MovieNet, for example, Scene-VLM yields significant improvements of +6 AP and +13.7 F1 over the previous leading method.
Towards General Modality Translation with Contrastive and Predictive Latent Diffusion Bridge
Oct 23, 2025



Recent advances in generative modeling have positioned diffusion models as state-of-the-art tools for sampling from complex data distributions. While these models have shown remarkable success across single-modality domains such as images and audio, extending their capabilities to Modality Translation (MT), translating information across different sensory modalities, remains an open challenge. Existing approaches often rely on restrictive assumptions, including shared dimensionality, Gaussian source priors, and modality-specific architectures, which limit their generality and theoretical grounding. In this work, we propose the Latent Denoising Diffusion Bridge Model (LDDBM), a general-purpose framework for modality translation based on a latent-variable extension of Denoising Diffusion Bridge Models. By operating in a shared latent space, our method learns a bridge between arbitrary modalities without requiring aligned dimensions. We introduce a contrastive alignment loss to enforce semantic consistency between paired samples and design a domain-agnostic encoder-decoder architecture tailored for noise prediction in latent space. Additionally, we propose a predictive loss to guide training toward accurate cross-domain translation and explore several training strategies to improve stability. Our approach supports arbitrary modality pairs and performs strongly on diverse MT tasks, including multi-view to 3D shape generation, image super-resolution, and multi-view scene synthesis. Comprehensive experiments and ablations validate the effectiveness of our framework, establishing a new strong baseline in general modality translation. For more information, see our project page: https://sites.google.com/view/lddbm/home.
Who Said Neural Networks Aren't Linear?
Oct 09, 2025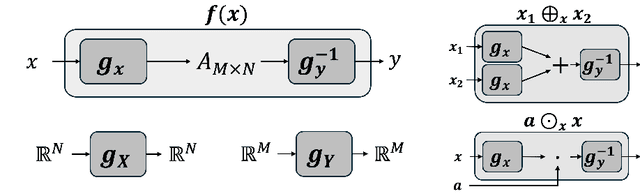



Neural networks are famously nonlinear. However, linearity is defined relative to a pair of vector spaces, $f$$:$$X$$\to$$Y$. Is it possible to identify a pair of non-standard vector spaces for which a conventionally nonlinear function is, in fact, linear? This paper introduces a method that makes such vector spaces explicit by construction. We find that if we sandwich a linear operator $A$ between two invertible neural networks, $f(x)=g_y^{-1}(A g_x(x))$, then the corresponding vector spaces $X$ and $Y$ are induced by newly defined addition and scaling actions derived from $g_x$ and $g_y$. We term this kind of architecture a Linearizer. This framework makes the entire arsenal of linear algebra, including SVD, pseudo-inverse, orthogonal projection and more, applicable to nonlinear mappings. Furthermore, we show that the composition of two Linearizers that share a neural network is also a Linearizer. We leverage this property and demonstrate that training diffusion models using our architecture makes the hundreds of sampling steps collapse into a single step. We further utilize our framework to enforce idempotency (i.e. $f(f(x))=f(x)$) on networks leading to a globally projective generative model and to demonstrate modular style transfer.
Time Series Generation Under Data Scarcity: A Unified Generative Modeling Approach
May 26, 2025Generative modeling of time series is a central challenge in time series analysis, particularly under data-scarce conditions. Despite recent advances in generative modeling, a comprehensive understanding of how state-of-the-art generative models perform under limited supervision remains lacking. In this work, we conduct the first large-scale study evaluating leading generative models in data-scarce settings, revealing a substantial performance gap between full-data and data-scarce regimes. To close this gap, we propose a unified diffusion-based generative framework that can synthesize high-fidelity time series across diverse domains using just a few examples. Our model is pre-trained on a large, heterogeneous collection of time series datasets, enabling it to learn generalizable temporal representations. It further incorporates architectural innovations such as dynamic convolutional layers for flexible channel adaptation and dataset token conditioning for domain-aware generation. Without requiring abundant supervision, our unified model achieves state-of-the-art performance in few-shot settings-outperforming domain-specific baselines across a wide range of subset sizes. Remarkably, it also surpasses all baselines even when tested on full datasets benchmarks, highlighting the strength of pre-training and cross-domain generalization. We hope this work encourages the community to revisit few-shot generative modeling as a key problem in time series research and pursue unified solutions that scale efficiently across domains. Code is available at https://github.com/azencot-group/ImagenFew.
One-Step Offline Distillation of Diffusion-based Models via Koopman Modeling
May 19, 2025Diffusion-based generative models have demonstrated exceptional performance, yet their iterative sampling procedures remain computationally expensive. A prominent strategy to mitigate this cost is distillation, with offline distillation offering particular advantages in terms of efficiency, modularity, and flexibility. In this work, we identify two key observations that motivate a principled distillation framework: (1) while diffusion models have been viewed through the lens of dynamical systems theory, powerful and underexplored tools can be further leveraged; and (2) diffusion models inherently impose structured, semantically coherent trajectories in latent space. Building on these observations, we introduce the Koopman Distillation Model KDM, a novel offline distillation approach grounded in Koopman theory-a classical framework for representing nonlinear dynamics linearly in a transformed space. KDM encodes noisy inputs into an embedded space where a learned linear operator propagates them forward, followed by a decoder that reconstructs clean samples. This enables single-step generation while preserving semantic fidelity. We provide theoretical justification for our approach: (1) under mild assumptions, the learned diffusion dynamics admit a finite-dimensional Koopman representation; and (2) proximity in the Koopman latent space correlates with semantic similarity in the generated outputs, allowing for effective trajectory alignment. Empirically, KDM achieves state-of-the-art performance across standard offline distillation benchmarks, improving FID scores by up to 40% in a single generation step. All implementation details and code for the experimental setups are provided in our GitHub - https://github.com/azencot-group/KDM, or in our project page - https://sites.google.com/view/koopman-distillation-model.
Utilizing Image Transforms and Diffusion Models for Generative Modeling of Short and Long Time Series
Oct 25, 2024



