 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetric Learning-enhanced Optimal Transport for Biochemical Regression Domain Adaptation
Feb 16, 2022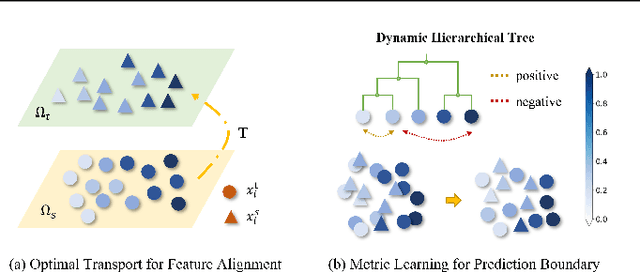
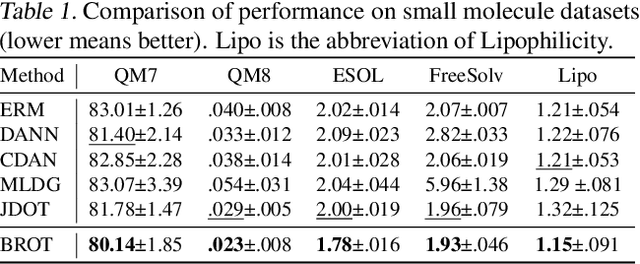
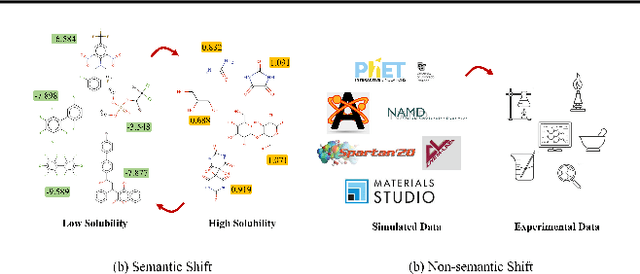
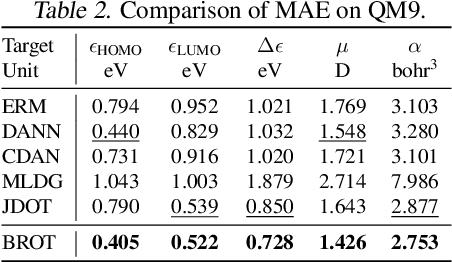
Generalizing knowledge beyond source domains is a crucial prerequisite for many biomedical applications such as drug design and molecular property prediction. To meet this challenge, researchers have used optimal transport (OT) to perform representation alignment between the source and target domains. Yet existing OT algorithms are mainly designed for classification tasks. Accordingly, we consider regression tasks in the unsupervised and semi-supervised settings in this paper. To exploit continuous labels, we propose novel metrics to measure domain distances and introduce a posterior variance regularizer on the transport plan. Further, while computationally appealing, OT suffers from ambiguous decision boundaries and biased local data distributions brought by the mini-batch training. To address those issues, we propose to couple OT with metric learning to yield more robust boundaries and reduce bias. Specifically, we present a dynamic hierarchical triplet loss to describe the global data distribution, where the cluster centroids are progressively adjusted among consecutive iterations. We evaluate our method on both unsupervised and semi-supervised learning tasks in biochemistry. Experiments show the proposed method significantly outperforms state-of-the-art baselines across various benchmark datasets of small molecules and material crystals.
