 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn-Demand AoI Minimization in Resource-Constrained Cache-Enabled IoT Networks with Energy Harvesting Sensors
Jan 28, 2022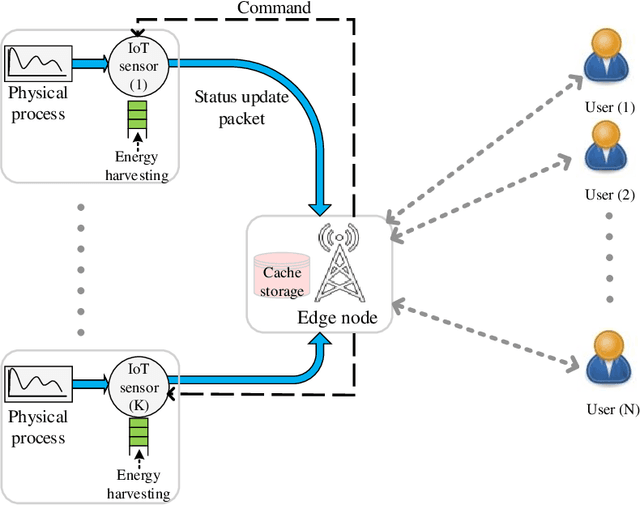
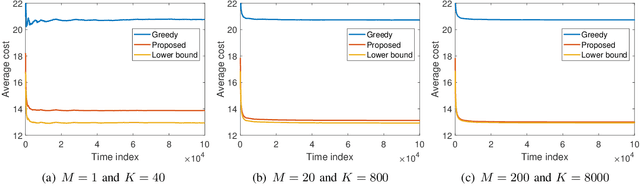
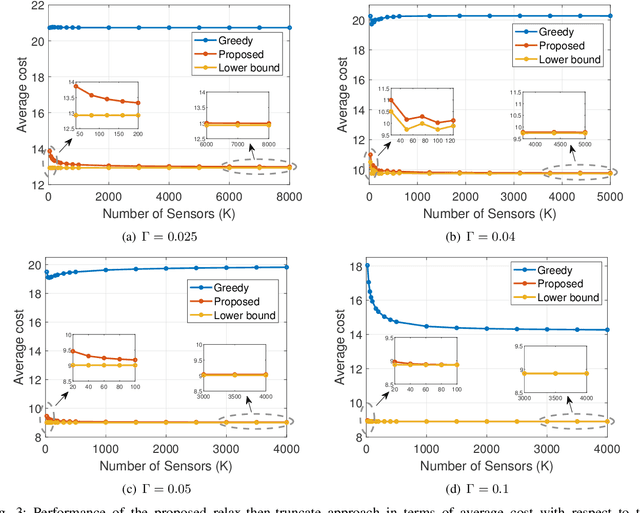
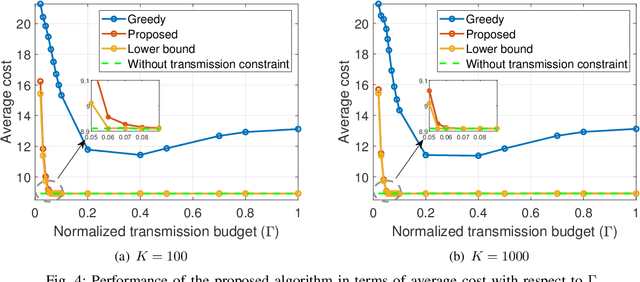
We consider a resource-constrained IoT network, where multiple users make on-demand requests to a cache-enabled edge node to send status updates about various random processes, each monitored by an energy harvesting sensor. The edge node serves users' requests by deciding whether to command the corresponding sensor to send a fresh status update or retrieve the most recently received measurement from the cache. Our objective is to find the best actions of the edge node to minimize the average age of information (AoI) of the received measurements upon request, i.e., average on-demand AoI, subject to per-slot transmission and energy constraints. First, we derive a Markov decision process model and propose an iterative algorithm that obtains an optimal policy. Then, we develop an asymptotically optimal low-complexity algorithm -- termed relax-then-truncate -- and prove that it is optimal as the number of sensors goes to infinity. Simulation results illustrate that the proposed relax-then-truncate approach significantly reduces the average on-demand AoI compared to a request-aware greedy (myopic) policy and also depict that it performs close to the optimal solution even for moderate numbers of sensors.
