 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParsiNLU: A Suite of Language Understanding Challenges for Persian
Dec 11, 2020
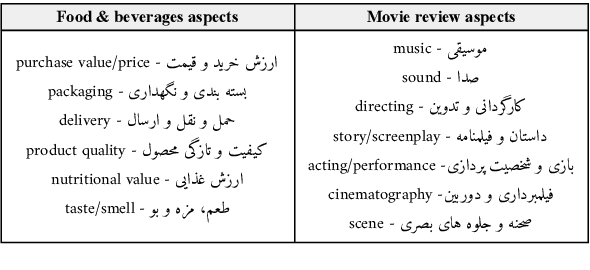
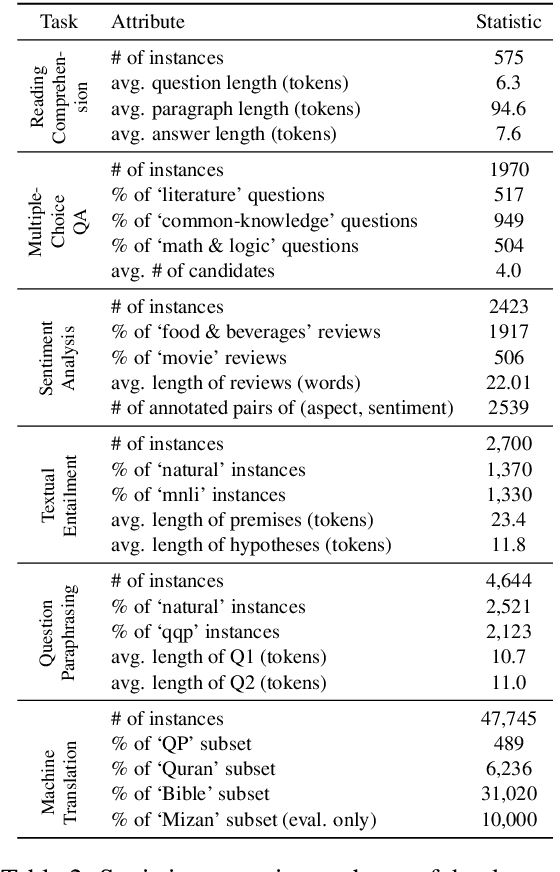
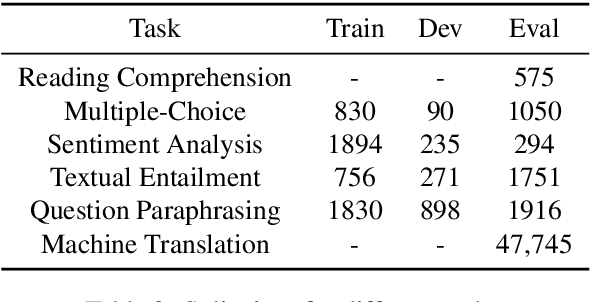
Despite the progress made in recent years in addressing natural language understanding (NLU) challenges, the majority of this progress remains to be concentrated on resource-rich languages like English. This work focuses on Persian language, one of the widely spoken languages in the world, and yet there are few NLU datasets available for this rich language. The availability of high-quality evaluation datasets is a necessity for reliable assessment of the progress on different NLU tasks and domains. We introduce ParsiNLU, the first benchmark in Persian language that includes a range of high-level tasks -- Reading Comprehension, Textual Entailment, etc. These datasets are collected in a multitude of ways, often involving manual annotations by native speakers. This results in over 14.5$k$ new instances across 6 distinct NLU tasks. Besides, we present the first results on state-of-the-art monolingual and multi-lingual pre-trained language-models on this benchmark and compare them with human performance, which provides valuable insights into our ability to tackle natural language understanding challenges in Persian. We hope ParsiNLU fosters further research and advances in Persian language understanding.
