 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatrix Completion via Factorizing Polynomials
Feb 14, 2018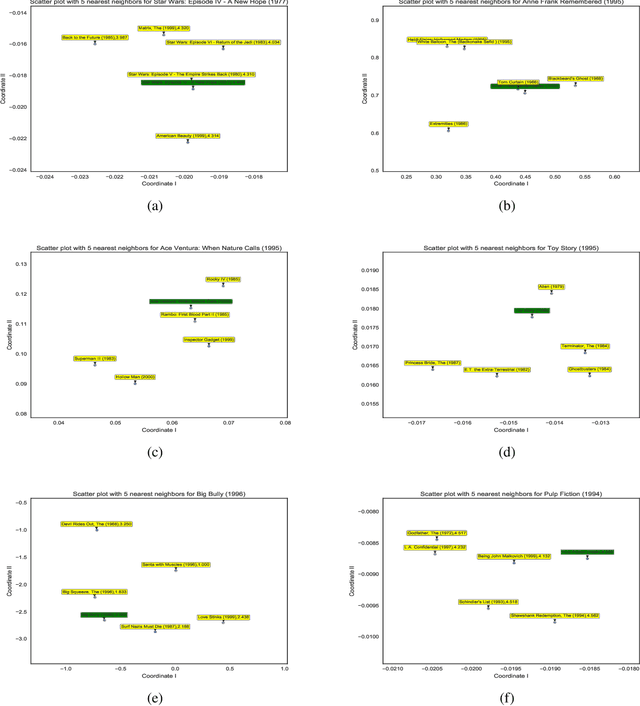

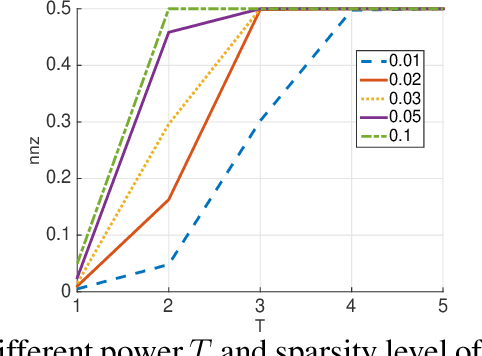
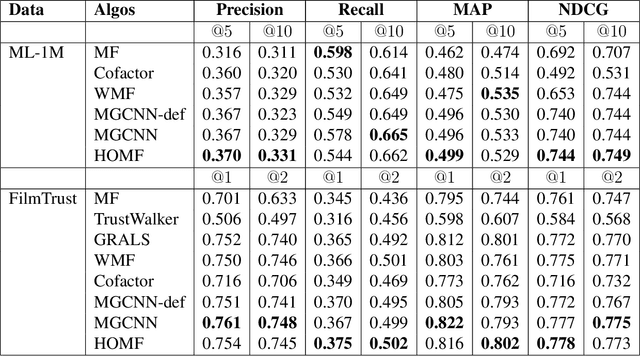
Predicting unobserved entries of a partially observed matrix has found wide applicability in several areas, such as recommender systems, computational biology, and computer vision. Many scalable methods with rigorous theoretical guarantees have been developed for algorithms where the matrix is factored into low-rank components, and embeddings are learned for the row and column entities. While there has been recent research on incorporating explicit side information in the low-rank matrix factorization setting, often implicit information can be gleaned from the data, via higher-order interactions among entities. Such implicit information is especially useful in cases where the data is very sparse, as is often the case in real-world datasets. In this paper, we design a method to learn embeddings in the context of recommendation systems, using the observation that higher powers of a graph transition probability matrix encode the probability that a random walker will hit that node in a given number of steps. We develop a coordinate descent algorithm to solve the resulting optimization, that makes explicit computation of the higher order powers of the matrix redundant, preserving sparsity and making computations efficient. Experiments on several datasets show that our method, that can use higher order information, outperforms methods that only use explicitly available side information, those that use only second-order implicit information and in some cases, methods based on deep neural networks as well.