RIS-aided D2D Communication Design for URLLC Packet Delivery
Nov 26, 2021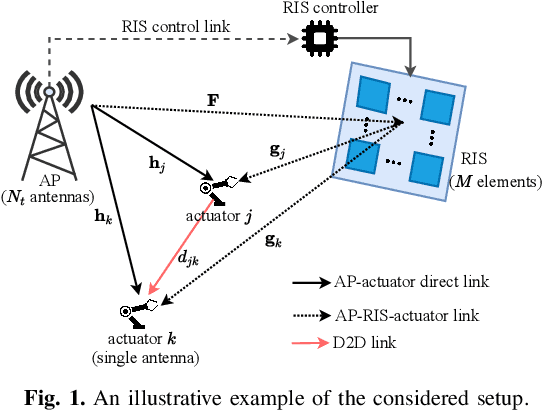
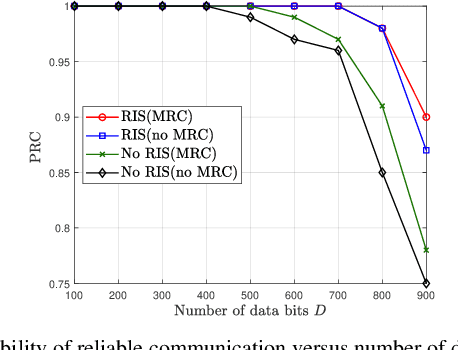
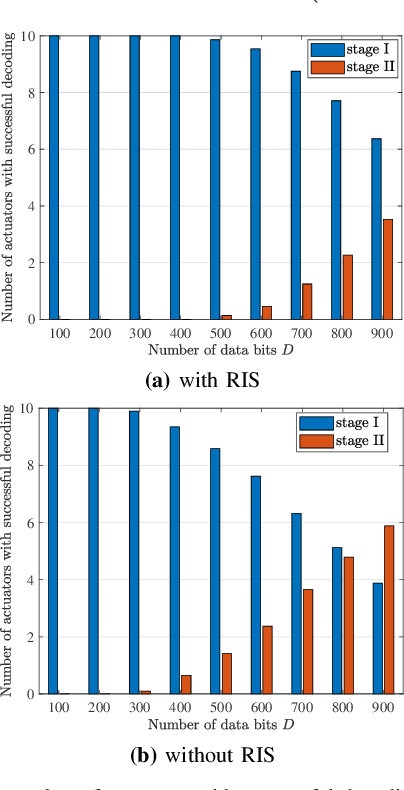
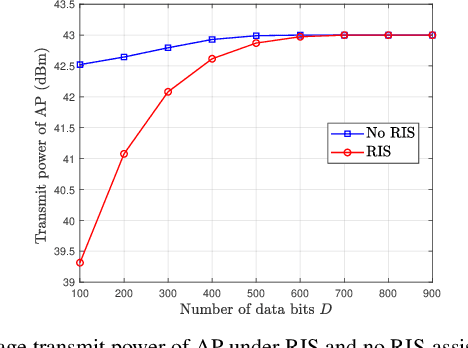
In this paper, we consider a smart factory scenario where a set of actuators receive critical control signals from an access point (AP) with reliability and low latency requirements. We investigate jointly active beamforming at the AP and passive phase shifting at the reconfigurable intelligent surface (RIS) for successfully delivering the control signals from the AP to the actuators within a required time duration. The transmission follows a two-stage design. In the first stage, each actuator can both receive the direct signal from AP and the reflected signal from the RIS. In the second stage, the actuators with successful reception in the first stage, relay the message through the D2D network to the actuators with failed receptions. We formulate a non-convex optimization problem where we first obtain an equivalent but more tractable form by addressing the problem with discrete indicator functions. Then, Frobenius inner product based equality is applied for decoupling the optimization variables. Further, we adopt a penalty-based approach to resolve the rank-one constraints. Finally, we deal with the $\ell_0$-norm by $\ell_1$-norm approximation and add an extra term $\ell_1-\ell_2$ for sparsity. Numerical results reveal that the proposed two-stage RIS-aided D2D communication protocol is effective for enabling reliable communication with latency requirements.