Attending the Emotions to Detect Online Abusive Language
Sep 06, 2019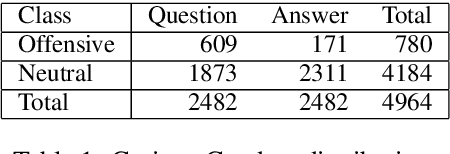
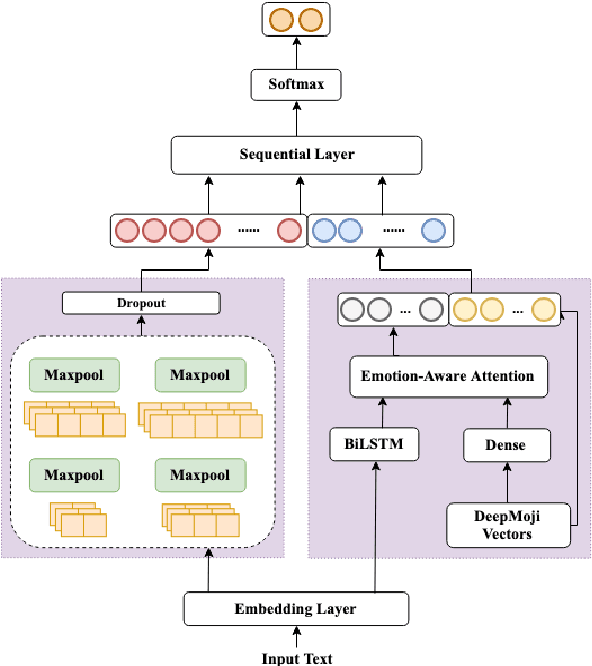
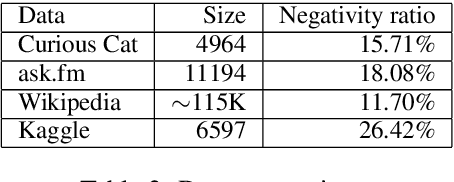
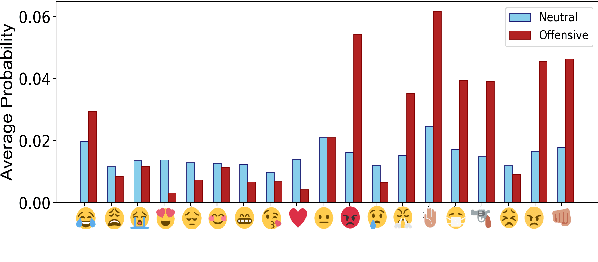
In recent years, abusive behavior has become a serious issue in online social networks. In this paper, we present a new corpus from a semi-anonymous social media platform, which contains the instances of offensive and neutral classes. We introduce a single deep neural architecture that considers both local and sequential information from the text in order to detect abusive language. Along with this model, we introduce a new attention mechanism called emotion-aware attention. This mechanism utilizes the emotions behind the text to find the most important words within that text. We experiment with this model on our dataset and later present the analysis. Additionally, we evaluate our proposed method on different corpora and show new state-of-the-art results with respect to offensive language detection.
Rating for Parents: Predicting Children Suitability Rating for Movies Based on Language of the Movies
Aug 22, 2019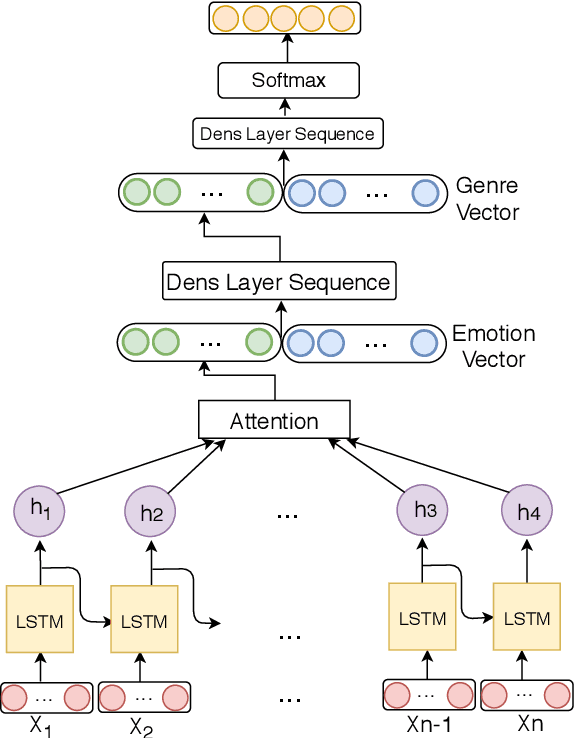
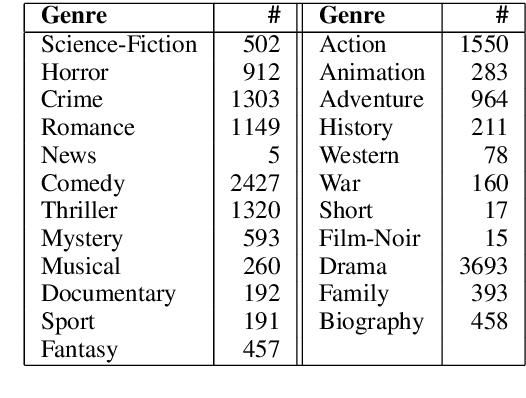
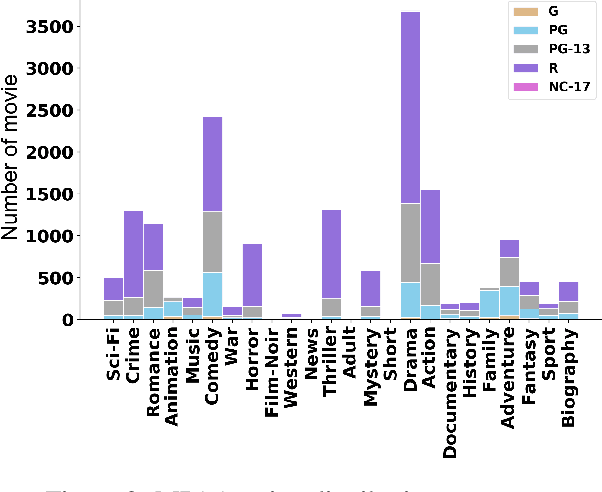

