 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Curse of Recursion: Training on Generated Data Makes Models Forget
May 31, 2023



Stable Diffusion revolutionised image creation from descriptive text. GPT-2, GPT-3(.5) and GPT-4 demonstrated astonishing performance across a variety of language tasks. ChatGPT introduced such language models to the general public. It is now clear that large language models (LLMs) are here to stay, and will bring about drastic change in the whole ecosystem of online text and images. In this paper we consider what the future might hold. What will happen to GPT-{n} once LLMs contribute much of the language found online? We find that use of model-generated content in training causes irreversible defects in the resulting models, where tails of the original content distribution disappear. We refer to this effect as Model Collapse and show that it can occur in Variational Autoencoders, Gaussian Mixture Models and LLMs. We build theoretical intuition behind the phenomenon and portray its ubiquity amongst all learned generative models. We demonstrate that it has to be taken seriously if we are to sustain the benefits of training from large-scale data scraped from the web. Indeed, the value of data collected about genuine human interactions with systems will be increasingly valuable in the presence of content generated by LLMs in data crawled from the Internet.
Training Private Models That Know What They Don't Know
May 28, 2023Training reliable deep learning models which avoid making overconfident but incorrect predictions is a longstanding challenge. This challenge is further exacerbated when learning has to be differentially private: protection provided to sensitive data comes at the price of injecting additional randomness into the learning process. In this work, we conduct a thorough empirical investigation of selective classifiers -- that can abstain when they are unsure -- under a differential privacy constraint. We find that several popular selective prediction approaches are ineffective in a differentially private setting as they increase the risk of privacy leakage. At the same time, we identify that a recent approach that only uses checkpoints produced by an off-the-shelf private learning algorithm stands out as particularly suitable under DP. Further, we show that differential privacy does not just harm utility but also degrades selective classification performance. To analyze this effect across privacy levels, we propose a novel evaluation mechanism which isolate selective prediction performance across model utility levels. Our experimental results show that recovering the performance level attainable by non-private models is possible but comes at a considerable coverage cost as the privacy budget decreases.
Flocks of Stochastic Parrots: Differentially Private Prompt Learning for Large Language Models
May 24, 2023Large language models (LLMs) are excellent in-context learners. However, the sensitivity of data contained in prompts raises privacy concerns. Our work first shows that these concerns are valid: we instantiate a simple but highly effective membership inference attack against the data used to prompt LLMs. To address this vulnerability, one could forego prompting and resort to fine-tuning LLMs with known algorithms for private gradient descent. However, this comes at the expense of the practicality and efficiency offered by prompting. Therefore, we propose to privately learn to prompt. We first show that soft prompts can be obtained privately through gradient descent on downstream data. However, this is not the case for discrete prompts. Thus, we orchestrate a noisy vote among an ensemble of LLMs presented with different prompts, i.e., a flock of stochastic parrots. The vote privately transfers the flock's knowledge into a single public prompt. We show that LLMs prompted with our private algorithms closely match the non-private baselines. For example, using GPT3 as the base model, we achieve a downstream accuracy of 92.7% on the sst2 dataset with ($\epsilon=0.147, \delta=10^{-6}$)-differential privacy vs. 95.2% for the non-private baseline. Through our experiments, we also show that our prompt-based approach is easily deployed with existing commercial APIs.
Have it your way: Individualized Privacy Assignment for DP-SGD
Mar 29, 2023When training a machine learning model with differential privacy, one sets a privacy budget. This budget represents a maximal privacy violation that any user is willing to face by contributing their data to the training set. We argue that this approach is limited because different users may have different privacy expectations. Thus, setting a uniform privacy budget across all points may be overly conservative for some users or, conversely, not sufficiently protective for others. In this paper, we capture these preferences through individualized privacy budgets. To demonstrate their practicality, we introduce a variant of Differentially Private Stochastic Gradient Descent (DP-SGD) which supports such individualized budgets. DP-SGD is the canonical approach to training models with differential privacy. We modify its data sampling and gradient noising mechanisms to arrive at our approach, which we call Individualized DP-SGD (IDP-SGD). Because IDP-SGD provides privacy guarantees tailored to the preferences of individual users and their data points, we find it empirically improves privacy-utility trade-offs.
Learning with Impartiality to Walk on the Pareto Frontier of Fairness, Privacy, and Utility
Feb 17, 2023