ABC: Attention with Bounded-memory Control
Oct 06, 2021
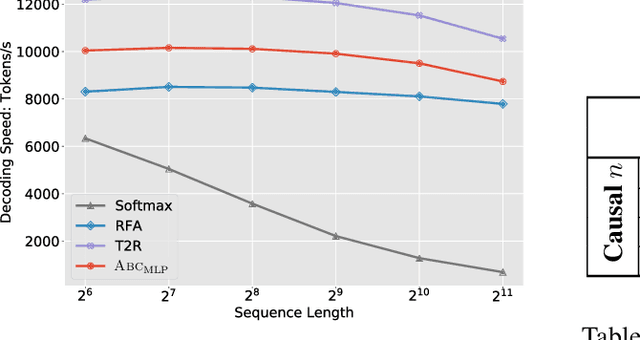
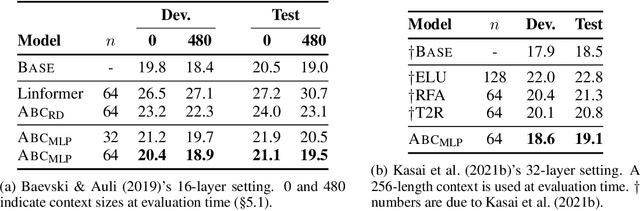
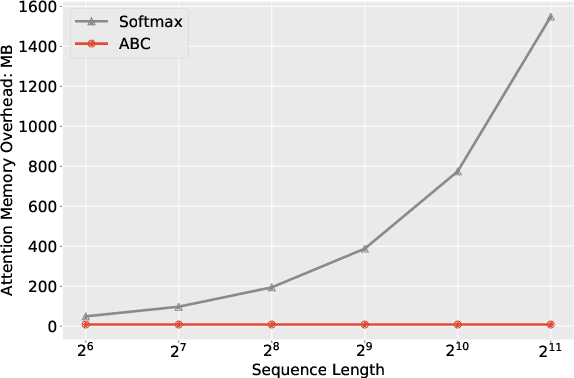
Transformer architectures have achieved state-of-the-art results on a variety of sequence modeling tasks. However, their attention mechanism comes with a quadratic complexity in sequence lengths, making the computational overhead prohibitive, especially for long sequences. Attention context can be seen as a random-access memory with each token taking a slot. Under this perspective, the memory size grows linearly with the sequence length, and so does the overhead of reading from it. One way to improve the efficiency is to bound the memory size. We show that disparate approaches can be subsumed into one abstraction, attention with bounded-memory control (ABC), and they vary in their organization of the memory. ABC reveals new, unexplored possibilities. First, it connects several efficient attention variants that would otherwise seem apart. Second, this abstraction gives new insights--an established approach (Wang et al., 2020b) previously thought to be not applicable in causal attention, actually is. Last, we present a new instance of ABC, which draws inspiration from existing ABC approaches, but replaces their heuristic memory-organizing functions with a learned, contextualized one. Our experiments on language modeling, machine translation, and masked language model finetuning show that our approach outperforms previous efficient attention models; compared to the strong transformer baselines, it significantly improves the inference time and space efficiency with no or negligible accuracy loss.
Sentence Bottleneck Autoencoders from Transformer Language Models
Aug 31, 2021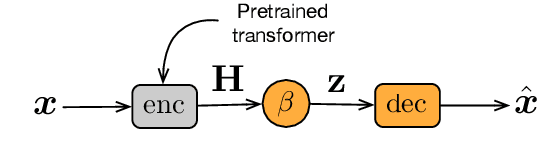
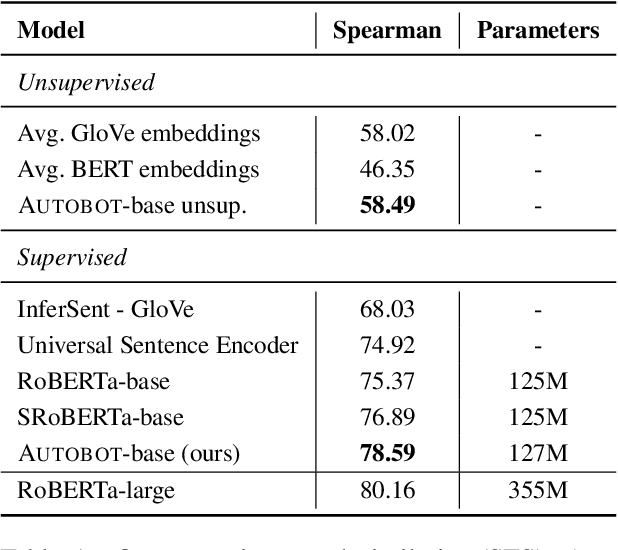
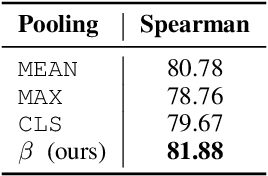
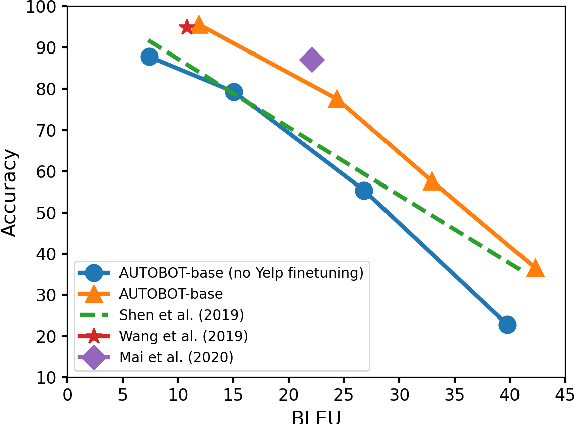