Sliced-Wasserstein Gradient Flows
Oct 21, 2021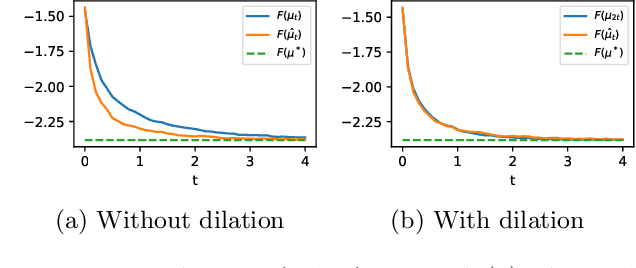
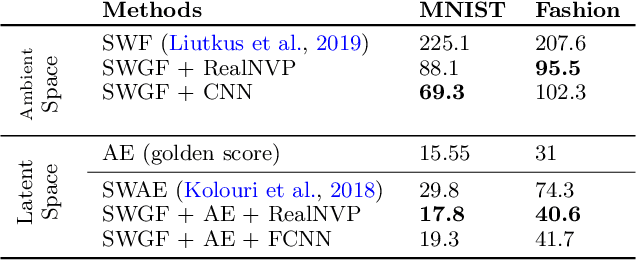

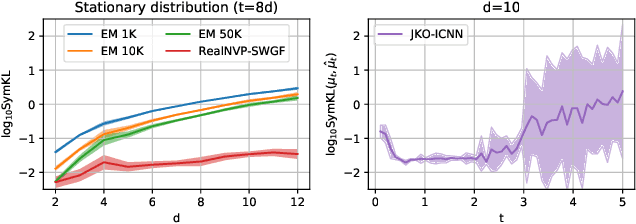
Minimizing functionals in the space of probability distributions can be done with Wasserstein gradient flows. To solve them numerically, a possible approach is to rely on the Jordan-Kinderlehrer-Otto (JKO) scheme which is analogous to the proximal scheme in Euclidean spaces. However, this bilevel optimization problem is known for its computational challenges, especially in high dimension. To alleviate it, very recent works propose to approximate the JKO scheme leveraging Brenier's theorem, and using gradients of Input Convex Neural Networks to parameterize the density (JKO-ICNN). However, this method comes with a high computational cost and stability issues. Instead, this work proposes to use gradient flows in the space of probability measures endowed with the sliced-Wasserstein (SW) distance. We argue that this method is more flexible than JKO-ICNN, since SW enjoys a closed-form differentiable approximation. Thus, the density at each step can be parameterized by any generative model which alleviates the computational burden and makes it tractable in higher dimensions. Interestingly, we also show empirically that these gradient flows are strongly related to the usual Wasserstein gradient flows, and that they can be used to minimize efficiently diverse machine learning functionals.
Subspace Detours Meet Gromov-Wasserstein
Oct 21, 2021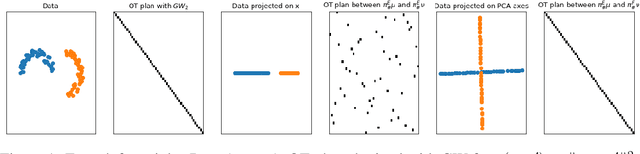
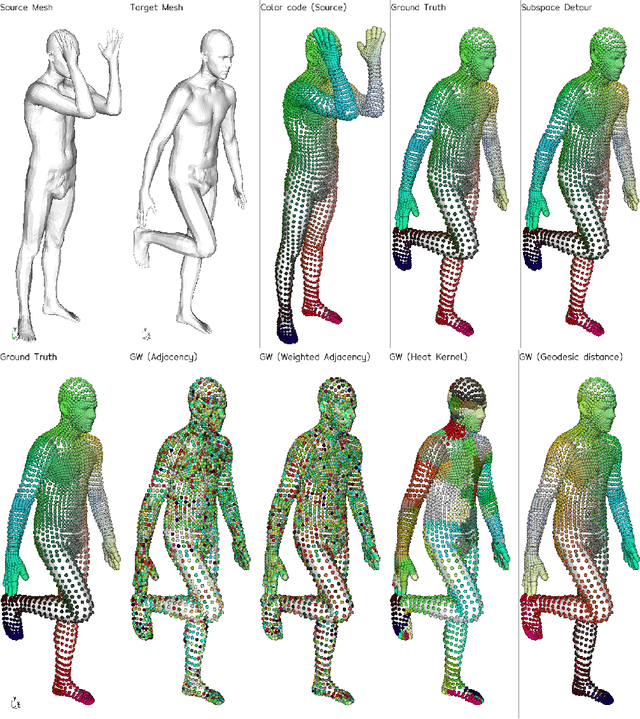
In the context of optimal transport methods, the subspace detour approach was recently presented by Muzellec and Cuturi (2019). It consists in building a nearly optimal transport plan in the measures space from an optimal transport plan in a wisely chosen subspace, onto which the original measures are projected. The contribution of this paper is to extend this category of methods to the Gromov-Wasserstein problem, which is a particular type of transport distance involving the inner geometry of the compared distributions. After deriving the associated formalism and properties, we also discuss a specific cost for which we can show connections with the Knothe-Rosenblatt rearrangement. We finally give an experimental illustration on a shape matching problem.