The film culture has grown tremendously in recent years. The large number of streaming services put films as one of the most convenient forms of entertainment in today's world. Films can help us learn and inspire societal change. But they can also negatively affect viewers. In this paper, our goal is to predict the suitability of the movie content for children and young adults based on scripts. The criterion that we use to measure suitability is the MPAA rating that is specifically designed for this purpose. We propose an RNN based architecture with attention that jointly models the genre and the emotions in the script to predict the MPAA rating. We achieve 78% weighted F1-score for the classification model that outperforms the traditional machine learning method by 6%.
RiTUAL-UH at TRAC 2018 Shared Task: Aggression Identification
Jul 31, 2018
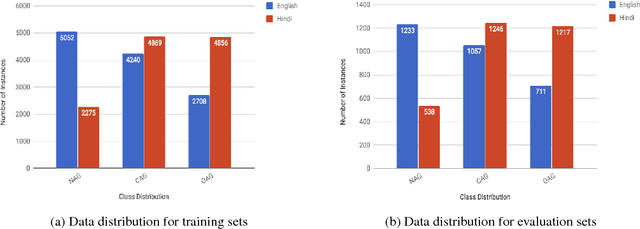
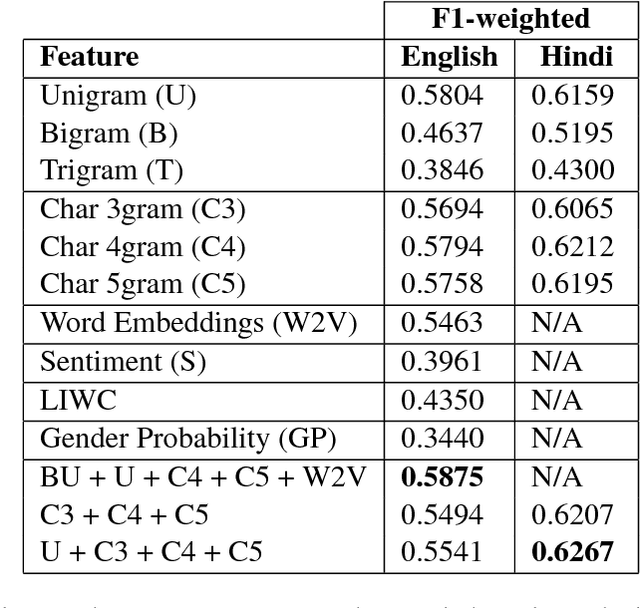
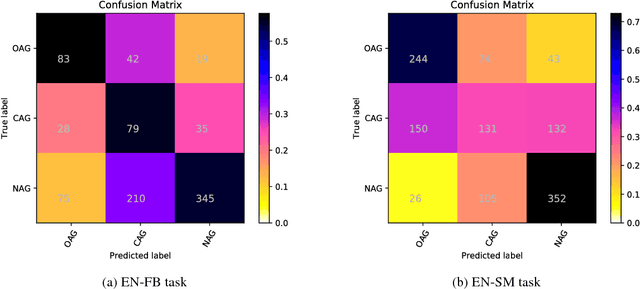
This paper presents our system for "TRAC 2018 Shared Task on Aggression Identification". Our best systems for the English dataset use a combination of lexical and semantic features. However, for Hindi data using only lexical features gave us the best results. We obtained weighted F1- measures of 0.5921 for the English Facebook task (ranked 12th), 0.5663 for the English Social Media task (ranked 6th), 0.6292 for the Hindi Facebook task (ranked 1st), and 0.4853 for the Hindi Social Media task (ranked 2nd).