 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA 3D Reconstruction Benchmark for Asset Inspection
Mar 18, 2026Asset management requires accurate 3D models to inform the maintenance, repair, and assessment of buildings, maritime vessels, and other key structures as they age. These downstream applications rely on high-fidelity models produced from aerial surveys in close proximity to the asset, enabling operators to locate and characterise deterioration or damage and plan repairs. Captured images typically have high overlap between adjacent camera poses, sufficient detail at millimetre scale, and challenging visual appearances such as reflections and transparency. However, existing 3D reconstruction datasets lack examples of these conditions, making it difficult to benchmark methods for this task. We present a new dataset with ground truth depth maps, camera poses, and mesh models of three synthetic scenes with simulated inspection trajectories and varying levels of surface condition on non-Lambertian scene content. We evaluate state-of-the-art reconstruction methods on this dataset. Our results demonstrate that current approaches struggle significantly with the dense capture trajectories and complex surface conditions inherent to this domain, exposing a critical scalability gap and pointing toward new research directions for deployable 3D reconstruction in asset inspection. Project page: https://roboticimaging.org/Projects/asset-inspection-dataset/
Light Field Based 6DoF Tracking of Previously Unobserved Objects
Dec 15, 2025Object tracking is an important step in robotics and reautonomous driving pipelines, which has to generalize to previously unseen and complex objects. Existing high-performing methods often rely on pre-captured object views to build explicit reference models, which restricts them to a fixed set of known objects. However, such reference models can struggle with visually complex appearance, reducing the quality of tracking. In this work, we introduce an object tracking method based on light field images that does not depend on a pre-trained model, while being robust to complex visual behavior, such as reflections. We extract semantic and geometric features from light field inputs using vision foundation models and convert them into view-dependent Gaussian splats. These splats serve as a unified object representation, supporting differentiable rendering and pose optimization. We further introduce a light field object tracking dataset containing challenging reflective objects with precise ground truth poses. Experiments demonstrate that our method is competitive with state-of-the-art model-based trackers in these difficult cases, paving the way toward universal object tracking in robotic systems. Code/data available at https://github.com/nagonch/LiFT-6DoF.
Multi-view Disparity Estimation Using a Novel Gradient Consistency Model
May 27, 2024Variational approaches to disparity estimation typically use a linearised brightness constancy constraint, which only applies in smooth regions and over small distances. Accordingly, current variational approaches rely on a schedule to progressively include image data. This paper proposes the use of Gradient Consistency information to assess the validity of the linearisation; this information is used to determine the weights applied to the data term as part of an analytically inspired Gradient Consistency Model. The Gradient Consistency Model penalises the data term for view pairs that have a mismatch between the spatial gradients in the source view and the spatial gradients in the target view. Instead of relying on a tuned or learned schedule, the Gradient Consistency Model is self-scheduling, since the weights evolve as the algorithm progresses. We show that the Gradient Consistency Model outperforms standard coarse-to-fine schemes and the recently proposed progressive inclusion of views approach in both rate of convergence and accuracy.
Welsch Based Multiview Disparity Estimation
Oct 02, 2021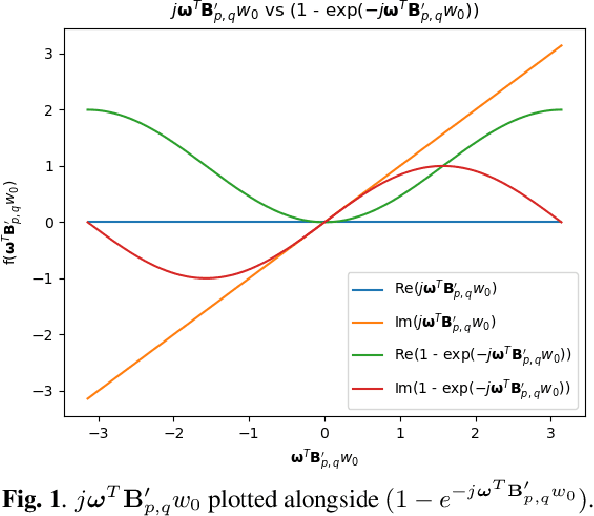
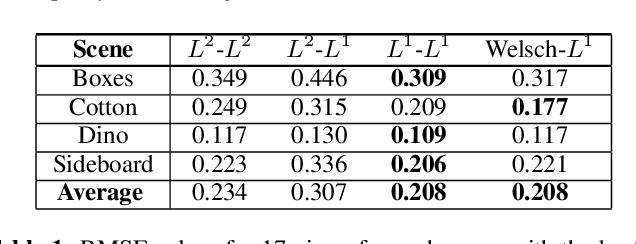

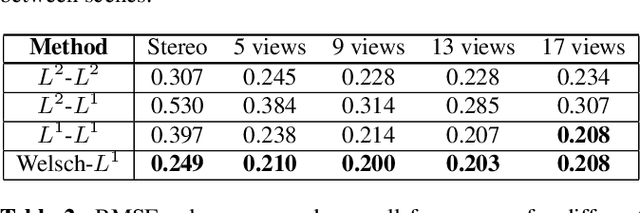
In this work, we explore disparity estimation from a high number of views. We experimentally identify occlusions as a key challenge for disparity estimation for applications with high numbers of views. In particular, occlusions can actually result in a degradation in accuracy as more views are added to a dataset. We propose the use of a Welsch loss function for the data term in a global variational framework for disparity estimation. We also propose a disciplined warping strategy and a progressive inclusion of views strategy that can reduce the need for coarse to fine strategies that discard high spatial frequency components from the early iterations. Experimental results demonstrate that the proposed approach produces superior and/or more robust estimates than other conventional variational approaches.
* Published in 2021 IEEE International Conference on Image Processing (ICIP), 5 pages