Dynamic Word Embeddings for Evolving Semantic Discovery
Feb 13, 2018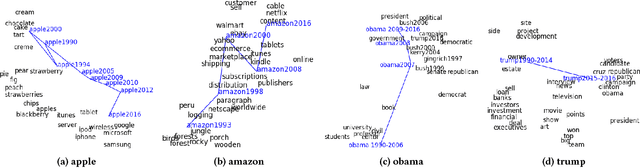
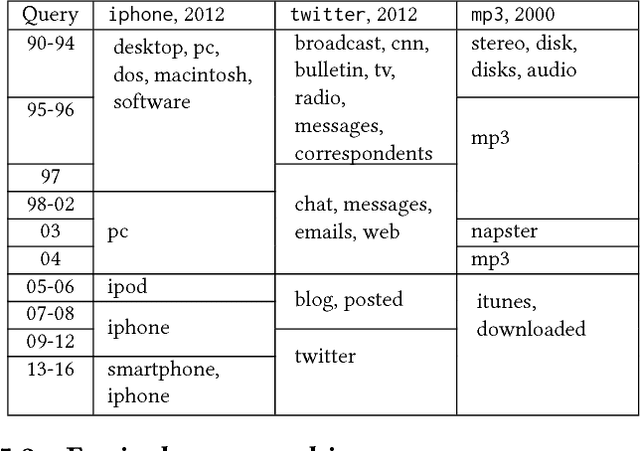
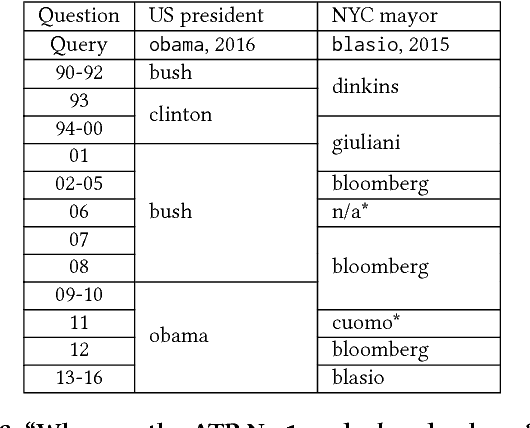
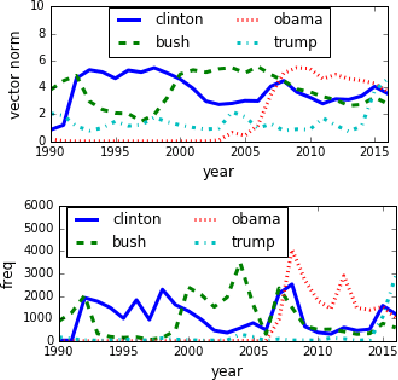
Word evolution refers to the changing meanings and associations of words throughout time, as a byproduct of human language evolution. By studying word evolution, we can infer social trends and language constructs over different periods of human history. However, traditional techniques such as word representation learning do not adequately capture the evolving language structure and vocabulary. In this paper, we develop a dynamic statistical model to learn time-aware word vector representation. We propose a model that simultaneously learns time-aware embeddings and solves the resulting "alignment problem". This model is trained on a crawled NYTimes dataset. Additionally, we develop multiple intuitive evaluation strategies of temporal word embeddings. Our qualitative and quantitative tests indicate that our method not only reliably captures this evolution over time, but also consistently outperforms state-of-the-art temporal embedding approaches on both semantic accuracy and alignment quality.
