 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Math Reasoning Evaluation: A Robust LLM-as-a-Judge Framework Beyond Symbolic Rigidity
Apr 24, 2026Recent advancements in large language models have led to significant improvements across various tasks, including mathematical reasoning, which is used to assess models' intelligence in logical reasoning and problem-solving. Models are evaluated on mathematical reasoning benchmarks by verifying the correctness of the final answer against a ground truth answer. A common approach for this verification is based on symbolic mathematics comparison, which fails to generalize across diverse mathematical representations and solution formats. In this work, we offer a robust and flexible alternative to rule-based symbolic mathematics comparison. We propose an LLM-based evaluation framework for evaluating model-generated answers, enabling accurate evaluation across diverse mathematical representations and answer formats. We present failure cases of symbolic evaluation in two popular frameworks, Lighteval and SimpleRL, and compare them to our approach, demonstrating clear improvements over commonly used methods. Our framework enables more reliable evaluation and benchmarking, leading to more accurate performance monitoring, which is important for advancing mathematical problem-solving and intelligent systems.
Scene-VLM: Multimodal Video Scene Segmentation via Vision-Language Models
Dec 25, 2025



Segmenting long-form videos into semantically coherent scenes is a fundamental task in large-scale video understanding. Existing encoder-based methods are limited by visual-centric biases, classify each shot in isolation without leveraging sequential dependencies, and lack both narrative understanding and explainability. In this paper, we present Scene-VLM, the first fine-tuned vision-language model (VLM) framework for video scene segmentation. Scene-VLM jointly processes visual and textual cues including frames, transcriptions, and optional metadata to enable multimodal reasoning across consecutive shots. The model generates predictions sequentially with causal dependencies among shots and introduces a context-focus window mechanism to ensure sufficient temporal context for each shot-level decision. In addition, we propose a scheme to extract confidence scores from the token-level logits of the VLM, enabling controllable precision-recall trade-offs that were previously limited to encoder-based methods. Furthermore, we demonstrate that our model can be aligned to generate coherent natural-language rationales for its boundary decisions through minimal targeted supervision. Our approach achieves state-of-the-art performance on standard scene segmentation benchmarks. On MovieNet, for example, Scene-VLM yields significant improvements of +6 AP and +13.7 F1 over the previous leading method.
Group-Aware Reinforcement Learning for Output Diversity in Large Language Models
Nov 16, 2025Large Language Models (LLMs) often suffer from mode collapse, repeatedly generating the same few completions even when many valid answers exist, limiting their diversity across a wide range of tasks. We introduce Group-Aware Policy Optimization (GAPO), a simple extension of the recent and popular Group Relative Policy Optimization (GRPO) that computes rewards over the group as a whole. GAPO enables learning from the group-level properties such as diversity and coverage. We demonstrate GAPO using a frequency-aware reward function that encourages uniform sampling over valid LLM completions, and show that GAPO-trained models produce valid and more diverse model responses. Beyond this setup, GAPO generalizes to open-ended prompts and improves response diversity without compromising accuracy on standard LLM benchmarks (GSM8K, MATH, HumanEval, MMLU-Pro). Our code will be made publicly available.
Distilling the Knowledge in Data Pruning
Mar 12, 2024