Representation learning for text via pretraining a language model on a large corpus has become a standard starting point for building NLP systems. This approach stands in contrast to autoencoders, also trained on raw text, but with the objective of learning to encode each input as a vector that allows full reconstruction. Autoencoders are attractive because of their latent space structure and generative properties. We therefore explore the construction of a sentence-level autoencoder from a pretrained, frozen transformer language model. We adapt the masked language modeling objective as a generative, denoising one, while only training a sentence bottleneck and a single-layer modified transformer decoder. We demonstrate that the sentence representations discovered by our model achieve better quality than previous methods that extract representations from pretrained transformers on text similarity tasks, style transfer (an example of controlled generation), and single-sentence classification tasks in the GLUE benchmark, while using fewer parameters than large pretrained models.
Finetuning Pretrained Transformers into RNNs
Mar 24, 2021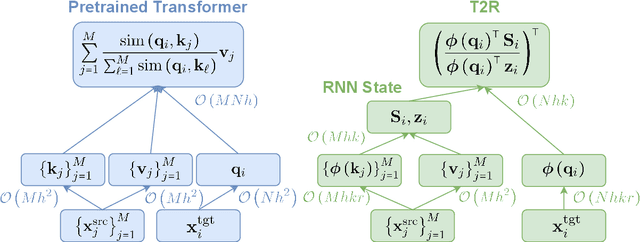
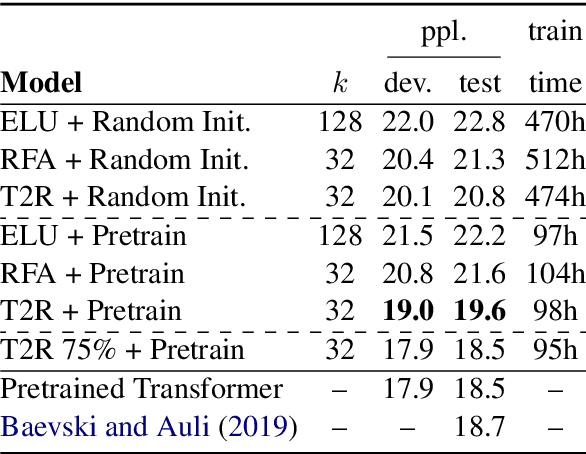
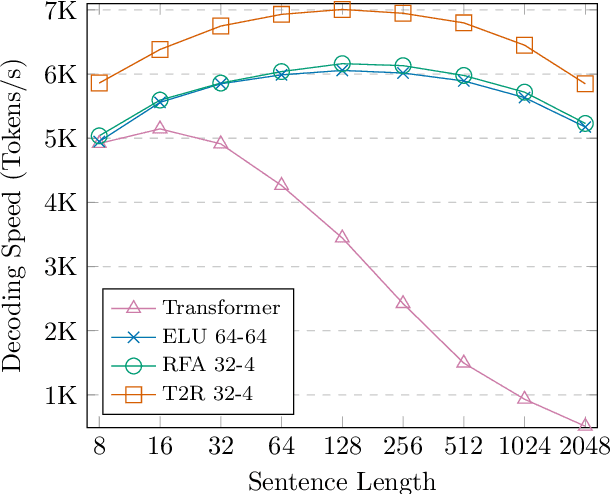
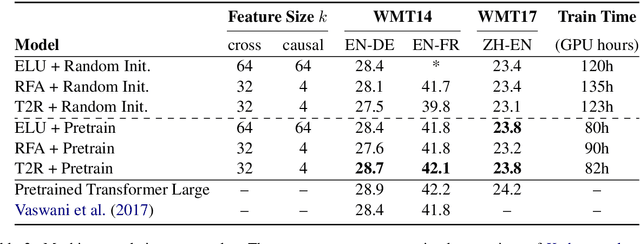
Transformers have outperformed recurrent neural networks (RNNs) in natural language generation. This comes with a significant computational overhead, as the attention mechanism scales with a quadratic complexity in sequence length. Efficient transformer variants have received increasing interest from recent works. Among them, a linear-complexity recurrent variant has proven well suited for autoregressive generation. It approximates the softmax attention with randomized or heuristic feature maps, but can be difficult to train or yield suboptimal accuracy. This work aims to convert a pretrained transformer into its efficient recurrent counterpart, improving the efficiency while retaining the accuracy. Specifically, we propose a swap-then-finetune procedure: in an off-the-shelf pretrained transformer, we replace the softmax attention with its linear-complexity recurrent alternative