A Simple Approach to Learn Polysemous Word Embeddings
Aug 14, 2017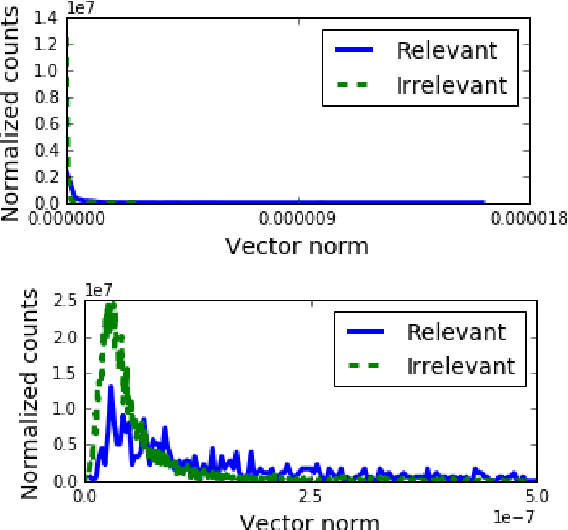
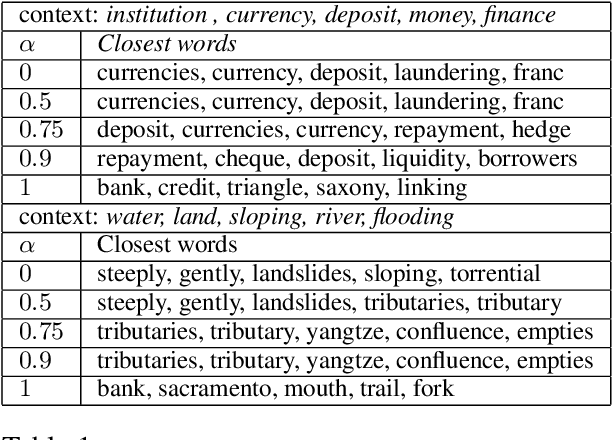
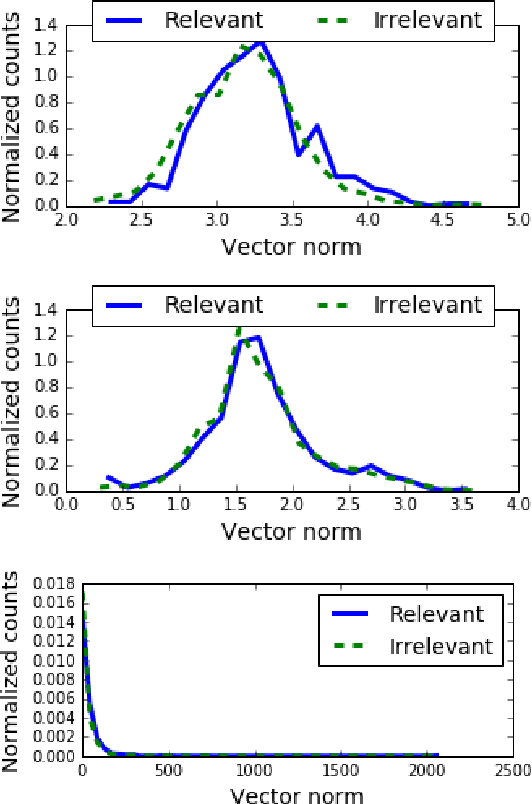
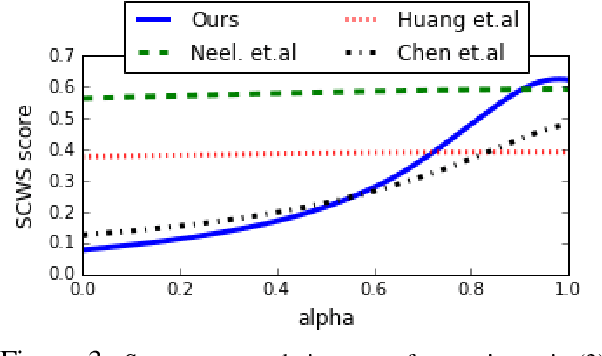
Many NLP applications require disambiguating polysemous words. Existing methods that learn polysemous word vector representations involve first detecting various senses and optimizing the sense-specific embeddings separately, which are invariably more involved than single sense learning methods such as word2vec. Evaluating these methods is also problematic, as rigorous quantitative evaluations in this space is limited, especially when compared with single-sense embeddings. In this paper, we propose a simple method to learn a word representation, given any context. Our method only requires learning the usual single sense representation, and coefficients that can be learnt via a single pass over the data. We propose several new test sets for evaluating word sense induction, relevance detection, and contextual word similarity, significantly supplementing the currently available tests. Results on these and other tests show that while our method is embarrassingly simple, it achieves excellent results when compared to the state of the art models for unsupervised polysemous word representation learning.