Factored couplings in multi-marginal optimal transport via difference of convex programming
Oct 18, 2021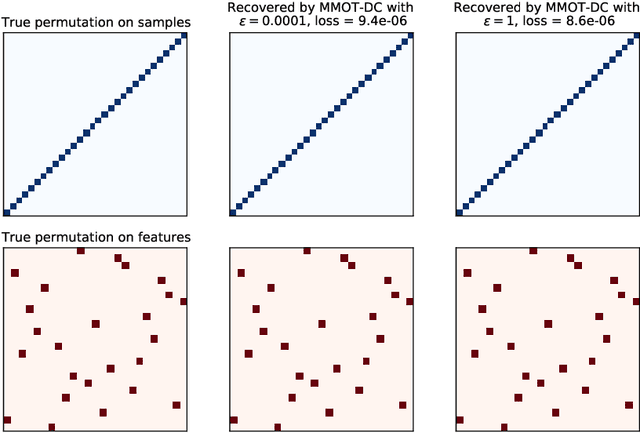
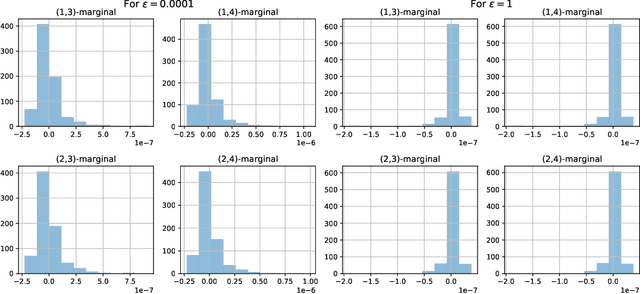
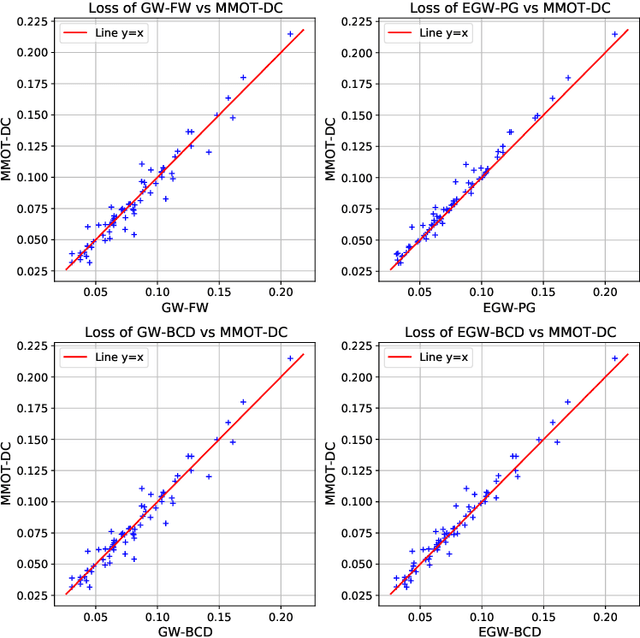
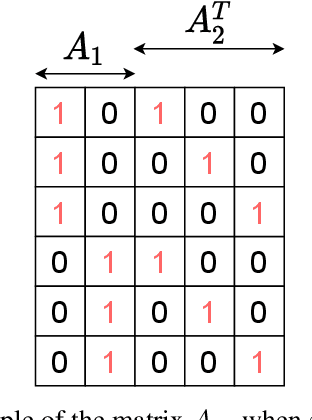
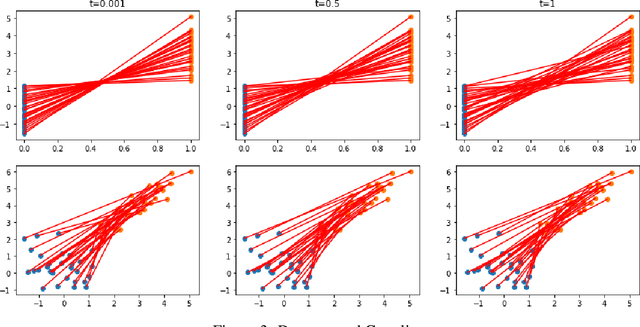
Optimal transport (OT) theory underlies many emerging machine learning (ML) methods nowadays solving a wide range of tasks such as generative modeling, transfer learning and information retrieval. These latter works, however, usually build upon a traditional OT setup with two distributions, while leaving a more general multi-marginal OT formulation somewhat unexplored. In this paper, we study the multi-marginal OT (MMOT) problem and unify several popular OT methods under its umbrella by promoting structural information on the coupling. We show that incorporating such structural information into MMOT results in an instance of a different of convex (DC) programming problem allowing us to solve it numerically. Despite high computational cost of the latter procedure, the solutions provided by DC optimization are usually as qualitative as those obtained using currently employed optimization schemes.
