 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLTLZinc: a Benchmarking Framework for Continual Learning and Neuro-Symbolic Temporal Reasoning
Jul 23, 2025



Neuro-symbolic artificial intelligence aims to combine neural architectures with symbolic approaches that can represent knowledge in a human-interpretable formalism. Continual learning concerns with agents that expand their knowledge over time, improving their skills while avoiding to forget previously learned concepts. Most of the existing approaches for neuro-symbolic artificial intelligence are applied to static scenarios only, and the challenging setting where reasoning along the temporal dimension is necessary has been seldom explored. In this work we introduce LTLZinc, a benchmarking framework that can be used to generate datasets covering a variety of different problems, against which neuro-symbolic and continual learning methods can be evaluated along the temporal and constraint-driven dimensions. Our framework generates expressive temporal reasoning and continual learning tasks from a linear temporal logic specification over MiniZinc constraints, and arbitrary image classification datasets. Fine-grained annotations allow multiple neural and neuro-symbolic training settings on the same generated datasets. Experiments on six neuro-symbolic sequence classification and four class-continual learning tasks generated by LTLZinc, demonstrate the challenging nature of temporal learning and reasoning, and highlight limitations of current state-of-the-art methods. We release the LTLZinc generator and ten ready-to-use tasks to the neuro-symbolic and continual learning communities, in the hope of fostering research towards unified temporal learning and reasoning frameworks.
A Scalable Approach to Probabilistic Neuro-Symbolic Verification
Feb 05, 2025



Neuro-Symbolic Artificial Intelligence (NeSy AI) has emerged as a promising direction for integrating neural learning with symbolic reasoning. In the probabilistic variant of such systems, a neural network first extracts a set of symbols from sub-symbolic input, which are then used by a symbolic component to reason in a probabilistic manner towards answering a query. In this work, we address the problem of formally verifying the robustness of such NeSy probabilistic reasoning systems, therefore paving the way for their safe deployment in critical domains. We analyze the complexity of solving this problem exactly, and show that it is $\mathrm{NP}^{\# \mathrm{P}}$-hard. To overcome this issue, we propose the first approach for approximate, relaxation-based verification of probabilistic NeSy systems. We demonstrate experimentally that the proposed method scales exponentially better than solver-based solutions and apply our technique to a real-world autonomous driving dataset, where we verify a safety property under large input dimensionalities and network sizes.
NeSyA: Neurosymbolic Automata
Dec 10, 2024Neurosymbolic Artificial Intelligence (NeSy) has emerged as a promising direction to integrate low level perception with high level reasoning. Unfortunately, little attention has been given to developing NeSy systems tailored to temporal/sequential problems. This entails reasoning symbolically over sequences of subsymbolic observations towards a target prediction. We show that using a probabilistic semantics symbolic automata, which combine the power of automata for temporal structure specification with that of propositional logic, can be used to reason efficiently and differentiably over subsymbolic sequences. The proposed system, which we call NeSyA (Neuro Symbolic Automata), is shown to either scale or perform better than existing NeSy approaches when applied to problems with a temporal component.
Regulatory Compliance through Doc2Doc Information Retrieval: A case study in EU/UK legislation where text similarity has limitations
Jan 26, 2021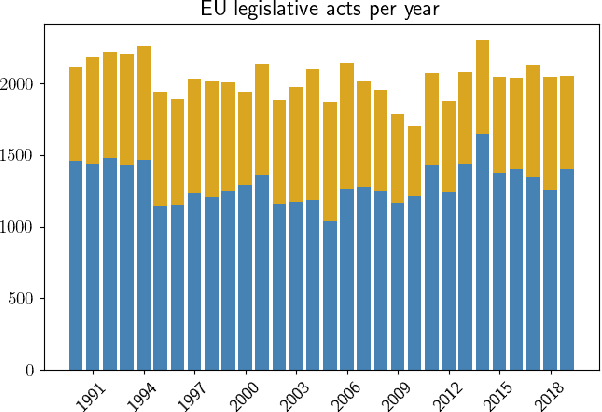
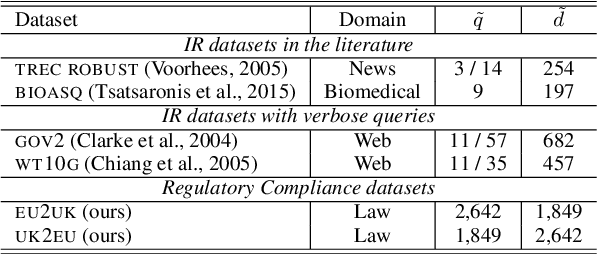
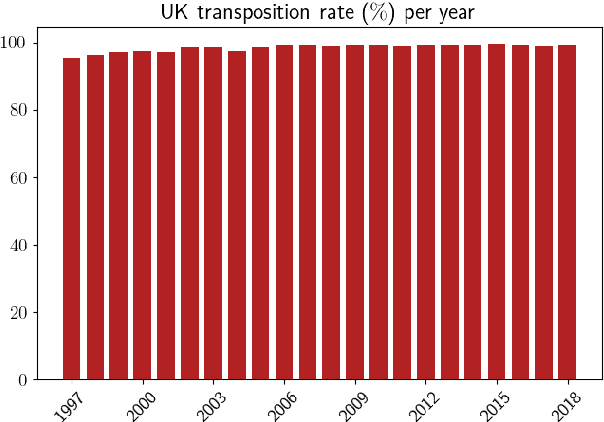