Deploying machine learning (ML) models often requires both fairness and privacy guarantees. Both of these objectives present unique trade-offs with the utility (e.g., accuracy) of the model. However, the mutual interactions between fairness, privacy, and utility are less well-understood. As a result, often only one objective is optimized, while the others are tuned as hyper-parameters. Because they implicitly prioritize certain objectives, such designs bias the model in pernicious, undetectable ways. To address this, we adopt impartiality as a principle: design of ML pipelines should not favor one objective over another. We propose impartially-specified models, which provide us with accurate Pareto frontiers that show the inherent trade-offs between the objectives. Extending two canonical ML frameworks for privacy-preserving learning, we provide two methods (FairDP-SGD and FairPATE) to train impartially-specified models and recover the Pareto frontier. Through theoretical privacy analysis and a comprehensive empirical study, we provide an answer to the question of where fairness mitigation should be integrated within a privacy-aware ML pipeline.
Learned Systems Security
Jan 10, 2023



A learned system uses machine learning (ML) internally to improve performance. We can expect such systems to be vulnerable to some adversarial-ML attacks. Often, the learned component is shared between mutually-distrusting users or processes, much like microarchitectural resources such as caches, potentially giving rise to highly-realistic attacker models. However, compared to attacks on other ML-based systems, attackers face a level of indirection as they cannot interact directly with the learned model. Additionally, the difference between the attack surface of learned and non-learned versions of the same system is often subtle. These factors obfuscate the de-facto risks that the incorporation of ML carries. We analyze the root causes of potentially-increased attack surface in learned systems and develop a framework for identifying vulnerabilities that stem from the use of ML. We apply our framework to a broad set of learned systems under active development. To empirically validate the many vulnerabilities surfaced by our framework, we choose 3 of them and implement and evaluate exploits against prominent learned-system instances. We show that the use of ML caused leakage of past queries in a database, enabled a poisoning attack that causes exponential memory blowup in an index structure and crashes it in seconds, and enabled index users to snoop on each others' key distributions by timing queries over their own keys. We find that adversarial ML is a universal threat against learned systems, point to open research gaps in our understanding of learned-systems security, and conclude by discussing mitigations, while noting that data leakage is inherent in systems whose learned component is shared between multiple parties.
Is Federated Learning a Practical PET Yet?
Jan 09, 2023



Federated learning (FL) is a framework for users to jointly train a machine learning model. FL is promoted as a privacy-enhancing technology (PET) that provides data minimization: data never "leaves" personal devices and users share only model updates with a server (e.g., a company) coordinating the distributed training. We assess the realistic (i.e., worst-case) privacy guarantees that are provided to users who are unable to trust the server. To this end, we propose an attack against FL protected with distributed differential privacy (DDP) and secure aggregation (SA). The attack method is based on the introduction of Sybil devices that deviate from the protocol to expose individual users' data for reconstruction by the server. The underlying root cause for the vulnerability to our attack is the power imbalance. The server orchestrates the whole protocol and users are given little guarantees about the selection of other users participating in the protocol. Moving forward, we discuss requirements for an FL protocol to guarantee DDP without asking users to trust the server. We conclude that such systems are not yet practical.
Private Multi-Winner Voting for Machine Learning
Nov 23, 2022