Semi-relaxed Gromov Wasserstein divergence with applications on graphs
Oct 06, 2021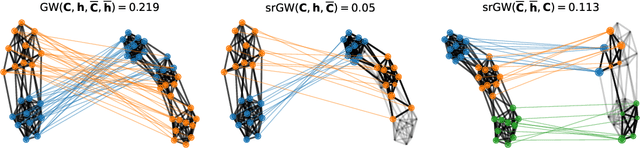
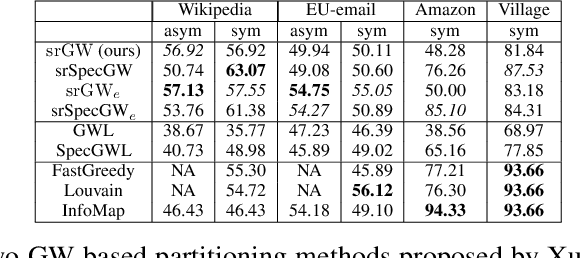
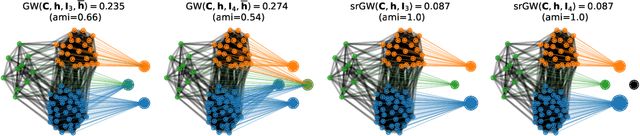
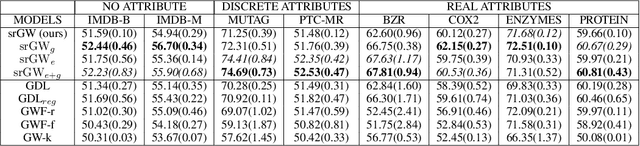
Comparing structured objects such as graphs is a fundamental operation involved in many learning tasks. To this end, the Gromov-Wasserstein (GW) distance, based on Optimal Transport (OT), has proven to be successful in handling the specific nature of the associated objects. More specifically, through the nodes connectivity relations, GW operates on graphs, seen as probability measures over specific spaces. At the core of OT is the idea of conservation of mass, which imposes a coupling between all the nodes from the two considered graphs. We argue in this paper that this property can be detrimental for tasks such as graph dictionary or partition learning, and we relax it by proposing a new semi-relaxed Gromov-Wasserstein divergence. Aside from immediate computational benefits, we discuss its properties, and show that it can lead to an efficient graph dictionary learning algorithm. We empirically demonstrate its relevance for complex tasks on graphs such as partitioning, clustering and completion.