and then finetune. With a learned feature map, our approach provides an improved tradeoff between efficiency and accuracy over the standard transformer and other recurrent variants. We also show that the finetuning process needs lower training cost than training these recurrent variants from scratch. As many recent models for natural language tasks are increasingly dependent on large-scale pretrained transformers, this work presents a viable approach to improving inference efficiency without repeating the expensive pretraining process.
Random Feature Attention
Mar 19, 2021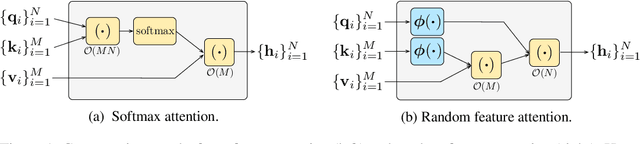
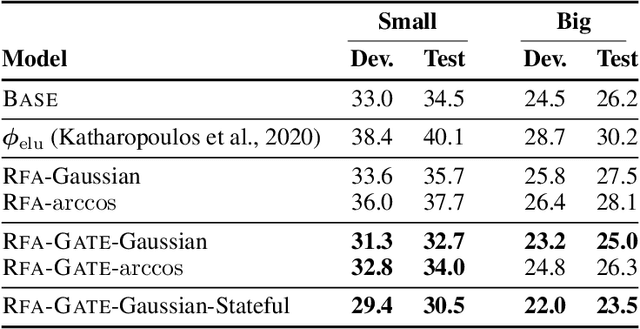
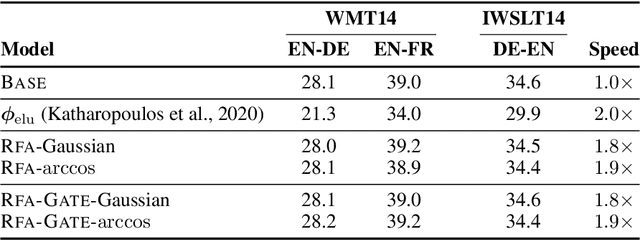
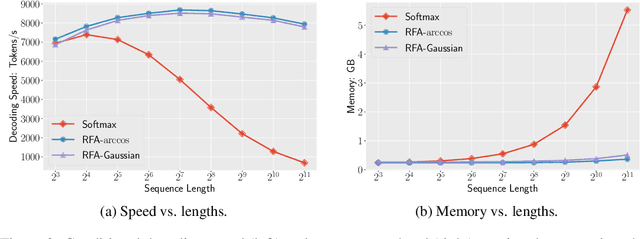
Transformers are state-of-the-art models for a variety of sequence modeling tasks. At their core is an attention function which models pairwise interactions between the inputs at every timestep. While attention is powerful, it does not scale efficiently to long sequences due to its quadratic time and space complexity in the sequence length. We propose RFA, a linear time and space attention that uses random feature methods to approximate the softmax function, and explore its application in transformers. RFA can be used as a drop-in replacement for conventional softmax attention and offers a straightforward way of learning with recency bias through an optional gating mechanism. Experiments on language modeling and machine translation demonstrate that RFA achieves similar or better performance compared to strong transformer baselines. In the machine translation experiment, RFA decodes twice as fast as a vanilla transformer. Compared to existing efficient transformer variants, RFA is competitive in terms of both accuracy and efficiency on three long text classification datasets. Our analysis shows that RFA's efficiency gains are especially notable on long sequences, suggesting that RFA will be particularly useful in tasks that require working with large inputs, fast decoding speed, or low memory footprints.