On Learning High Dimensional Structured Single Index Models
Nov 29, 2016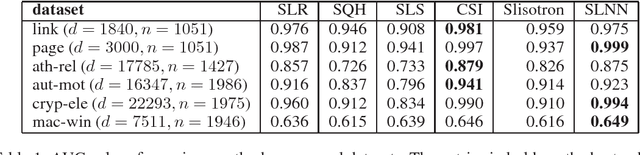
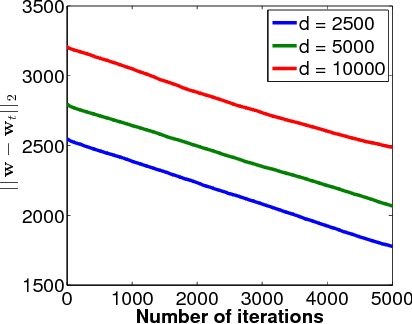


Single Index Models (SIMs) are simple yet flexible semi-parametric models for machine learning, where the response variable is modeled as a monotonic function of a linear combination of features. Estimation in this context requires learning both the feature weights and the nonlinear function that relates features to observations. While methods have been described to learn SIMs in the low dimensional regime, a method that can efficiently learn SIMs in high dimensions, and under general structural assumptions, has not been forthcoming. In this paper, we propose computationally efficient algorithms for SIM inference in high dimensions with structural constraints. Our general approach specializes to sparsity, group sparsity, and low-rank assumptions among others. Experiments show that the proposed method enjoys superior predictive performance when compared to generalized linear models, and achieves results comparable to or better than single layer feedforward neural networks with significantly less computational cost.
Structured Sparse Regression via Greedy Hard-Thresholding
May 27, 2016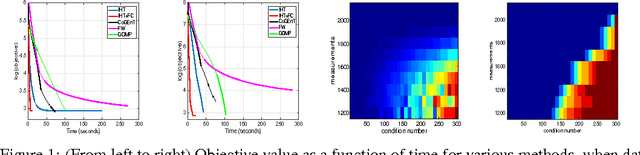
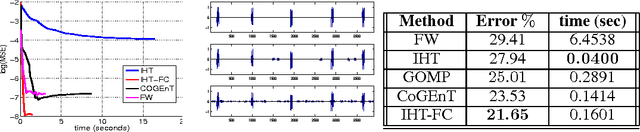
Several learning applications require solving high-dimensional regression problems where the relevant features belong to a small number of (overlapping) groups. For very large datasets and under standard sparsity constraints, hard thresholding methods have proven to be extremely efficient, but such methods require NP hard projections when dealing with overlapping groups. In this paper, we show that such NP-hard projections can not only be avoided by appealing to submodular optimization, but such methods come with strong theoretical guarantees even in the presence of poorly conditioned data (i.e. say when two features have correlation $\geq 0.99$), which existing analyses cannot handle. These methods exhibit an interesting computation-accuracy trade-off and can be extended to significantly harder problems such as sparse overlapping groups. Experiments on both real and synthetic data validate our claims and demonstrate that the proposed methods are orders of magnitude faster than other greedy and convex relaxation techniques for learning with group-structured sparsity.
