 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA 3D Reconstruction Benchmark for Asset Inspection
Mar 18, 2026Asset management requires accurate 3D models to inform the maintenance, repair, and assessment of buildings, maritime vessels, and other key structures as they age. These downstream applications rely on high-fidelity models produced from aerial surveys in close proximity to the asset, enabling operators to locate and characterise deterioration or damage and plan repairs. Captured images typically have high overlap between adjacent camera poses, sufficient detail at millimetre scale, and challenging visual appearances such as reflections and transparency. However, existing 3D reconstruction datasets lack examples of these conditions, making it difficult to benchmark methods for this task. We present a new dataset with ground truth depth maps, camera poses, and mesh models of three synthetic scenes with simulated inspection trajectories and varying levels of surface condition on non-Lambertian scene content. We evaluate state-of-the-art reconstruction methods on this dataset. Our results demonstrate that current approaches struggle significantly with the dense capture trajectories and complex surface conditions inherent to this domain, exposing a critical scalability gap and pointing toward new research directions for deployable 3D reconstruction in asset inspection. Project page: https://roboticimaging.org/Projects/asset-inspection-dataset/
Light Field Based 6DoF Tracking of Previously Unobserved Objects
Dec 15, 2025Object tracking is an important step in robotics and reautonomous driving pipelines, which has to generalize to previously unseen and complex objects. Existing high-performing methods often rely on pre-captured object views to build explicit reference models, which restricts them to a fixed set of known objects. However, such reference models can struggle with visually complex appearance, reducing the quality of tracking. In this work, we introduce an object tracking method based on light field images that does not depend on a pre-trained model, while being robust to complex visual behavior, such as reflections. We extract semantic and geometric features from light field inputs using vision foundation models and convert them into view-dependent Gaussian splats. These splats serve as a unified object representation, supporting differentiable rendering and pose optimization. We further introduce a light field object tracking dataset containing challenging reflective objects with precise ground truth poses. Experiments demonstrate that our method is competitive with state-of-the-art model-based trackers in these difficult cases, paving the way toward universal object tracking in robotic systems. Code/data available at https://github.com/nagonch/LiFT-6DoF.
Segment Anything in Light Fields for Real-Time Applications via Constrained Prompting
Nov 21, 2024



Segmented light field images can serve as a powerful representation in many of computer vision tasks exploiting geometry and appearance of objects, such as object pose tracking. In the light field domain, segmentation presents an additional objective of recognizing the same segment through all the views. Segment Anything Model 2 (SAM 2) allows producing semantically meaningful segments for monocular images and videos. However, using SAM 2 directly on light fields is highly ineffective due to unexploited constraints. In this work, we present a novel light field segmentation method that adapts SAM 2 to the light field domain without retraining or modifying the model. By utilizing the light field domain constraints, the method produces high quality and view-consistent light field masks, outperforming the SAM 2 video tracking baseline and working 7 times faster, with a real-time speed. We achieve this by exploiting the epipolar geometry cues to propagate the masks between the views, probing the SAM 2 latent space to estimate their occlusion, and further prompting SAM 2 for their refinement.
EVOPS Benchmark: Evaluation of Plane Segmentation from RGBD and LiDAR Data
Apr 12, 2022


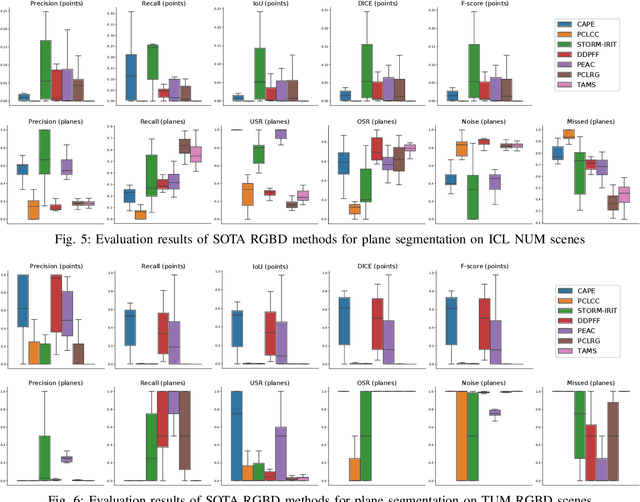
This paper provides the EVOPS dataset for plane segmentation from 3D data, both from RGBD images and LiDAR point clouds (PC). We have designed two annotation methodologies (RGBD and LiDAR) running on well-known and widely-used datasets and we have provided a complete set of benchmarking tools including point, planes and segmentation metrics. The data includes a total number of 10k RGBD and 7K LiDAR frames over different selected scenes which consist of high quality segmented planes. The experiments report quality of SOTA methods for RGBD plane segmentation on our annotated data. All labeled data and benchmark tools used have been made publicly available.