Autonomous Maintenance in IoT Networks via AoI-driven Deep Reinforcement Learning
Dec 31, 2020
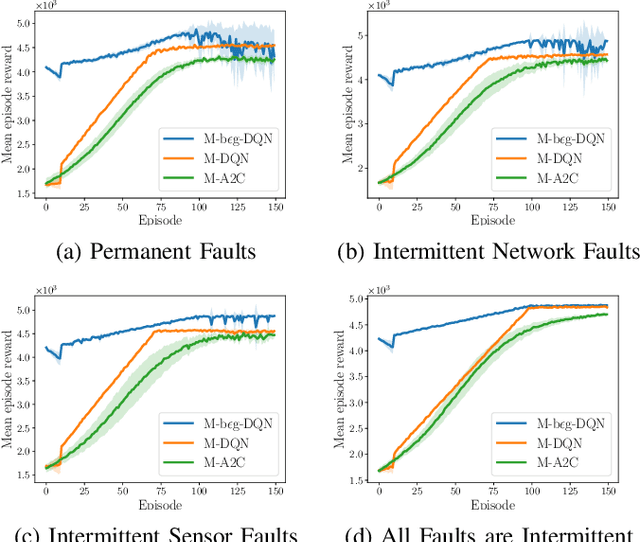
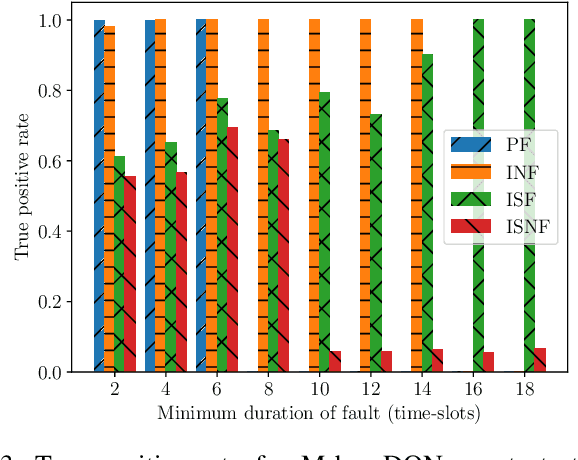
Internet of Things (IoT) with its growing number of deployed devices and applications raises significant challenges for network maintenance procedures. In this work, we formulate a problem of autonomous maintenance in IoT networks as a Partially Observable Markov Decision Process. Subsequently, we utilize Deep Reinforcement Learning algorithms (DRL) to train agents that decide if a maintenance procedure is in order or not and, in the former case, the proper type of maintenance needed. To avoid wasting the scarce resources of IoT networks we utilize the Age of Information (AoI) metric as a reward signal for the training of the smart agents. AoI captures the freshness of the sensory data which are transmitted by the IoT sensors as part of their normal service provision. Numerical results indicate that AoI integrates enough information about the past and present states of the system to be successfully used in the training of smart agents for the autonomous maintenance of the network.