Unbalanced minibatch Optimal Transport; applications to Domain Adaptation
Mar 05, 2021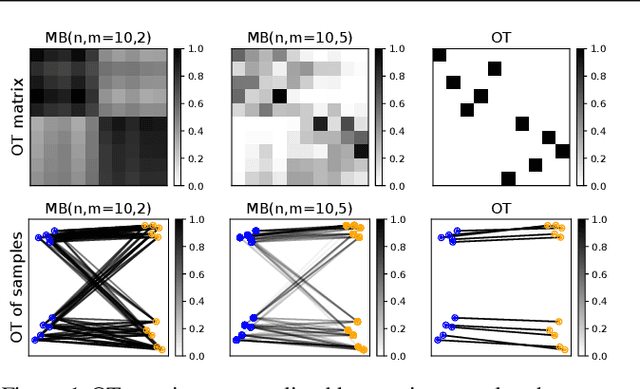
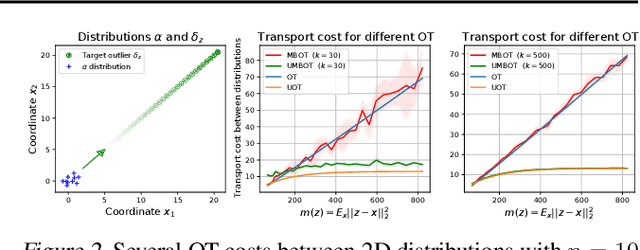

Optimal transport distances have found many applications in machine learning for their capacity to compare non-parametric probability distributions. Yet their algorithmic complexity generally prevents their direct use on large scale datasets. Among the possible strategies to alleviate this issue, practitioners can rely on computing estimates of these distances over subsets of data, {\em i.e.} minibatches. While computationally appealing, we highlight in this paper some limits of this strategy, arguing it can lead to undesirable smoothing effects. As an alternative, we suggest that the same minibatch strategy coupled with unbalanced optimal transport can yield more robust behavior. We discuss the associated theoretical properties, such as unbiased estimators, existence of gradients and concentration bounds. Our experimental study shows that in challenging problems associated to domain adaptation, the use of unbalanced optimal transport leads to significantly better results, competing with or surpassing recent baselines.
Learning to Generate Wasserstein Barycenters
Feb 24, 2021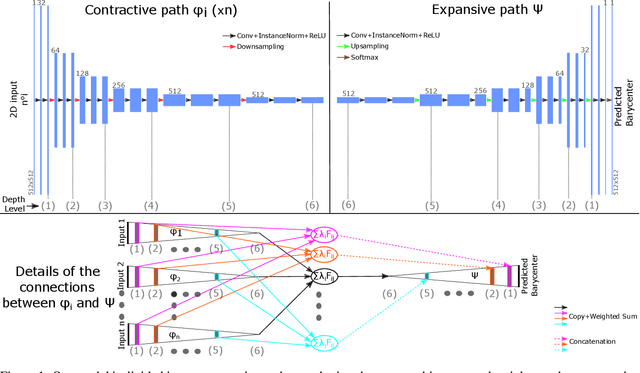

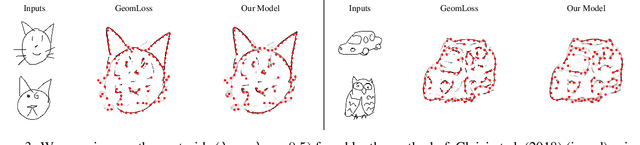
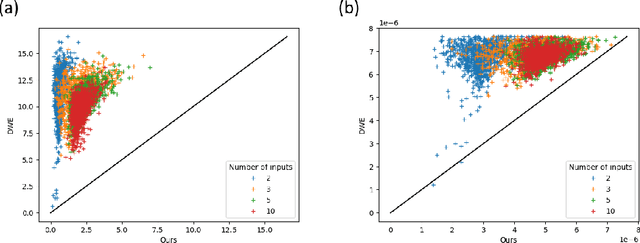
Optimal transport is a notoriously difficult problem to solve numerically, with current approaches often remaining intractable for very large scale applications such as those encountered in machine learning. Wasserstein barycenters -- the problem of finding measures in-between given input measures in the optimal transport sense -- is even more computationally demanding as it requires to solve an optimization problem involving optimal transport distances. By training a deep convolutional neural network, we improve by a factor of 60 the computational speed of Wasserstein barycenters over the fastest state-of-the-art approach on the GPU, resulting in milliseconds computational times on $512\times512$ regular grids. We show that our network, trained on Wasserstein barycenters of pairs of measures, generalizes well to the problem of finding Wasserstein barycenters of more than two measures. We demonstrate the efficiency of our approach for computing barycenters of sketches and transferring colors between multiple images.