With the increasing size of datasets used for training neural networks, data pruning becomes an attractive field of research. However, most current data pruning algorithms are limited in their ability to preserve accuracy compared to models trained on the full data, especially in high pruning regimes. In this paper we explore the application of data pruning while incorporating knowledge distillation (KD) when training on a pruned subset. That is, rather than relying solely on ground-truth labels, we also use the soft predictions from a teacher network pre-trained on the complete data. By integrating KD into training, we demonstrate significant improvement across datasets, pruning methods, and on all pruning fractions. We first establish a theoretical motivation for employing self-distillation to improve training on pruned data. Then, we empirically make a compelling and highly practical observation: using KD, simple random pruning is comparable or superior to sophisticated pruning methods across all pruning regimes. On ImageNet for example, we achieve superior accuracy despite training on a random subset of only 50% of the data. Additionally, we demonstrate a crucial connection between the pruning factor and the optimal knowledge distillation weight. This helps mitigate the impact of samples with noisy labels and low-quality images retained by typical pruning algorithms. Finally, we make an intriguing observation: when using lower pruning fractions, larger teachers lead to accuracy degradation, while surprisingly, employing teachers with a smaller capacity than the student's may improve results. Our code will be made available.
End-to-End Referring Video Object Segmentation with Multimodal Transformers
Nov 29, 2021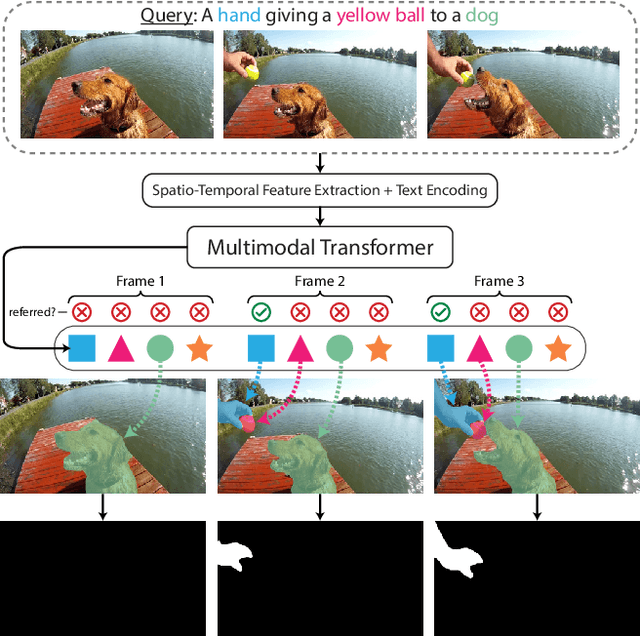
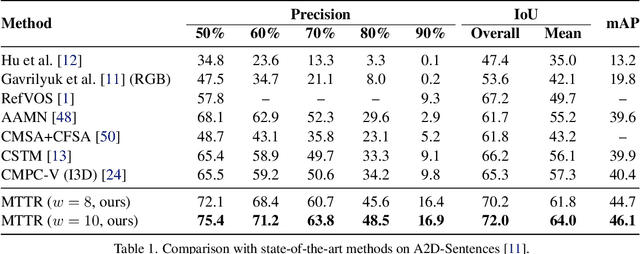
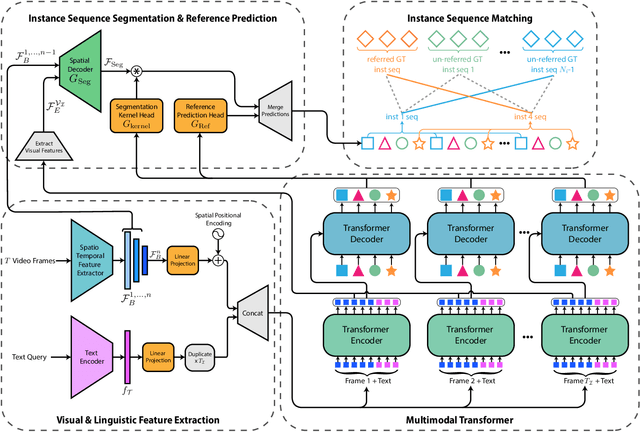
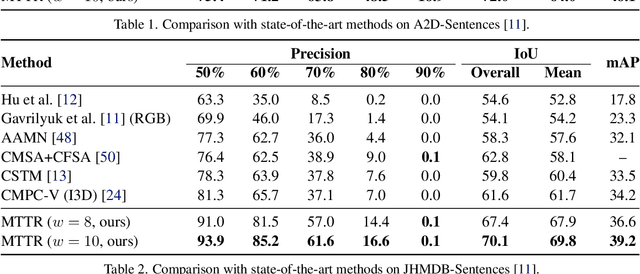
The referring video object segmentation task (RVOS) involves segmentation of a text-referred object instance in the frames of a given video. Due to the complex nature of this multimodal task, which combines text reasoning, video understanding, instance segmentation and tracking, existing approaches typically rely on sophisticated pipelines in order to tackle it. In this paper, we propose a simple Transformer-based approach to RVOS. Our framework, termed Multimodal Tracking Transformer (MTTR), models the RVOS task as a sequence prediction problem. Following recent advancements in computer vision and natural language processing, MTTR is based on the realization that video and text can both be processed together effectively and elegantly by a single multimodal Transformer model. MTTR is end-to-end trainable, free of text-related inductive bias components and requires no additional mask-refinement post-processing steps. As such, it simplifies the RVOS pipeline considerably compared to existing methods. Evaluation on standard benchmarks reveals that MTTR significantly outperforms previous art across multiple metrics. In particular, MTTR shows impressive +5.7 and +5.0 mAP gains on the A2D-Sentences and JHMDB-Sentences datasets respectively, while processing 76 frames per second. In addition, we report strong results on the public validation set of Refer-YouTube-VOS, a more challenging RVOS dataset that has yet to receive the attention of researchers. The code to reproduce our experiments is available at https://github.com/mttr2021/MTTR
BIDCD - Bosch Industrial Depth Completion Dataset
Aug 10, 2021


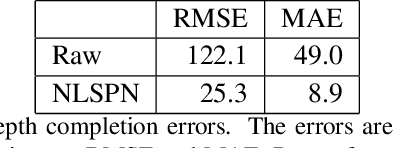
We introduce BIDCD - the Bosch Industrial Depth Completion Dataset. BIDCD is a new RGBD dataset of metallic industrial objects, collected with a depth camera mounted on a robotic manipulator. The main purpose of this dataset is to facilitate the training of domain-specific depth completion models, to be used in logistics and manufacturing tasks. We trained a State-of-the-Art depth completion model on this dataset, and report the results, setting an initial benchmark.