High-dimensional Time Series Prediction with Missing Values
Feb 17, 2016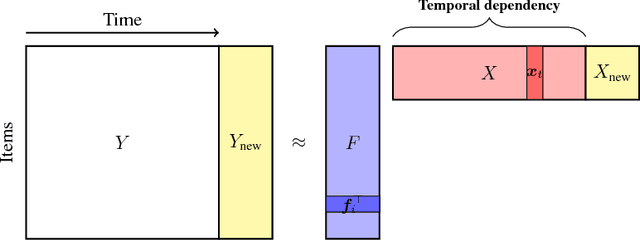
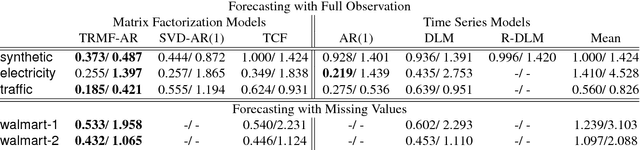
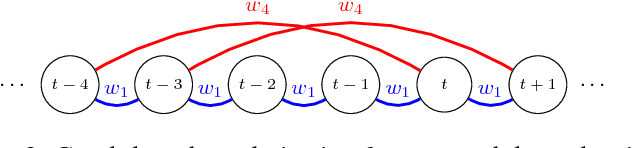
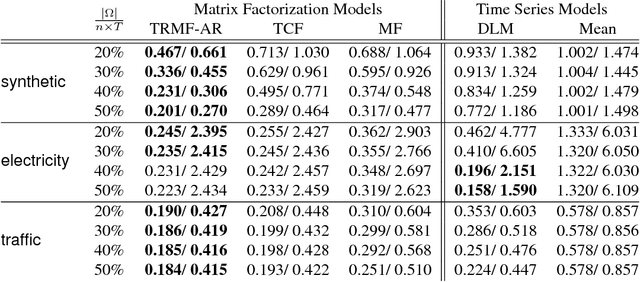
High-dimensional time series prediction is needed in applications as diverse as demand forecasting and climatology. Often, such applications require methods that are both highly scalable, and deal with noisy data in terms of corruptions or missing values. Classical time series methods usually fall short of handling both these issues. In this paper, we propose to adapt matrix matrix completion approaches that have previously been successfully applied to large scale noisy data, but which fail to adequately model high-dimensional time series due to temporal dependencies. We present a novel temporal regularized matrix factorization (TRMF) framework which supports data-driven temporal dependency learning and enables forecasting ability to our new matrix factorization approach. TRMF is highly general, and subsumes many existing matrix factorization approaches for time series data. We make interesting connections to graph regularized matrix factorization methods in the context of learning the dependencies. Experiments on both real and synthetic data show that TRMF outperforms several existing approaches for common time series tasks.
Forward - Backward Greedy Algorithms for Atomic Norm Regularization
Jul 23, 2015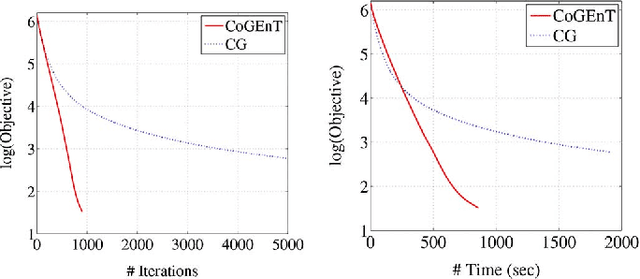
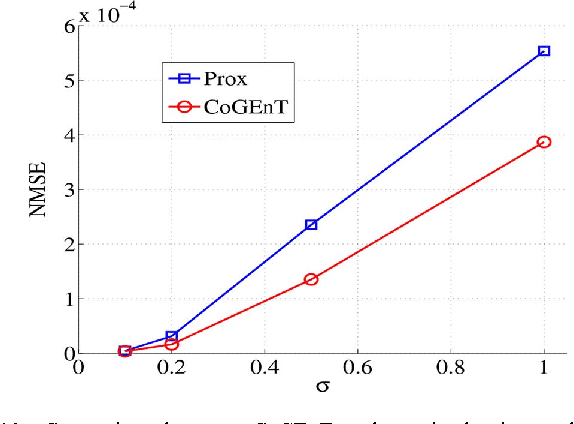
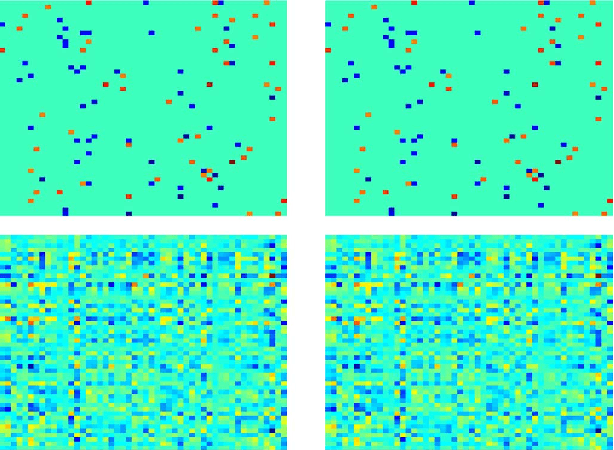
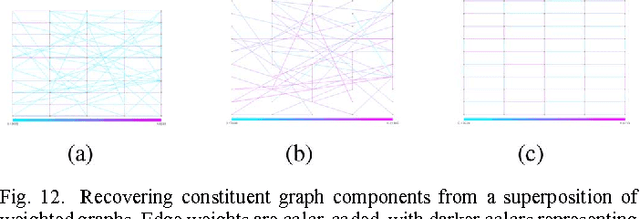
In many signal processing applications, the aim is to reconstruct a signal that has a simple representation with respect to a certain basis or frame. Fundamental elements of the basis known as "atoms" allow us to define "atomic norms" that can be used to formulate convex regularizations for the reconstruction problem. Efficient algorithms are available to solve these formulations in certain special cases, but an approach that works well for general atomic norms, both in terms of speed and reconstruction accuracy, remains to be found. This paper describes an optimization algorithm called CoGEnT that produces solutions with succinct atomic representations for reconstruction problems, generally formulated with atomic-norm constraints. CoGEnT combines a greedy selection scheme based on the conditional gradient approach with a backward (or "truncation") step that exploits the quadratic