Private multi-winner voting is the task of revealing $k$-hot binary vectors satisfying a bounded differential privacy (DP) guarantee. This task has been understudied in machine learning literature despite its prevalence in many domains such as healthcare. We propose three new DP multi-winner mechanisms: Binary, $\tau$, and Powerset voting. Binary voting operates independently per label through composition. $\tau$ voting bounds votes optimally in their $\ell_2$ norm for tight data-independent guarantees. Powerset voting operates over the entire binary vector by viewing the possible outcomes as a power set. Our theoretical and empirical analysis shows that Binary voting can be a competitive mechanism on many tasks unless there are strong correlations between labels, in which case Powerset voting outperforms it. We use our mechanisms to enable privacy-preserving multi-label learning in the central setting by extending the canonical single-label technique: PATE. We find that our techniques outperform current state-of-the-art approaches on large, real-world healthcare data and standard multi-label benchmarks. We further enable multi-label confidential and private collaborative (CaPC) learning and show that model performance can be significantly improved in the multi-site setting.
Verifiable and Provably Secure Machine Unlearning
Oct 17, 2022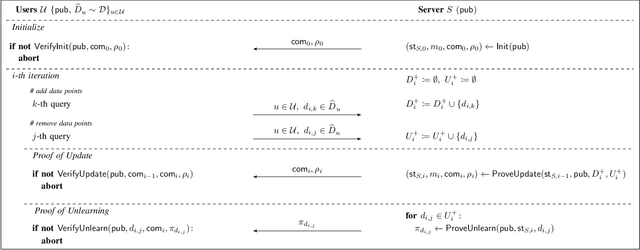



Machine unlearning aims to remove points from the training dataset of a machine learning model after training; for example when a user requests their data to be deleted. While many machine unlearning methods have been proposed, none of them enable users to audit the unlearning procedure and verify that their data was indeed unlearned. To address this, we define the first cryptographic framework to formally capture the security of verifiable machine unlearning. While our framework is generally applicable to different approaches, its advantages are perhaps best illustrated by our instantiation for the canonical approach to unlearning: retraining the model without the data to be unlearned. In our cryptographic protocol, the server first computes a proof that the model was trained on a dataset~$D$. Given a user data point $d$, the server then computes a proof of unlearning that shows that $d \notin D$. We realize our protocol using a SNARK and Merkle trees to obtain proofs of update and unlearning on the data. Based on cryptographic assumptions, we then present a formal game-based proof that our instantiation is secure. Finally, we validate the practicality of our constructions for unlearning in linear regression, logistic regression, and neural networks.
Fine-Tuning with Differential Privacy Necessitates an Additional Hyperparameter Search
Oct 05, 2022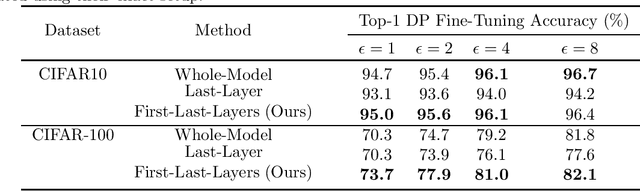
Models need to be trained with privacy-preserving learning algorithms to prevent leakage of possibly sensitive information contained in their training data. However, canonical algorithms like differentially private stochastic gradient descent (DP-SGD) do not benefit from model scale in the same way as non-private learning. This manifests itself in the form of unappealing tradeoffs between privacy and utility (accuracy) when using DP-SGD on complex tasks. To remediate this tension, a paradigm is emerging: fine-tuning with differential privacy from a model pretrained on public (i.e., non-sensitive) training data. In this work, we identify an oversight of existing approaches for differentially private fine tuning. They do not tailor the fine-tuning approach to the specifics of learning with privacy. Our main result is to show how carefully selecting the layers being fine-tuned in the pretrained neural network allows us to establish new state-of-the-art tradeoffs between privacy and accuracy. For instance, we achieve 77.9% accuracy for $(\varepsilon, \delta)=(2, 10^{-5})$ on CIFAR-100 for a model pretrained on ImageNet. Our work calls for additional hyperparameter search to configure the differentially private fine-tuning procedure itself.