Online Graph Dictionary Learning
Feb 12, 2021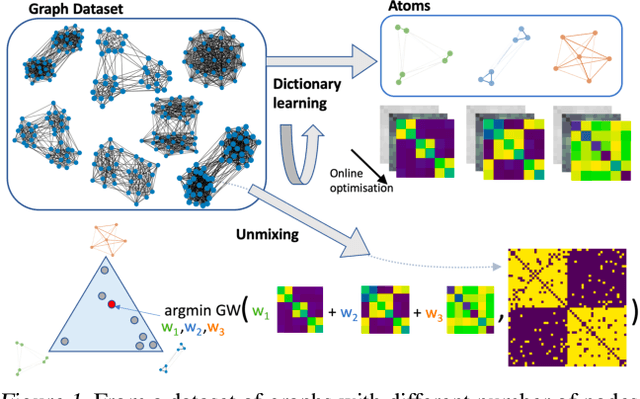

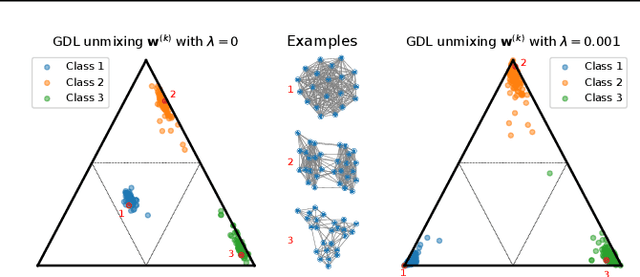
Dictionary learning is a key tool for representation learning, that explains the data as linear combination of few basic elements. Yet, this analysis is not amenable in the context of graph learning, as graphs usually belong to different metric spaces. We fill this gap by proposing a new online Graph Dictionary Learning approach, which uses the Gromov Wasserstein divergence for the data fitting term. In our work, graphs are encoded through their nodes' pairwise relations and modeled as convex combination of graph atoms, i.e. dictionary elements, estimated thanks to an online stochastic algorithm, which operates on a dataset of unregistered graphs with potentially different number of nodes. Our approach naturally extends to labeled graphs, and is completed by a novel upper bound that can be used as a fast approximation of Gromov Wasserstein in the embedding space. We provide numerical evidences showing the interest of our approach for unsupervised embedding of graph datasets and for online graph subspace estimation and tracking.
