 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoE Routing Testbed: Studying Expert Specialization and Routing Behavior at Small Scale
Apr 08, 2026Sparse Mixture-of-Experts (MoE) architectures are increasingly popular for frontier large language models (LLM) but they introduce training challenges due to routing complexity. Fully leveraging parameters of an MoE model requires all experts to be well-trained and to specialize in non-redundant ways. Assessing this, however, is complicated due to lack of established metrics and, importantly, many routing techniques exhibit similar performance at smaller sizes, which is often not reflective of their behavior at large scale. To address this challenge, we propose the MoE Routing Testbed, a setup that gives clearer visibility into routing dynamics at small scale while using realistic data. The testbed pairs a data mix with clearly distinguishable domains with a reference router that prescribes ideal routing based on these domains, providing a well-defined upper bound for comparison. This enables quantifiable measurement of expert specialization. To demonstrate the value of the testbed, we compare various MoE routing approaches and show that balancing scope is the crucial factor that allows specialization while maintaining high expert utilization. We confirm that this observation generalizes to models 35x larger.
Cooperation and Reputation Dynamics with Reinforcement Learning
Feb 15, 2021
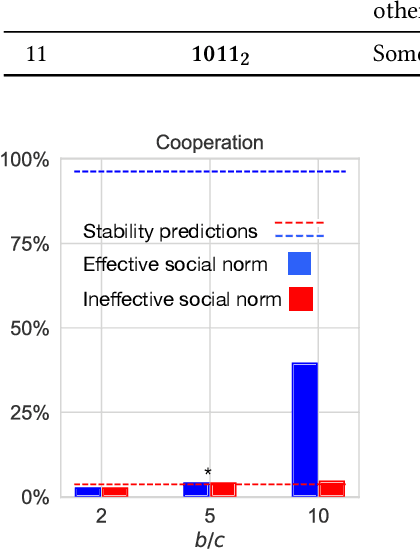

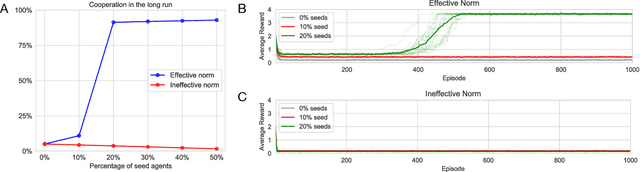
Creating incentives for cooperation is a challenge in natural and artificial systems. One potential answer is reputation, whereby agents trade the immediate cost of cooperation for the future benefits of having a good reputation. Game theoretical models have shown that specific social norms can make cooperation stable, but how agents can independently learn to establish effective reputation mechanisms on their own is less understood. We use a simple model of reinforcement learning to show that reputation mechanisms generate two coordination problems: agents need to learn how to coordinate on the meaning of existing reputations and collectively agree on a social norm to assign reputations to others based on their behavior. These coordination problems exhibit multiple equilibria, some of which effectively establish cooperation. When we train agents with a standard Q-learning algorithm in an environment with the presence of reputation mechanisms, convergence to undesirable equilibria is widespread. We propose two mechanisms to alleviate this: (i) seeding a proportion of the system with fixed agents that steer others towards good equilibria; and (ii), intrinsic rewards based on the idea of introspection, i.e., augmenting agents' rewards by an amount proportionate to the performance of their own strategy against themselves. A combination of these simple mechanisms is successful in stabilizing cooperation, even in a fully decentralized version of the problem where agents learn to use and assign reputations simultaneously. We show how our results relate to the literature in Evolutionary Game Theory, and discuss implications for artificial, human and hybrid systems, where reputations can be used as a way to establish trust and cooperation.