Major scandals in corporate history have urged the need for regulatory compliance, where organizations need to ensure that their controls (processes) comply with relevant laws, regulations, and policies. However, keeping track of the constantly changing legislation is difficult, thus organizations are increasingly adopting Regulatory Technology (RegTech) to facilitate the process. To this end, we introduce regulatory information retrieval (REG-IR), an application of document-to-document information retrieval (DOC2DOC IR), where the query is an entire document making the task more challenging than traditional IR where the queries are short. Furthermore, we compile and release two datasets based on the relationships between EU directives and UK legislation. We experiment on these datasets using a typical two-step pipeline approach comprising a pre-fetcher and a neural re-ranker. Experimenting with various pre-fetchers from BM25 to k nearest neighbors over representations from several BERT models, we show that fine-tuning a BERT model on an in-domain classification task produces the best representations for IR. We also show that neural re-rankers under-perform due to contradicting supervision, i.e., similar query-document pairs with opposite labels. Thus, they are biased towards the pre-fetcher's score. Interestingly, applying a date filter further improves the performance, showcasing the importance of the time dimension.
Layer-wise Guided Training for BERT: Learning Incrementally Refined Document Representations
Oct 12, 2020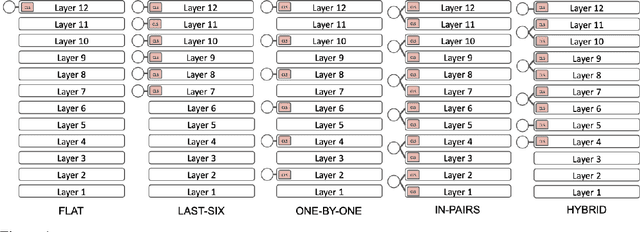
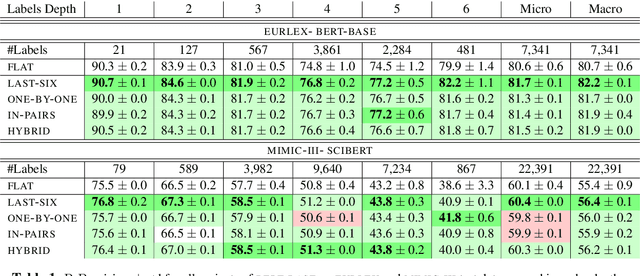
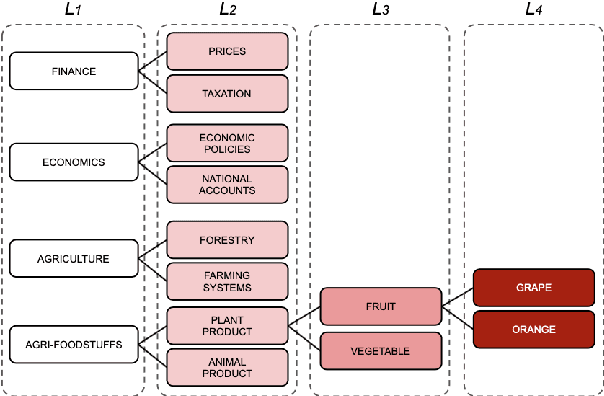
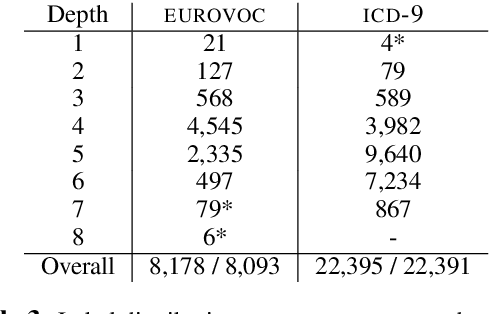
Although BERT is widely used by the NLP community, little is known about its inner workings. Several attempts have been made to shed light on certain aspects of BERT, often with contradicting conclusions. A much raised concern focuses on BERT's over-parameterization and under-utilization issues. To this end, we propose o novel approach to fine-tune BERT in a structured manner. Specifically, we focus on Large Scale Multilabel Text Classification (LMTC) where documents are assigned with one or more labels from a large predefined set of hierarchically organized labels. Our approach guides specific BERT layers to predict labels from specific hierarchy levels. Experimenting with two LMTC datasets we show that this structured fine-tuning approach not only yields better classification results but also leads to better parameter utilization.