QoS Aware Robot Trajectory Optimization with IRS-Assisted Millimeter-Wave Communications
Dec 19, 2020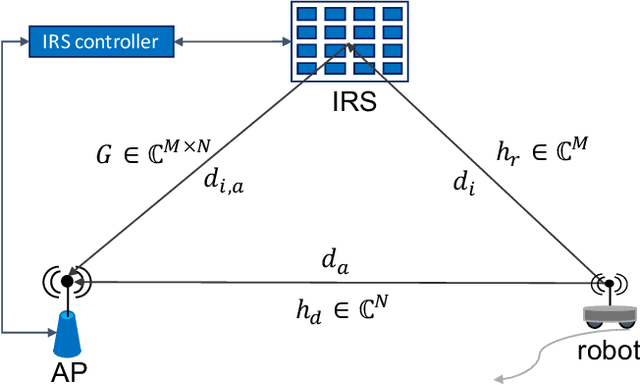
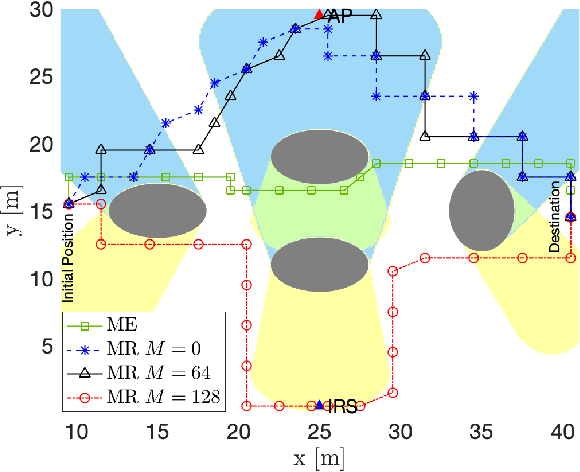
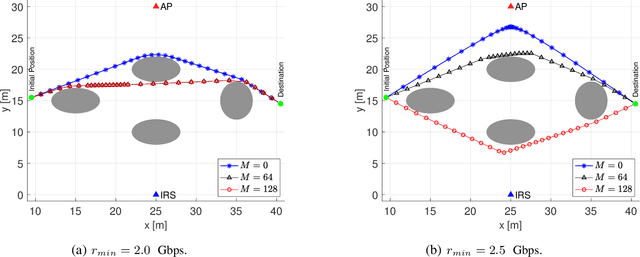
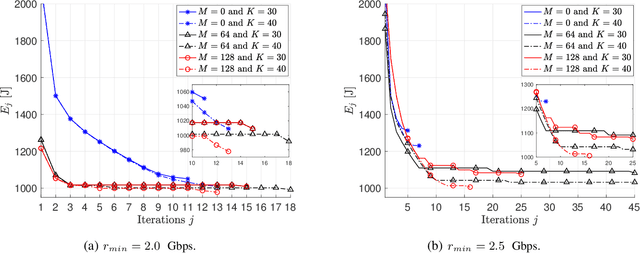
This paper considers the motion energy minimization problem for a wirelessly connected robot using millimeter-wave (mm-wave) communications. These are assisted by an intelligent reflective surface (IRS) that enhances the coverage at such high frequencies characterized by high blockage sensitivity. The robot is subject to time and uplink communication quality of service (QoS) constraints. This is a fundamental problem in fully automated factories that characterize Industry 4.0, where robots may have to perform tasks with given deadlines while maximizing the battery autonomy and communication efficiency. To account for the mutual dependence between robot position and communication QoS, we propose a joint optimization of robot trajectory and beamforming at the IRS and access point (AP). We present a solution that first exploits mm-wave channel characteristics to decouple beamforming and trajectory optimization. Then, the latter is solved by a successive-convex optimization-based algorithm. The algorithm takes into account the obstacles' positions and a radio map to avoid collisions and poorly covered areas. We prove that the algorithm can converge to a solution satisfying the Karush-Kuhn-Tucker (KKT) conditions. The simulation results show a dramatic reduction of the motion energy consumption with respect to methods that aim to find maximum-rate trajectories. Moreover, we show how the IRS and the beamforming optimization improve the motion energy efficiency of the robot.