Understanding The Impact of Partner Choice on Cooperation and Social Norms by means of Multi-agent Reinforcement Learning
Feb 13, 2019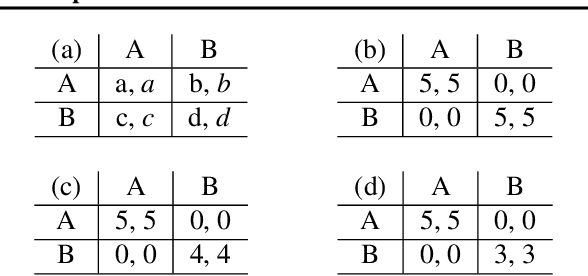
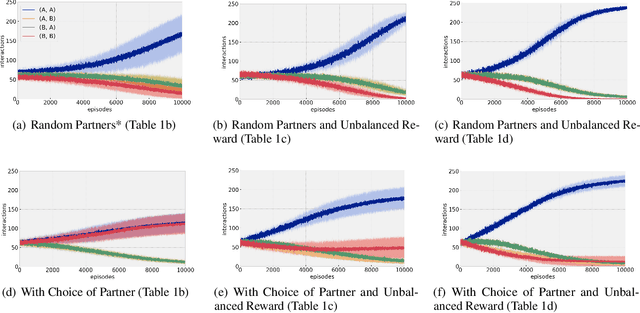
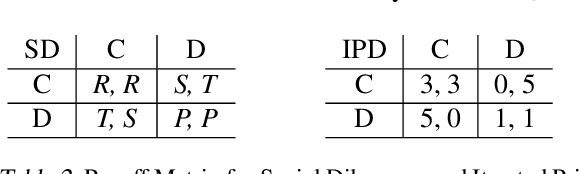
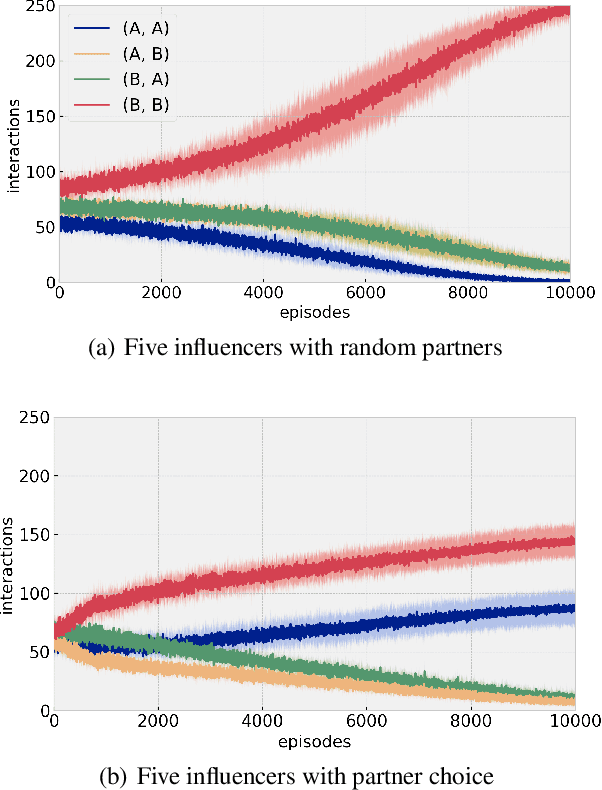
The human ability to coordinate and cooperate has been vital to the development of societies for thousands of years. While it is not fully clear how this behavior arises, social norms are thought to be a key factor in this development. In contrast to laws set by authorities, norms tend to evolve in a bottom-up manner from interactions between members of a society. While much behavior can be explained through the use of social norms, it is difficult to measure the extent to which they shape society as well as how they are affected by other societal dynamics. In this paper, we discuss the design and evaluation of a reinforcement learning model for understanding how the opportunity to choose who you interact with in a society affects the overall societal outcome and the strength of social norms. We first study the emergence of norms and then the emergence of cooperation in presence of norms. In our model, agents interact with other agents in a society in the form of repeated matrix-games: coordination games and cooperation games. In particular, in our model, at each each stage, agents are either able to choose a partner to interact with or are forced to interact at random and learn using policy gradients.
Learning through Probing: a decentralized reinforcement learning architecture for social dilemmas
Sep 26, 2018
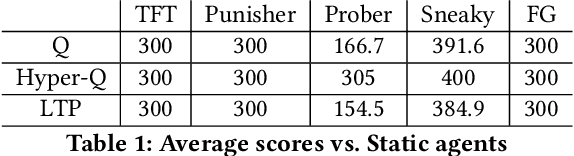

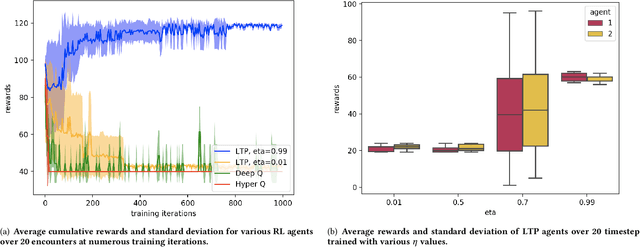
Multi-agent reinforcement learning has received significant interest in recent years notably due to the advancements made in deep reinforcement learning which have allowed for the developments of new architectures and learning algorithms. Using social dilemmas as the training ground, we present a novel learning architecture, Learning through Probing (LTP), where agents utilize a probing mechanism to incorporate how their opponent's behavior changes when an agent takes an action. We use distinct training phases and adjust rewards according to the overall outcome of the experiences accounting for changes to the opponents behavior. We introduce a parameter eta to determine the significance of these future changes to opponent behavior. When applied to the Iterated Prisoner's Dilemma (IPD), LTP agents demonstrate that they can learn to cooperate with each other, achieving higher average cumulative rewards than other reinforcement learning methods while also maintaining good performance in playing against static agents that are present in Axelrod tournaments. We compare this method with traditional reinforcement learning algorithms and agent-tracking techniques to highlight key differences and potential applications. We also draw attention to the differences between solving games and societal-like interactions and analyze the training of Q-learning agents in makeshift societies. This is to emphasize how cooperation may emerge in societies and demonstrate this using environments where interactions with opponents are determined through a random encounter format of the IPD.