Lately, there has been a surge in interest surrounding generative modeling of time series data. Most existing approaches are designed either to process short sequences or to handle long-range sequences. This dichotomy can be attributed to gradient issues with recurrent networks, computational costs associated with transformers, and limited expressiveness of state space models. Towards a unified generative model for varying-length time series, we propose in this work to transform sequences into images. By employing invertible transforms such as the delay embedding and the short-time Fourier transform, we unlock three main advantages: i) We can exploit advanced diffusion vision models; ii) We can remarkably process short- and long-range inputs within the same framework; and iii) We can harness recent and established tools proposed in the time series to image literature. We validate the effectiveness of our method through a comprehensive evaluation across multiple tasks, including unconditional generation, interpolation, and extrapolation. We show that our approach achieves consistently state-of-the-art results against strong baselines. In the unconditional generation tasks, we show remarkable mean improvements of 58.17% over previous diffusion models in the short discriminative score and 132.61% in the (ultra-)long classification scores. Code is at https://github.com/azencot-group/ImagenTime.
Sequential Disentanglement by Extracting Static Information From A Single Sequence Element
Jun 26, 2024



One of the fundamental representation learning tasks is unsupervised sequential disentanglement, where latent codes of inputs are decomposed to a single static factor and a sequence of dynamic factors. To extract this latent information, existing methods condition the static and dynamic codes on the entire input sequence. Unfortunately, these models often suffer from information leakage, i.e., the dynamic vectors encode both static and dynamic information, or vice versa, leading to a non-disentangled representation. Attempts to alleviate this problem via reducing the dynamic dimension and auxiliary loss terms gain only partial success. Instead, we propose a novel and simple architecture that mitigates information leakage by offering a simple and effective subtraction inductive bias while conditioning on a single sample. Remarkably, the resulting variational framework is simpler in terms of required loss terms, hyperparameters, and data augmentation. We evaluate our method on multiple data-modality benchmarks including general time series, video, and audio, and we show beyond state-of-the-art results on generation and prediction tasks in comparison to several strong baselines.
Generative Modeling of Graphs via Joint Diffusion of Node and Edge Attributes
Feb 06, 2024Graph generation is integral to various engineering and scientific disciplines. Nevertheless, existing methodologies tend to overlook the generation of edge attributes. However, we identify critical applications where edge attributes are essential, making prior methods potentially unsuitable in such contexts. Moreover, while trivial adaptations are available, empirical investigations reveal their limited efficacy as they do not properly model the interplay among graph components. To address this, we propose a joint score-based model of nodes and edges for graph generation that considers all graph components. Our approach offers two key novelties: (i) node and edge attributes are combined in an attention module that generates samples based on the two ingredients; and (ii) node, edge and adjacency information are mutually dependent during the graph diffusion process. We evaluate our method on challenging benchmarks involving real-world and synthetic datasets in which edge features are crucial. Additionally, we introduce a new synthetic dataset that incorporates edge values. Furthermore, we propose a novel application that greatly benefits from the method due to its nature: the generation of traffic scenes represented as graphs. Our method outperforms other graph generation methods, demonstrating a significant advantage in edge-related measures.