Minibatch optimal transport distances; analysis and applications
Jan 05, 2021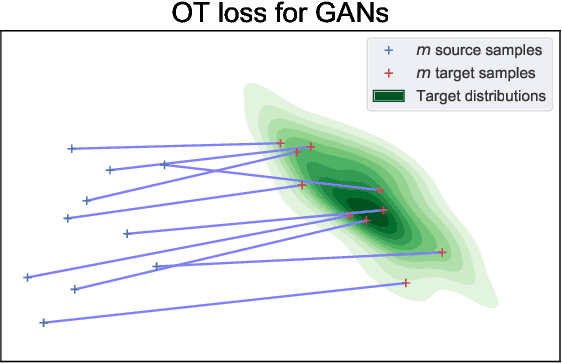

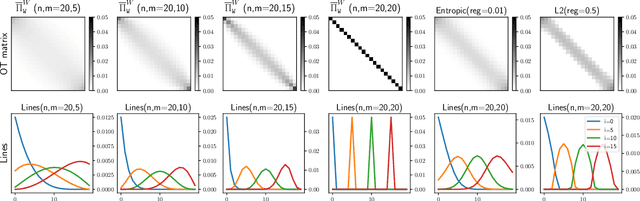

Optimal transport distances have become a classic tool to compare probability distributions and have found many applications in machine learning. Yet, despite recent algorithmic developments, their complexity prevents their direct use on large scale datasets. To overcome this challenge, a common workaround is to compute these distances on minibatches i.e. to average the outcome of several smaller optimal transport problems. We propose in this paper an extended analysis of this practice, which effects were previously studied in restricted cases. We first consider a large variety of Optimal Transport kernels. We notably argue that the minibatch strategy comes with appealing properties such as unbiased estimators, gradients and a concentration bound around the expectation, but also with limits: the minibatch OT is not a distance. To recover some of the lost distance axioms, we introduce a debiased minibatch OT function and study its statistical and optimisation properties. Along with this theoretical analysis, we also conduct empirical experiments on gradient flows, generative adversarial networks (GANs) or color transfer that highlight the practical interest of this strategy.
Contextual Semantic Interpretability
Sep 18, 2020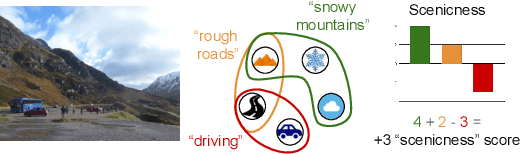
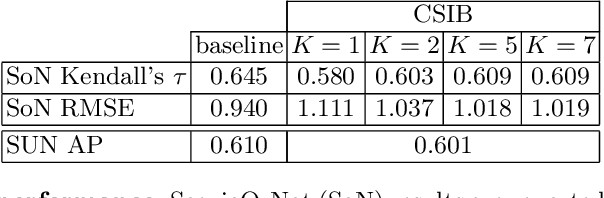
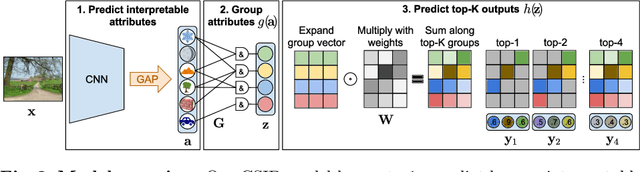
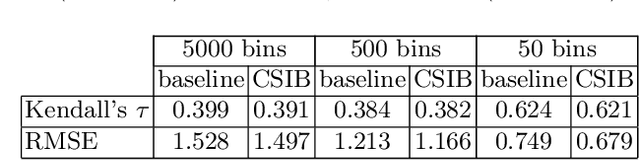
Convolutional neural networks (CNN) are known to learn an image representation that captures concepts relevant to the task, but do so in an implicit way that hampers model interpretability. However, one could argue that such a representation is hidden in the neurons and can be made explicit by teaching the model to recognize semantically interpretable attributes that are present in the scene. We call such an intermediate layer a \emph{semantic bottleneck}. Once the attributes are learned, they can be re-combined to reach the final decision and provide both an accurate prediction and an explicit reasoning behind the CNN decision. In this paper, we look into semantic bottlenecks that capture context: we want attributes to be in groups of a few meaningful elements and participate jointly to the final decision. We use a two-layer semantic bottleneck that gathers attributes into interpretable, sparse groups, allowing them contribute differently to the final output depending on the context. We test our contextual semantic interpretable bottleneck (CSIB) on the task of landscape scenicness estimation and train the semantic interpretable bottleneck using an auxiliary database (SUN Attributes). Our model yields in predictions as accurate as a non-interpretable baseline when applied to a real-world test set of Flickr images, all while providing clear and interpretable explanations for each prediction.