Bayesian Inference with Anchored Ensembles of Neural Networks, and Application to Exploration in Reinforcement Learning
Jul 02, 2018
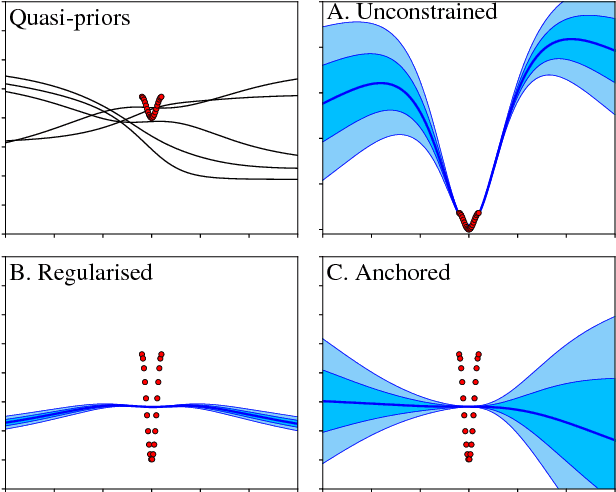
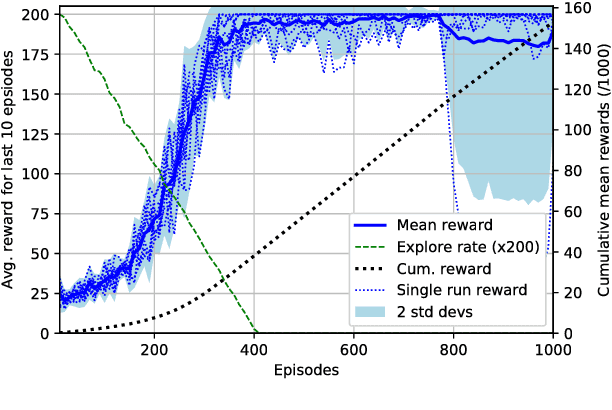
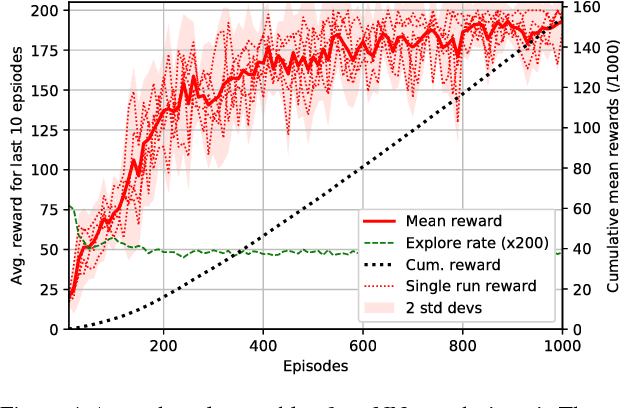
The use of ensembles of neural networks (NNs) for the quantification of predictive uncertainty is widespread. However, the current justification is intuitive rather than analytical. This work proposes one minor modification to the normal ensembling methodology, which we prove allows the ensemble to perform Bayesian inference, hence converging to the corresponding Gaussian Process as both the total number of NNs, and the size of each, tend to infinity. This working paper provides early-stage results in a reinforcement learning setting, analysing the practicality of the technique for an ensemble of small, finite number. Using the uncertainty estimates produced by anchored ensembles to govern the exploration-exploitation process results in steadier, more stable learning.