 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEye of Judgement: Dissecting the Evaluation of Russian-speaking LLMs with POLLUX
May 30, 2025We introduce POLLUX, a comprehensive open-source benchmark designed to evaluate the generative capabilities of large language models (LLMs) in Russian. Our main contribution is a novel evaluation methodology that enhances the interpretability of LLM assessment. For each task type, we define a set of detailed criteria and develop a scoring protocol where models evaluate responses and provide justifications for their ratings. This enables transparent, criteria-driven evaluation beyond traditional resource-consuming, side-by-side human comparisons. POLLUX includes a detailed, fine-grained taxonomy of 35 task types covering diverse generative domains such as code generation, creative writing, and practical assistant use cases, totaling 2,100 manually crafted and professionally authored prompts. Each task is categorized by difficulty (easy/medium/hard), with experts constructing the dataset entirely from scratch. We also release a family of LLM-as-a-Judge (7B and 32B) evaluators trained for nuanced assessment of generative outputs. This approach provides scalable, interpretable evaluation and annotation tools for model development, effectively replacing costly and less precise human judgments.
Will It Still Be True Tomorrow? Multilingual Evergreen Question Classification to Improve Trustworthy QA
May 27, 2025



Large Language Models (LLMs) often hallucinate in question answering (QA) tasks. A key yet underexplored factor contributing to this is the temporality of questions -- whether they are evergreen (answers remain stable over time) or mutable (answers change). In this work, we introduce EverGreenQA, the first multilingual QA dataset with evergreen labels, supporting both evaluation and training. Using EverGreenQA, we benchmark 12 modern LLMs to assess whether they encode question temporality explicitly (via verbalized judgments) or implicitly (via uncertainty signals). We also train EG-E5, a lightweight multilingual classifier that achieves SoTA performance on this task. Finally, we demonstrate the practical utility of evergreen classification across three applications: improving self-knowledge estimation, filtering QA datasets, and explaining GPT-4o retrieval behavior.
LLM-Independent Adaptive RAG: Let the Question Speak for Itself
May 07, 2025



Large Language Models~(LLMs) are prone to hallucinations, and Retrieval-Augmented Generation (RAG) helps mitigate this, but at a high computational cost while risking misinformation. Adaptive retrieval aims to retrieve only when necessary, but existing approaches rely on LLM-based uncertainty estimation, which remain inefficient and impractical. In this study, we introduce lightweight LLM-independent adaptive retrieval methods based on external information. We investigated 27 features, organized into 7 groups, and their hybrid combinations. We evaluated these methods on 6 QA datasets, assessing the QA performance and efficiency. The results show that our approach matches the performance of complex LLM-based methods while achieving significant efficiency gains, demonstrating the potential of external information for adaptive retrieval.
GigaPevt: Multimodal Medical Assistant
Feb 26, 2024Building an intelligent and efficient medical assistant is still a challenging AI problem. The major limitation comes from the data modality scarceness, which reduces comprehensive patient perception. This demo paper presents the GigaPevt, the first multimodal medical assistant that combines the dialog capabilities of large language models with specialized medical models. Such an approach shows immediate advantages in dialog quality and metric performance, with a 1.18\% accuracy improvement in the question-answering task.
A Practical Survey on Emerging Threats from AI-driven Voice Attacks: How Vulnerable are Commercial Voice Control Systems?
Dec 10, 2023