nature of the objective to reduce the basis size. We establish convergence properties and validate the algorithm via extensive numerical experiments on a suite of signal processing applications. Our algorithm and analysis also allow for inexact forward steps and for occasional enhancements of the current representation to be performed. CoGEnT can outperform the basic conditional gradient method, and indeed many methods that are tailored to specific applications, when the enhancement and truncation steps are defined appropriately. We also introduce several novel applications that are enabled by the atomic-norm framework, including tensor completion, moment problems in signal processing, and graph deconvolution.
Learning Single Index Models in High Dimensions
Jun 30, 2015


Single Index Models (SIMs) are simple yet flexible semi-parametric models for classification and regression. Response variables are modeled as a nonlinear, monotonic function of a linear combination of features. Estimation in this context requires learning both the feature weights, and the nonlinear function. While methods have been described to learn SIMs in the low dimensional regime, a method that can efficiently learn SIMs in high dimensions has not been forthcoming. We propose three variants of a computationally and statistically efficient algorithm for SIM inference in high dimensions. We establish excess risk bounds for the proposed algorithms and experimentally validate the advantages that our SIM learning methods provide relative to Generalized Linear Model (GLM) and low dimensional SIM based learning methods.
Optimal Low-Rank Tensor Recovery from Separable Measurements: Four Contractions Suffice
May 15, 2015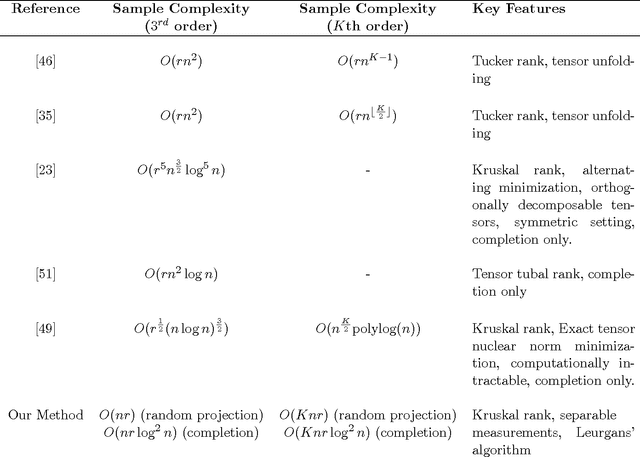
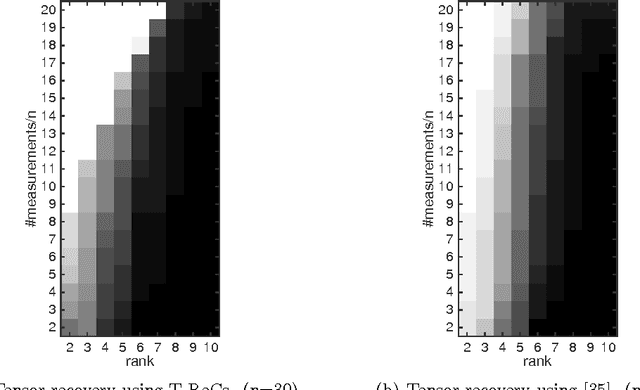
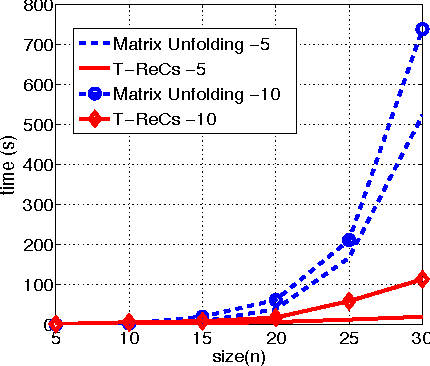
Tensors play a central role in many modern machine learning and signal processing applications. In such applications, the target tensor is usually of low rank, i.e., can be expressed as a sum of a small number of rank one tensors. This motivates us to consider the problem of low rank tensor recovery from a class of linear measurements called separable measurements. As specific examples, we focus on two distinct types of separable measurement mechanisms (a) Random projections, where each measurement corresponds to an inner product of the tensor with a suitable random tensor, and (b) the completion problem where measurements constitute revelation of a random set of