Plug and Play Autoencoders for Conditional Text Generation
Oct 12, 2020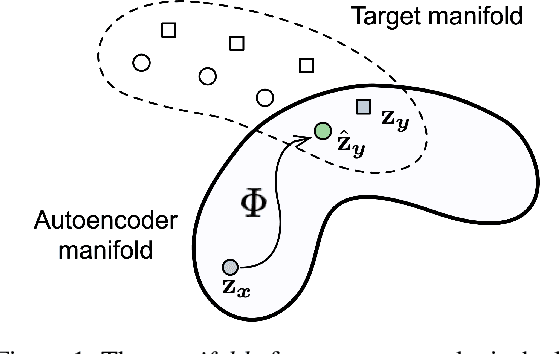
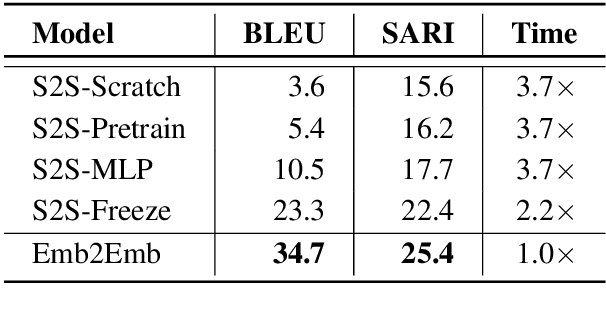

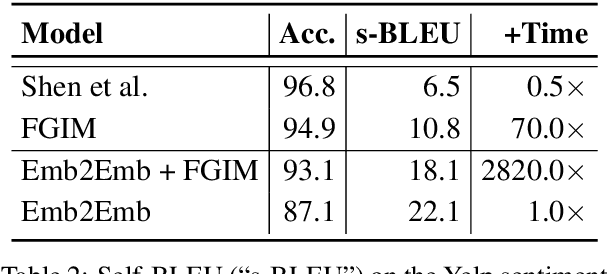
Text autoencoders are commonly used for conditional generation tasks such as style transfer. We propose methods which are plug and play, where any pretrained autoencoder can be used, and only require learning a mapping within the autoencoder's embedding space, training embedding-to-embedding (Emb2Emb). This reduces the need for labeled training data for the task and makes the training procedure more efficient. Crucial to the success of this method is a loss term for keeping the mapped embedding on the manifold of the autoencoder and a mapping which is trained to navigate the manifold by learning offset vectors. Evaluations on style transfer tasks both with and without sequence-to-sequence supervision show that our method performs better than or comparable to strong baselines while being up to four times faster.
Grounded Compositional Outputs for Adaptive Language Modeling
Oct 05, 2020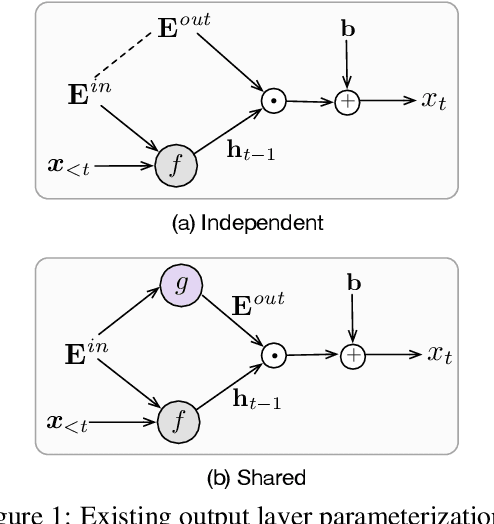

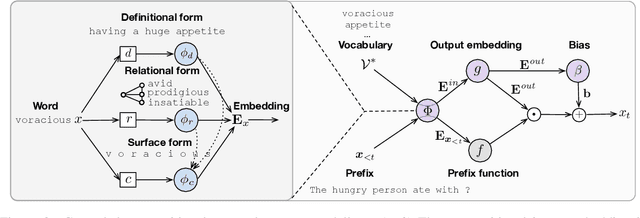
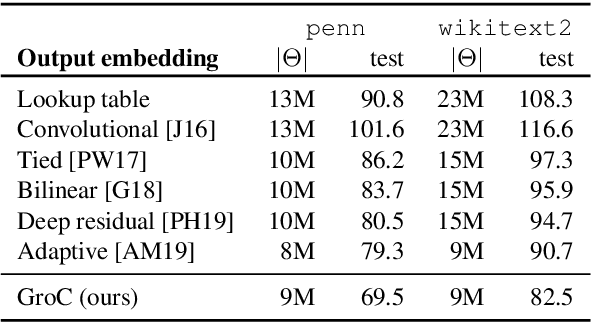
Language models have emerged as a central component across NLP, and a great deal of progress depends on the ability to cheaply adapt them (e.g., through finetuning) to new domains and tasks. A language model's vocabulary$-$typically selected before training and permanently fixed later$-$affects its size and is part of what makes it resistant to such adaptation. Prior work has used compositional input embeddings based on surface forms to ameliorate this issue. In this work, we go one step beyond and propose a fully compositional output embedding layer for language models, which is further grounded in information from a structured lexicon (WordNet), namely semantically related words and free-text definitions. To our knowledge, the result is the first word-level language model with a size that does not depend on the training vocabulary. We evaluate the model on conventional language modeling as well as challenging cross-domain settings with an open vocabulary, finding that it matches or outperforms previous state-of-the-art output embedding methods and adaptation approaches. Our analysis attributes the improvements to sample efficiency: our model is more accurate for low-frequency words.