The emergence of Artificial Intelligence (AI)-driven audio attacks has revealed new security vulnerabilities in voice control systems. While researchers have introduced a multitude of attack strategies targeting voice control systems (VCS), the continual advancements of VCS have diminished the impact of many such attacks. Recognizing this dynamic landscape, our study endeavors to comprehensively assess the resilience of commercial voice control systems against a spectrum of malicious audio attacks. Through extensive experimentation, we evaluate six prominent attack techniques across a collection of voice control interfaces and devices. Contrary to prevailing narratives, our results suggest that commercial voice control systems exhibit enhanced resistance to existing threats. Particularly, our research highlights the ineffectiveness of white-box attacks in black-box scenarios. Furthermore, the adversaries encounter substantial obstacles in obtaining precise gradient estimations during query-based interactions with commercial systems, such as Apple Siri and Samsung Bixby. Meanwhile, we find that current defense strategies are not completely immune to advanced attacks. Our findings contribute valuable insights for enhancing defense mechanisms in VCS. Through this survey, we aim to raise awareness within the academic community about the security concerns of VCS and advocate for continued research in this crucial area.
SuperVoice: Text-Independent Speaker Verification Using Ultrasound Energy in Human Speech
May 28, 2022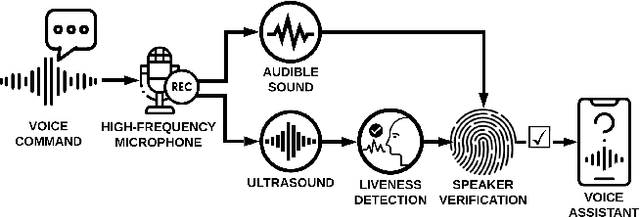
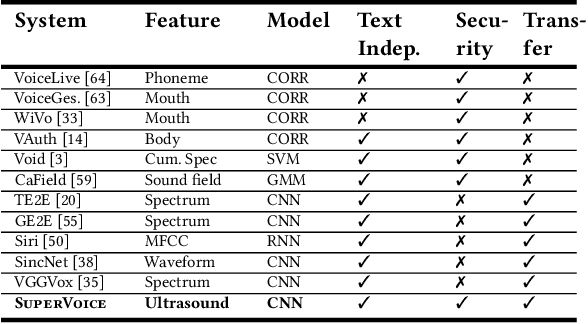
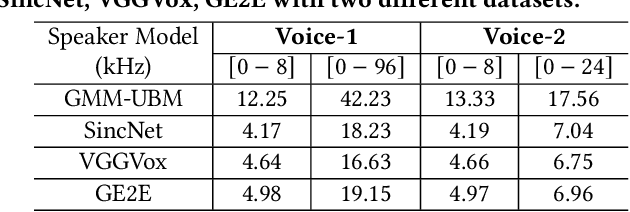
Voice-activated systems are integrated into a variety of desktop, mobile, and Internet-of-Things (IoT) devices. However, voice spoofing attacks, such as impersonation and replay attacks, in which malicious attackers synthesize the voice of a victim or simply replay it, have brought growing security concerns. Existing speaker verification techniques distinguish individual speakers via the spectrographic features extracted from an audible frequency range of voice commands. However, they often have high error rates and/or long delays. In this paper, we explore a new direction of human voice research by scrutinizing the unique characteristics of human speech at the ultrasound frequency band. Our research indicates that the high-frequency ultrasound components (e.g. speech fricatives) from 20 to 48 kHz can significantly enhance the security and accuracy of speaker verification. We propose a speaker verification system, SUPERVOICE that uses a two-stream DNN architecture with a feature fusion mechanism to generate distinctive speaker models. To test the system, we create a speech dataset with 12 hours of audio (8,950 voice samples) from 127 participants. In addition, we create a second spoofed voice dataset to evaluate its security. In order to balance between controlled recordings and real-world applications, the audio recordings are collected from two quiet rooms by 8 different recording devices, including 7 smartphones and an ultrasound microphone. Our evaluation shows that SUPERVOICE achieves 0.58% equal error rate in the speaker verification task, it only takes 120 ms for testing an incoming utterance, outperforming all existing speaker verification systems. Moreover, within 91 ms processing time, SUPERVOICE achieves 0% equal error rate in detecting replay attacks launched by 5 different loudspeakers.
Constraint-Based Inference of Heuristics for Foreign Exchange Trade Model Optimization
May 11, 2021



The Foreign Exchange (Forex) is a large decentralized market, on which trading analysis and algorithmic trading are popular. Research efforts have been focusing on proof of efficiency of certain technical indicators. We demonstrate, however, that the values of indicator functions are not reproducible and often reduce the number of trade opportunities, compared to price-action trading. In this work, we develop two dataset-agnostic Forex trading heuristic templates with high rate of trading signals. In order to determine most optimal parameters for the given heuristic prototypes, we perform a machine learning simulation of 10 years of Forex price data over three low-margin instruments and 6 different OHLC granularities. As a result, we develop a specific and reproducible list of most optimal trade parameters found for each instrument-granularity pair, with 118 pips of average daily profit for the optimized configuration.