entries. We present a computationally efficient algorithm, with rigorous and order-optimal sample complexity results (upto logarithmic factors) for tensor recovery. Our method is based on reduction to matrix completion sub-problems and adaptation of Leurgans' method for tensor decomposition. We extend the methodology and sample complexity results to higher order tensors, and experimentally validate our theoretical results.
Classification with Sparse Overlapping Groups
Sep 04, 2014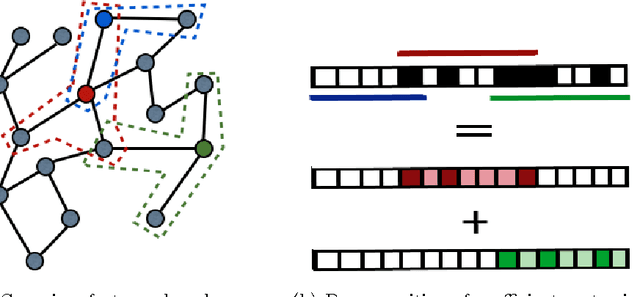

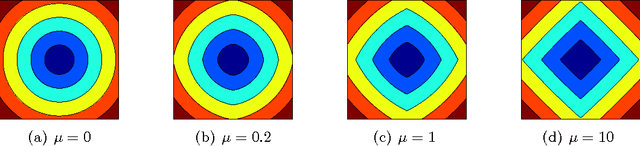
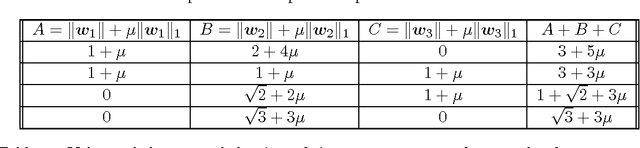
Classification with a sparsity constraint on the solution plays a central role in many high dimensional machine learning applications. In some cases, the features can be grouped together so that entire subsets of features can be selected or not selected. In many applications, however, this can be too restrictive. In this paper, we are interested in a less restrictive form of structured sparse feature selection: we assume that while features can be grouped according to some notion of similarity, not all features in a group need be selected for the task at hand. When the groups are comprised of disjoint sets of features, this is sometimes referred to as the "sparse group" lasso, and it allows for working with a richer class of models than traditional group lasso methods. Our framework generalizes conventional sparse group lasso further by allowing for overlapping groups, an additional flexiblity needed in many applications and one that presents further challenges. The main contribution of this paper is a new procedure called Sparse Overlapping Group (SOG) lasso, a convex optimization program that automatically selects similar features for classification in high dimensions. We establish model selection error bounds for SOGlasso classification problems under a fairly general setting. In particular, the error bounds are the first such results for classification using the sparse group lasso. Furthermore, the general SOGlasso bound specializes to results for the lasso and the group lasso, some known and some new. The SOGlasso is motivated by multi-subject fMRI studies in which functional activity is classified using brain voxels as features, source localization problems in Magnetoencephalography (MEG), and analyzing gene activation patterns in microarray data analysis. Experiments with real and synthetic data demonstrate the advantages of SOGlasso compared to the lasso and group lasso.